R数据分析:二分类因变量的混合效应,多水平logistics模型介绍 |
您所在的位置:网站首页 › 混合效应模型和混合线性模型一样吗 › R数据分析:二分类因变量的混合效应,多水平logistics模型介绍 |
R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
|
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法: Mixed Effects Logistic Regression is sometimes also called Repeated Measures Logistic Regression, Multilevel Logistic Regression and Multilevel Binary Logistic Regression . 之后如果你遇到重复测量logistics回归,多水平logistics回归,你就应该知道他们都是指的是混合效应logistics回归模型这一个东西。 模型介绍重复测量和嵌套数据是科研中很常见的,此时需要考虑多水平模型来更好地分解变异,因变量是二分类变量的时候我们会用logistics回归,多水平模型和logistics模型两个一结合就是非常经典的广义线性混合模型之一-----------多水平logistics回归。 就是这么简单。 为了更好地帮助大家理解,我们先回顾一下混合效应的一般写法,以随机截距为例子,当我们的因变量是连续的,此时我们可以做混合效应模型,比如我们的随机截距混合效应模型就是如下,其中uj就叫做随机截距(去翻翻之前的文章哈):
再扩展一下,当我们的因变量Y不是正态分布的时候,我们就有广义线性随机效应模型如下:
多了一个链接函数link funtion,其余都一样的。这个链接函数可以是logit,可以是probit等等。 那么具体到因变量是二分类的时候我们就要用logit链接函数了。
此时我们的混合logistics模型的图示如下:
左上角就是大家都知道的logistics回归模型,右上角是随机截距logistics模型,左下角是随机斜率logistics回归模型,右下角就是既有随机截距又有随机斜率的logistics模型啦,和之前给大家写的线性混合模型一模一样的。 然后对于这么一个随机截距模型,我们有固定效应部分的系数如下表:
其中β0就是截距,是x取0的时候y取1的log-odds(看不明白log-odds的同学去瞅瞅logistics机器学习的文章哈),β1是在控制了其余变量的情况下x每增长一个单位,log-odds的增长量;我们要报告的expβ1,这个就是odds ratio,就是论文中常见的风险相对于参考组增加多少多少倍的意思。 我们还有随机效应部分的系数:
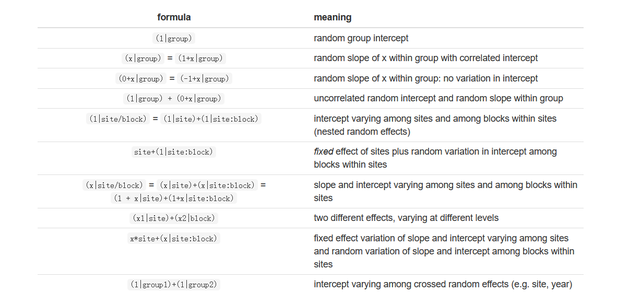
此部分就体现出来整个模型的变异分解,Uj就是组(嵌套的高水平)j对log-odds的作用,这就体现了嵌套数据的影响。这个uj也是服从正态分布的,标准差σ就是组水平上的效应扰动。 模型设定在R语言中具体的随机效应的设定,请大家参考下表(建议大家收藏起来,自己试试哈):
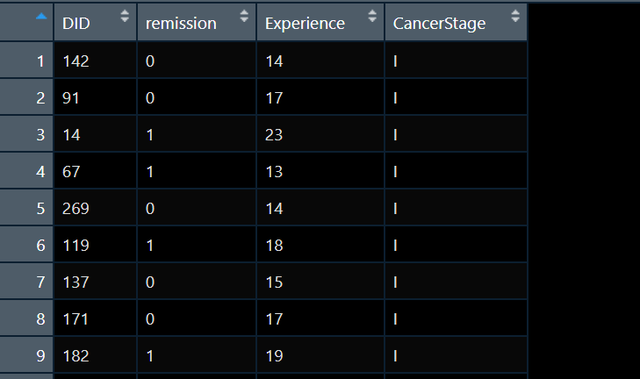
依然是给大家写一个例子: 实例解析首先还是先介绍一下手上的数据,一个医院不同医生接诊的肺癌患者的数据库,很明显我们知道,病人是嵌套在医生水平的,我现在感兴趣病人病情恢复情况remission的相关因素,包括病人的特征和医生的特征: 数据大概长这样:
超级简单的一个示例数据哈,其中DID是医生编号,Experience是医生的经验,我现在简单的认为,医生经验和病人病情都会对恢复结局产生影响,我就想跑跑回归看看结果,考虑到数据的嵌套特性我得使用多水平模型,remission是一个二分类变量,于是我们得考虑用多水平的logistics模型。 拟合模型的代码如下: m_ri |


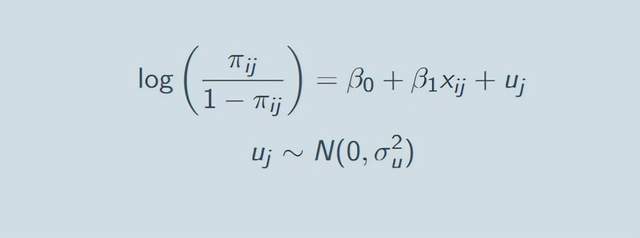




【本文地址】
今日新闻 |
推荐新闻 |