决策树算法中基尼指数与信息增益的比较 |
您所在的位置:网站首页 › 决策树算法计算怎么对比 › 决策树算法中基尼指数与信息增益的比较 |
决策树算法中基尼指数与信息增益的比较
|
问题提出
在自己实现决策树算法的时候,发现生成的id3树和cart树一模一样。竟然每个决策节点都选择了同一属性的同一划分。这让我很意外,于是改变了随机种子值,改变训练集的大小,结果发现无一例外它们都是一样的。由此我提出了一个疑问:基尼指数和信息增益是等价的吗? 如果等价,那干嘛还要两个算法?如果不等价,为什么生成的树总是一样的呢? 二者比较直接取iris数据集中的一部分作为训练集,并指定一个属性作为判断标准。列出一系列对该属性的划分,同时用基尼指数和信息增益作为判断标准进行评价,以此比较两者的区别(此例中训练集大小为100个样本,对0号属性“sepal length”进行划分) 经过不断地试探,我找到了一组合适的反例: 属性值4.45.05.15.16.06.06.16.16.16.36.36.46.56.86.87.7类别0100211122222222记原始数据集 D D\, D的信息熵为 E 0 E_{0} E0 现在考虑两个划分: D v 1 Dv_{1} Dv1 :属性值 ≤ 5.55 \le 5.55 ≤5.55和 ; 5.55 \gt 5.55 >5.55,相应的信息增益记为 E 1 E_{1} E1,基尼指数为 G 1 G_{1} G1 D v 2 Dv_{2} Dv2 :属性值 ≤ 6.2 \le 6.2 ≤6.2和 ; 6.2 \gt 6.2 >6.2,相应的信息增益记为 E 2 E_{2} E2,基尼指数为 G 2 G_{2} G2 经过计算得到: E 0 = 1.41973671 E_{0}=1.41973671 E0=1.41973671 E 1 = 0.60845859 , G 1 = 0.375 E_{1}=0.60845859, \quad G_{1}=0.375 E1=0.60845859,G1=0.375 E 2 = 0.55883437 , G 2 = 0.36111111 E_{2}=0.55883437, \quad G_{2}=0.36111111 E2=0.55883437,G2=0.36111111 而且 E 1 E_{1} E1是所有划分中信息增益的最大值, G 2 G_{2} G2是所有划分中基尼指数的最小值 这就是我们想要的反例:按信息增益,划分 D v 1 Dv_{1} Dv1优于 D v 2 Dv_{2} Dv2 ,但按基尼指数 D v 2 Dv_{2} Dv2优于 D v 1 Dv_{1} Dv1,同时它们都是划分集里的极值,以此形成的id3树和cart树将会不同 思考现在,我们已经确定信息增益和基尼指数不是等价的,而且id3树和cart树不一定总是一样的。但我们还需要进一步思考,造成此种现象的原因。 回顾定义: E n t ( D ) = − ∑ k = 1 d p k log 2 p k G i n i ( D ) = 1 − ∑ v = 1 d p v 2 Ent(D)=-\sum^{d}_{k=1}p_{k}\log_{2}p_{k}\\ Gini(D)=1-\sum^{d}_{v=1}p_{v}^{2} Ent(D)=−k=1∑dpklog2pkGini(D)=1−v=1∑dpv2 信息熵和基尼指数都能反映一个集合的纯度,且集合为单一类别时,两者皆为0;集合中每个元素都取自不同类时,两者都取最大值。 刚才的例子中划分 D v 1 Dv_{1} Dv1 将集合划分为两个子集 S 11 , S 12 S_{11},S_{12} S11,S12 属性值4.45.05.15.1类别0100 属性值6.06.06.16.16.16.36.36.46.56.86.87.7类别211122222222S 11 S_{11} S11的信息增益、基尼系数分别为 E s 11 = 0.81127812 , G s 11 = 0.375 E_{s11}=0.81127812, \quad G_{s11}=0.375 Es11=0.81127812,Gs11=0.375 S 12 S_{12} S12的信息增益、基尼系数分别为 E s 12 = 0.81127812 , G s 12 = 0.375 E_{s12}=0.81127812, \quad G_{s12}=0.375 Es12=0.81127812,Gs12=0.375 E 1 = E 0 − 4 16 E s 11 − 12 16 E s 12 , G 2 = 4 16 G s 11 + 12 16 G s 12 E_{1}=E_{0}-\frac{4}{16}E_{s11}-\frac{12}{16}E_{s12}, \quad G_{2}=\frac{4}{16}G_{s11}+\frac{12}{16}G_{s12} E1=E0−164Es11−1612Es12,G2=164Gs11+1612Gs12 划分 D v 2 Dv_{2} Dv2 将集合划分为两个子集 S 21 , S 22 S_{21},S_{22} S21,S22 属性值4.45.05.15.16.06.06.16.16.1类别010021112 属性值6.36.36.46.56.86.87.7类别2222222S 22 S_{22} S22只包含一个类,信息熵和基尼系数都为0. S 21 S_{21} S21的信息增益、基尼系数分别为 E s 21 = 1.53049305 , G s 21 = 0.64197531 E_{s21}=1.53049305, \quad G_{s21}=0.64197531 Es21=1.53049305,Gs21=0.64197531 E 2 = E 0 − 9 16 E s 21 , G 2 = 9 16 G s 21 E_{2}=E_{0}-\frac{9}{16}E_{s21}, \quad G_{2}=\frac{9}{16}G_{s21} E2=E0−169Es21,G2=169Gs21 从中我们可以看到 E s 11 , E s 12 ; E s 21 G s 11 , G s 12 ; G s 21 E_{s11},\,E_{s12} \lt E_{s21} \quad G_{s11},\,G_{s12} \lt G_{s21} Es11,Es12G2呢? 我们注意到 E s 11 E_{s11}\, Es11与 E s 21 E_{s21}\, Es21的差距比 G s 11 G_{s11}\, Gs11与 G s 21 G_{s21}\, Gs21的差距更大,也就是说 S 21 S_{21} S21的混乱状态在熵中得到了更好的表示,被 9 16 \frac{9}{16} 169削弱之后还能显示出混乱,但基尼系数对 S 21 S_{21} S21的混乱状态描述得不够充分,被 9 16 \frac{9}{16} 169削弱之后则显示为更优。 我们看看信息熵和基尼系数的最大值: E n t ( D ) = − ∑ k = 1 n 1 n log 2 1 n = log 2 n G i n i ( D ) = 1 − ∑ v = 1 n 1 n 2 = n − 1 n Ent(D)=-\sum^{n}_{k=1}\frac{1}{n}\log_{2}{\frac{1}{n}} =\log_{2}{n} \\ Gini(D)=1-\sum^{n}_{v=1}\frac{1}{n^{2}}=\frac{n-1}{n} Ent(D)=−k=1∑nn1log2n1=log2nGini(D)=1−v=1∑nn21=nn−1 这时,我们就可以明显感觉到:当集合越是混乱的时候,基尼系数对这种趋势的表现越不够充分。相比之下,信息熵则更能区分出混乱和更混乱。 结论 信息增益和基尼指数不是等价的大多数时候它们的区别很小信息增益对较混乱的集合有很好的表现力,但是基尼指数有所欠缺。另一方面,这也说明较纯的集合,基尼指数可能会区分得更清楚 |
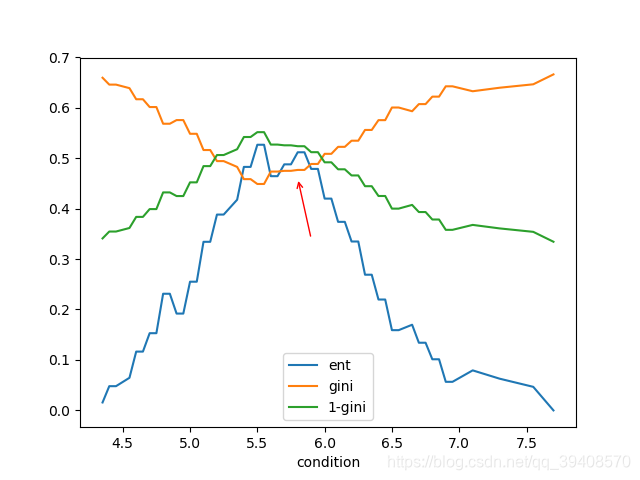 ent为信息增益,gini为基尼指数。同时为了便于观察,引入了
1
−
g
i
n
i
1-gini
1−gini,这样它与ent的意义就更接近:越大越好。 如果说信息增益和基尼指数等价的话,那么对于每一个划分,两者对于它的评价应该是一致的。这并不意味着它们的数值相等,而是指它们的偏序关系是一致的:如果信息增益认为划分A比划分B好,那么基尼指数也能推出划分A比划分B好。简而言之,它们对一组划分的排序应该是完全一致的。 所以我们想找的反例就是信息增益认为划分A比划分B好,但基尼指数却得到相反的结论。 从图中我们可看到,大体上两种标准的趋势是一样的。似乎只要将它们进行y轴上的放缩,就能得到一个不错的拟合。但实际上,如红色箭头标注的那样,两种标准不是完全一致的。信息增益的同时,基尼指数却没有明显提升。可见,它们不是等价的。 但是它们对于最高点,也就是最优划分的判断是一致的。这又引起人的思考,是不是它们只是在局部有细微差别,但是对最优划分却总是一致呢?
ent为信息增益,gini为基尼指数。同时为了便于观察,引入了
1
−
g
i
n
i
1-gini
1−gini,这样它与ent的意义就更接近:越大越好。 如果说信息增益和基尼指数等价的话,那么对于每一个划分,两者对于它的评价应该是一致的。这并不意味着它们的数值相等,而是指它们的偏序关系是一致的:如果信息增益认为划分A比划分B好,那么基尼指数也能推出划分A比划分B好。简而言之,它们对一组划分的排序应该是完全一致的。 所以我们想找的反例就是信息增益认为划分A比划分B好,但基尼指数却得到相反的结论。 从图中我们可看到,大体上两种标准的趋势是一样的。似乎只要将它们进行y轴上的放缩,就能得到一个不错的拟合。但实际上,如红色箭头标注的那样,两种标准不是完全一致的。信息增益的同时,基尼指数却没有明显提升。可见,它们不是等价的。 但是它们对于最高点,也就是最优划分的判断是一致的。这又引起人的思考,是不是它们只是在局部有细微差别,但是对最优划分却总是一致呢?【本文地址】