|
HDFS是Hadoop的分布式文件系统,负责海量数据的存取  HDFS系列文章请参考: HDFS系列文章请参考:
一、HDFS 概述 | 优缺点 | 组成架构 | 文件块大小二、HDFS 常用Shell命令 | 图文详解三、HDFS 搭建客户端 API 环境 | 图文详解 | 提供依赖下载连接四、HDFS API 操作图文详解及参数解读五、HDFS 读写流程 | 图文详解六、HDFS | NameNode和SecondaryNameNode的工作机制七、HDFS | DataNode工作机制 | 数据完整性 | 掉线时限参数设置
文章目录
一、命令大全二、上传1、-mkdir 创建文件夹2、-moveFromLocal 从本地剪切粘贴到HDFS3、-copyFromLocal 或 -put从本地复制到HDFS4、-appendToFile 追加一个文件到已存在的文件末尾
三、下载-copyToLocal 或 -get 从HDFS拷贝到本地
四、HDFS直接操作1、-ls 显示目录信息2、-cat 显示文件内容3、-chgrp、-chmod、-chown 修改文件所属权限4、-cp 或 -mv 从HDFS的一个路径拷贝或移动到HDFS的另一个路径5、-tail 显示一个文件的末尾1kb的数据6、-rm 或 -rm -r 删除文件[夹] ,或递归删除目录及内容7、-du 统计文件夹的大小信息8、-setrep 设置HDFS中副本数量
一、命令大全
在终端输入hadoop fs或者hdfs dfs可以查看所有的命令: 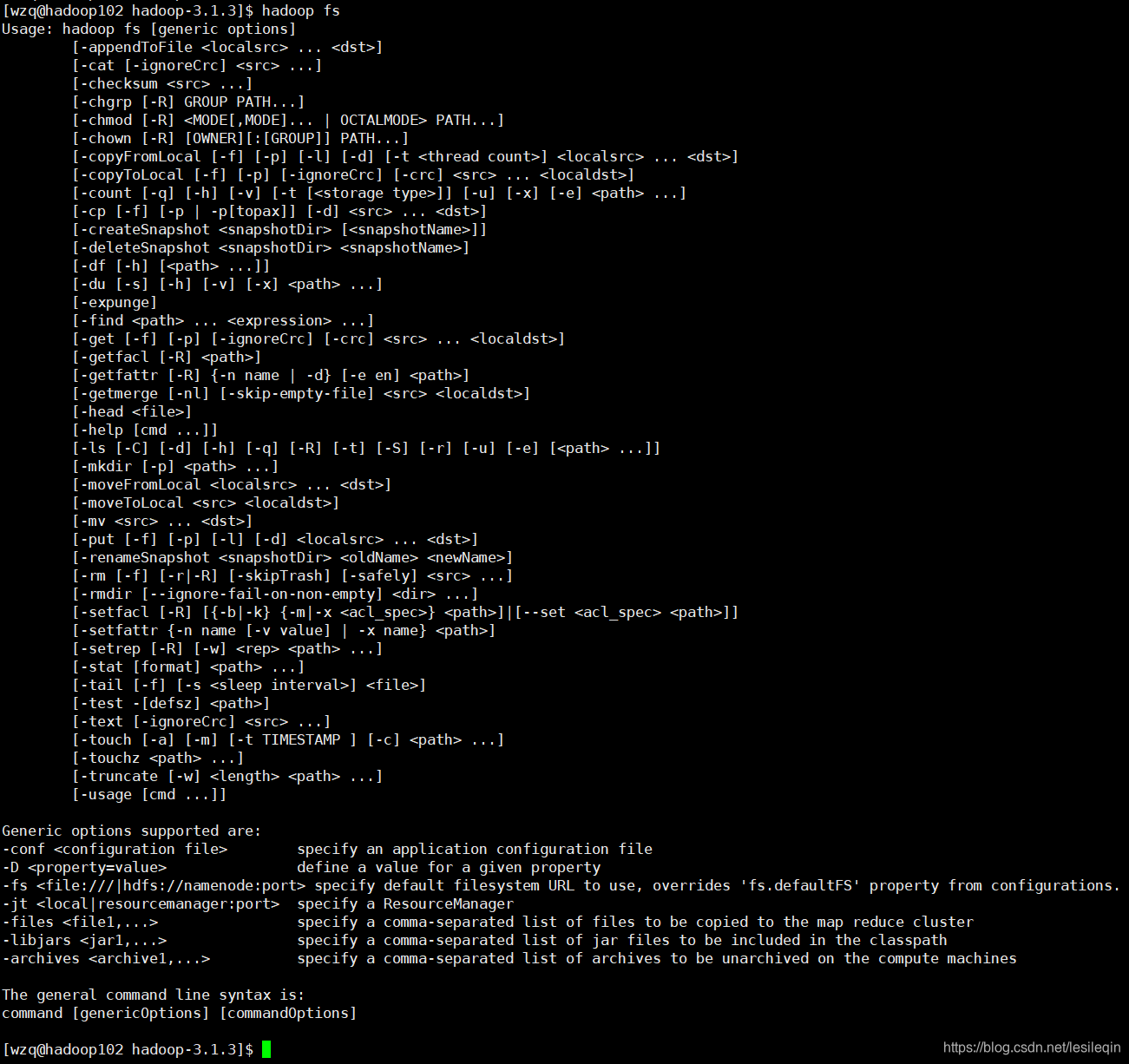 如果想要知道某个命令具体是怎么用的,可以使用-help输出这个命令参数 如果想要知道某个命令具体是怎么用的,可以使用-help输出这个命令参数
比如:
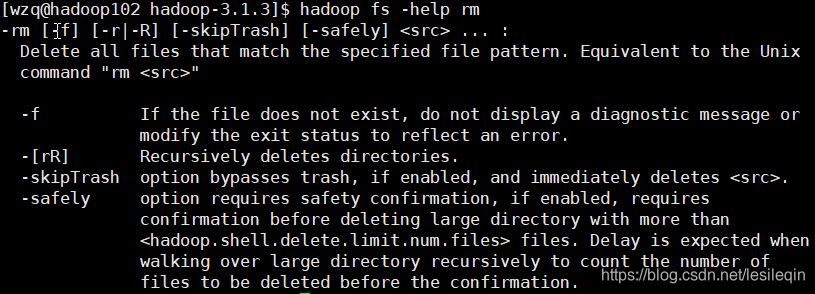
hadoop fs -help rm
输出的内容有:该命令的解释以及可以追加的参数
二、上传
1、-mkdir 创建文件夹
hadoop fs -mkdir /sanguo

2、-moveFromLocal 从本地剪切粘贴到HDFS
vim shuguo.txt
# 在该文件中输入:shuguo
# 剪切粘贴到HDFS
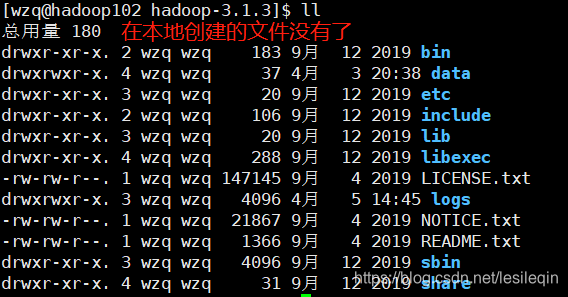
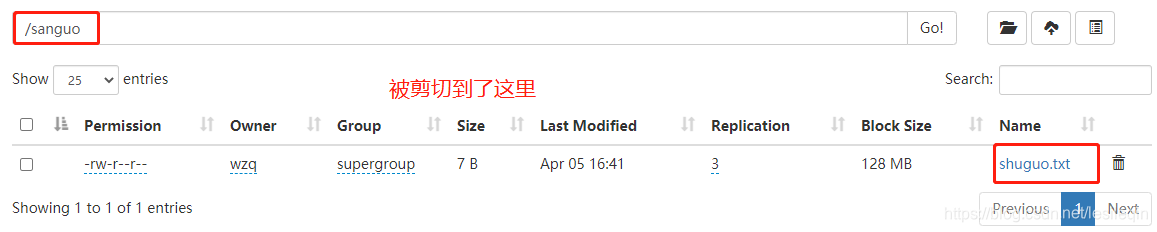
hadoop fs -moveFromLocal ./shuguo.txt /sanguo
3、-copyFromLocal 或 -put从本地复制到HDFS
-copyFromLocal等同于-put,在生产环境中更多使用-put
vim weiguo.txt
# 在该文件中输入:weiguo
# 复制到HDFS
hadoop fs -copyFromLocal weiguo.txt /sanguo
# 或
hadoop fs -put weiguo.txt /sanguo
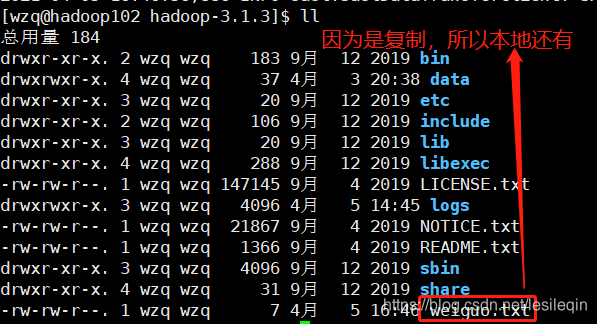 
4、-appendToFile 追加一个文件到已存在的文件末尾
vim liubei.txt
# 在该文件中输入:liubei
# 执行追加
hadoop fs -appentToFile liubei.txt /sanguo/shuguo.txt
在这里踩个坑,执行插入命令之后如果报以下错误: 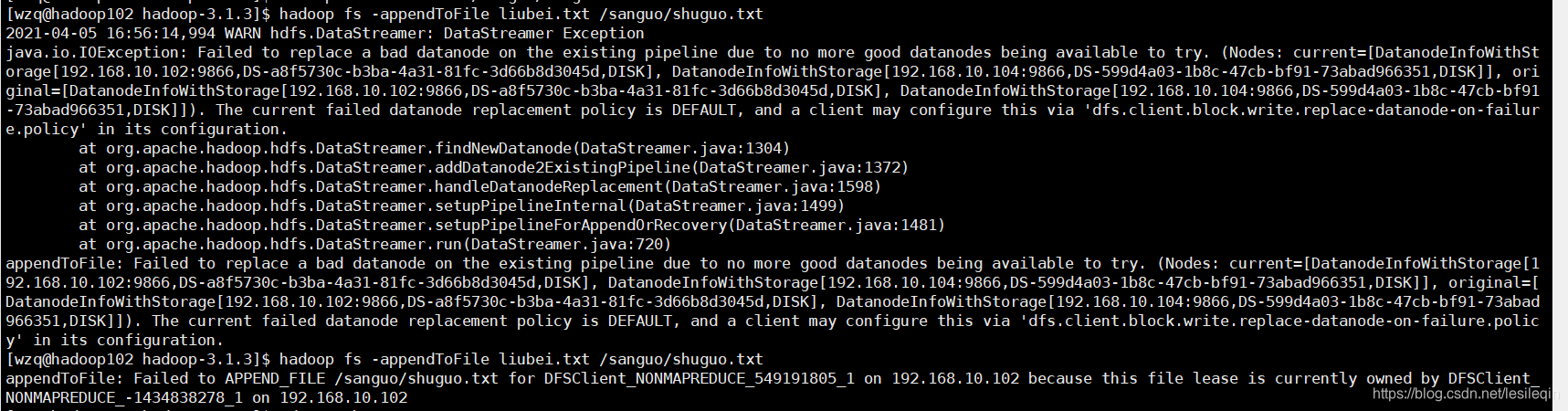 需要在hadoop3.1.3/etc/hadoop/hdfs-site.xml中插入以下配置: 需要在hadoop3.1.3/etc/hadoop/hdfs-site.xml中插入以下配置:
dfs.client.block.write.replace-datanode-on-failure.enable
true
dfs.client.block.write.replace-datanode-on-failure.policy
NEVER
然后分发配置,重启hdfs,再次执行上面的命令,到hdfs中查看效果: 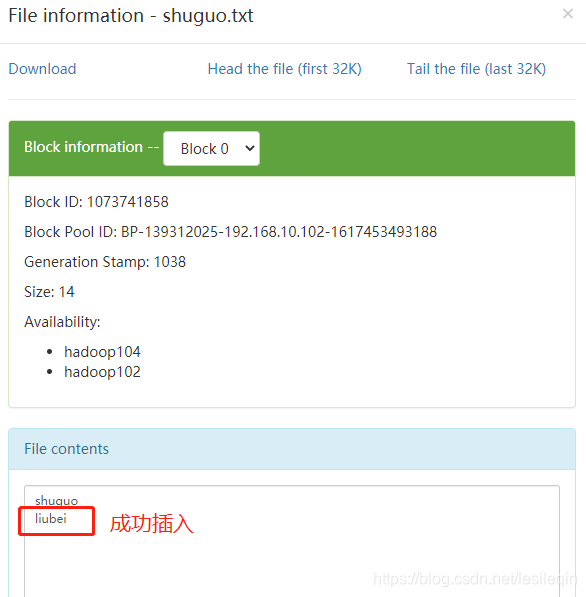
三、下载
-copyToLocal 或 -get 从HDFS拷贝到本地
-copyToLocal等同于-get,在生产环境中更多使用-get
# 从hdfs中下载shuguo.txt,在此命令中还可以更改文件名
hadoop fs -copyToLocal /sanguo/shuguo.txt ./shuguo1.txt
# 或者使用get
hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txx

四、HDFS直接操作
1、-ls 显示目录信息
hadoop fs -ls /sanguo

2、-cat 显示文件内容
hadoop fs -cat /sanguo/shuguo.txt

3、-chgrp、-chmod、-chown 修改文件所属权限
# 更改文件权限
hadoop fs -chmod 777 /sanguo/shuguo.txt
# 更改文件的拥有者
hadoop fs -chown wzq:wzq /sanguo/shuguo.txt

4、-cp 或 -mv 从HDFS的一个路径拷贝或移动到HDFS的另一个路径
# 在hdfs根目录下创建文件夹jinguo
hadoop fs -mkdir jinguo
# 把/sanguo/shuguo.txt复制到/jinguo
hadoop fs -cp /sanguo/shuguo.txt /jinguo
# 把/sanguo/weiguo.txt移动到/jinguo
hadoop fs -mv /sanguo/weiguo.txt /jinguo
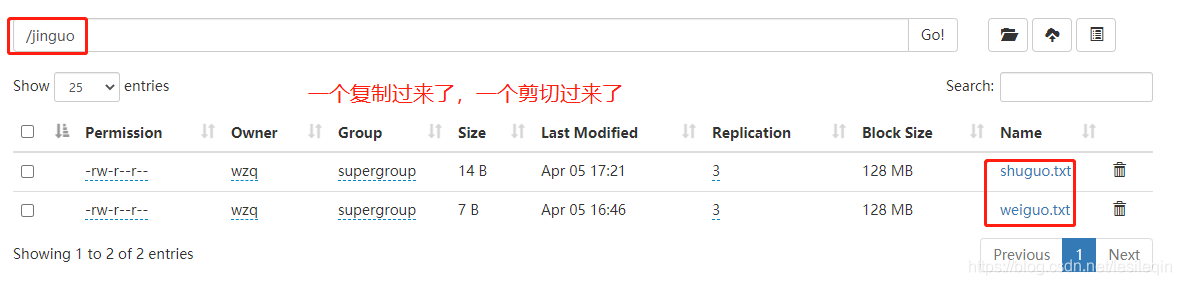 
5、-tail 显示一个文件的末尾1kb的数据
hadoop fs -tail /jinguo/shuguo.txt

6、-rm 或 -rm -r 删除文件[夹] ,或递归删除目录及内容
# 删除/sanguo/shuguo.txt
hadoop fs -rm /sanguo/shuguo.txt
# 递归删除/sanguo目录下所有内容
hadoop fs -rm -r /sanguo
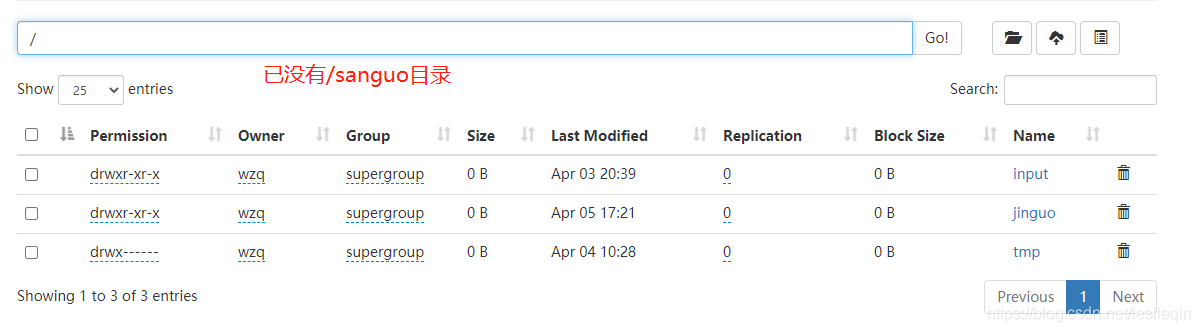
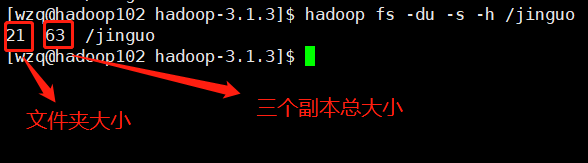
7、-du 统计文件夹的大小信息
显示整个文件夹大小信息:
hadoop fs -du -s -h /jinguo
显示文件夹里的内容大小信息:
hadoop fs -du -h /jinguo

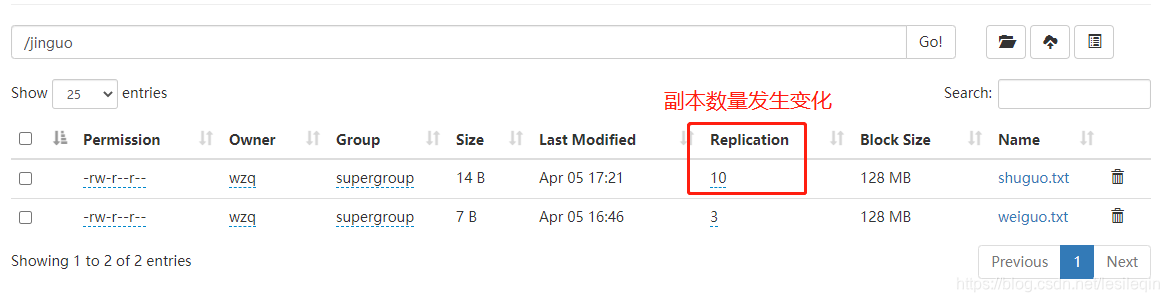
8、-setrep 设置HDFS中副本数量
hadoop fs -setrep 10 /jinguo/shuguo.txt
|