COC部落冲突自动找鱼 python脚本 |
您所在的位置:网站首页 › 部落冲突自动刷资源软件会封号吗 › COC部落冲突自动找鱼 python脚本 |
COC部落冲突自动找鱼 python脚本
|
众所周知,最近COC被腾讯收购了,又整了一波活,花里胡哨的兵种都不认识了,这件事我不做评价吧。 图个新鲜感,高中几个哥们突然又玩起了部落冲突,打🐟一时爽,一直打🐟一直爽,但是找🐟经常要耗费好多时间,那就用脚本啊!自己找🐟是不可能的,但是用脚本挂容易封号;怎么说,只要思想不滑坡,总会有解决方法的是吧。 扒拉了一下午资料,终于找到了志同道合的哥们:
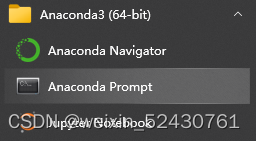
这想法简直和我一拍即合!原文链接放在下面,大家可以先看看这哥们的思路: Python部落冲突自动搜索对手 - 简书 (jianshu.com) 仔细看了一下,实现原理也不难,所以就自己捣鼓了一下,顺便帮哥们改进了一下,比如说按键的位置换成了随机点,以及操作的间隙也改成随机数,总之最重要的原则:一定不能封号 个人喜欢用JupyterNotebook多一点,所以写成了ipynb文件。 首先是环境的要求:(为了照顾小白,我就直接上傻瓜式教程了,最后有代码的简单说明) 首先是python环境的配置,推荐直接用Ancaonda配置环境,Python版本是3.6,版本应该问题不大,安装Anaconda可以参考:anaconda安装-超详细版_plasma-deeplearning的博客-CSDN博客_anaconda安装教程 首先按照上面的链接安装好Anaconda,然后直接在开始菜单栏找到Anaconda3(64-bit)->Anaconda Promopt
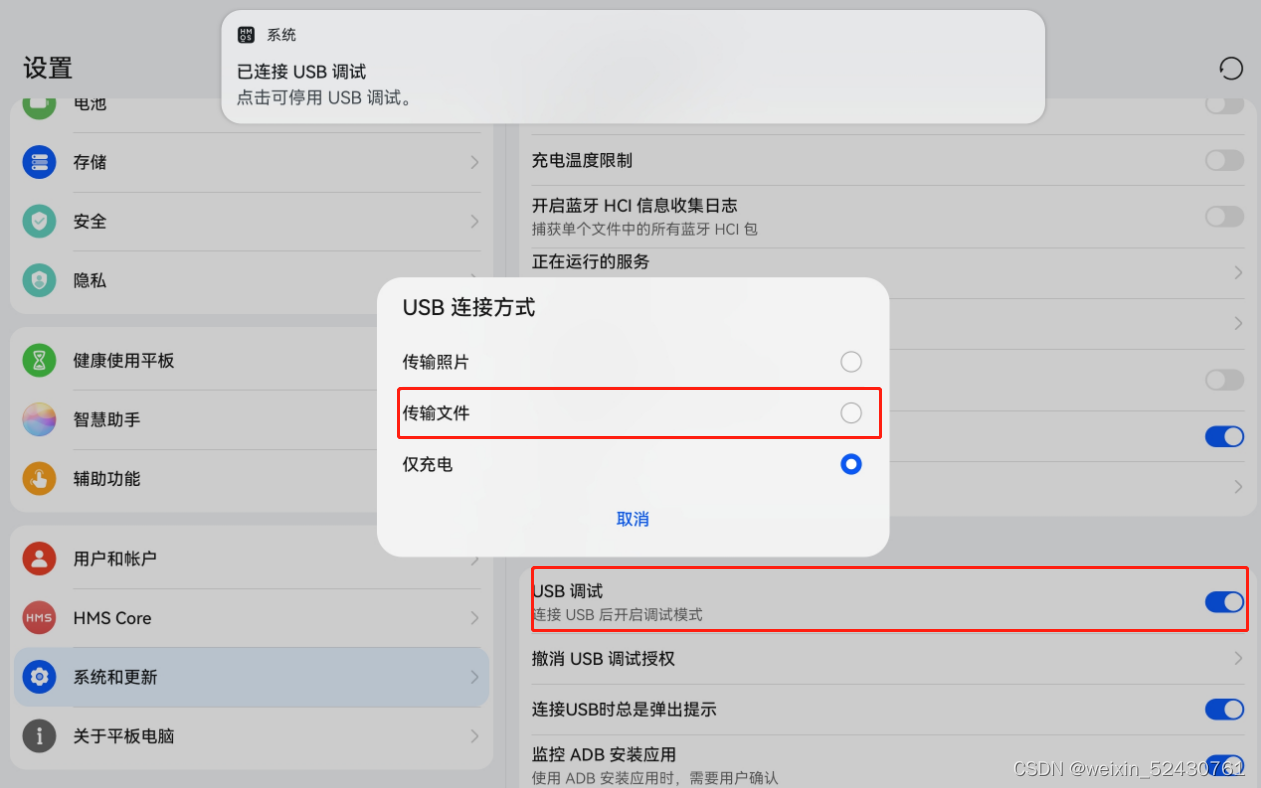
然后复制粘贴下面三句话,搞定。 pip install pillow -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com pip install opencv-contrib-python -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com pip install pywin32 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com 接着是adb和Tesseract的配的配置,这里对设备的操作还是基于adb,所以IOS玩家可以走了;这里需要在手机上进行一定的设置,即打开设备的USB调试然后对于资源的识别我没用百度AI的文字识别,而是直接使用了开源的OCR识别引擎Tesseract,这样就可以实现本地直接识别,不用上传到百度AI那么麻烦,不过识别起来呆呆的(可以把 2 识别成 e 也是我没想到的),哎~想起cv那些图像识别的大作业,真是有苦说不出。手机设置
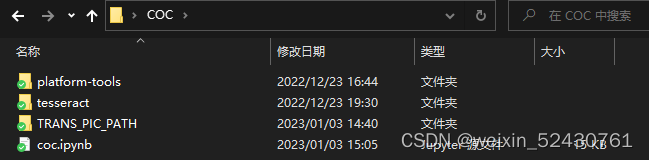
先把我打包好的资源包下载下来,大概100MB https://cowtransfer.com/s/345f72f5bd2645 点击链接查看 [ COC.zip ] 下好后解压缩到你喜欢的位置,里面应该有下面四个东西:
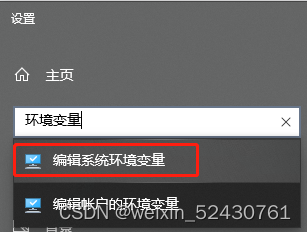
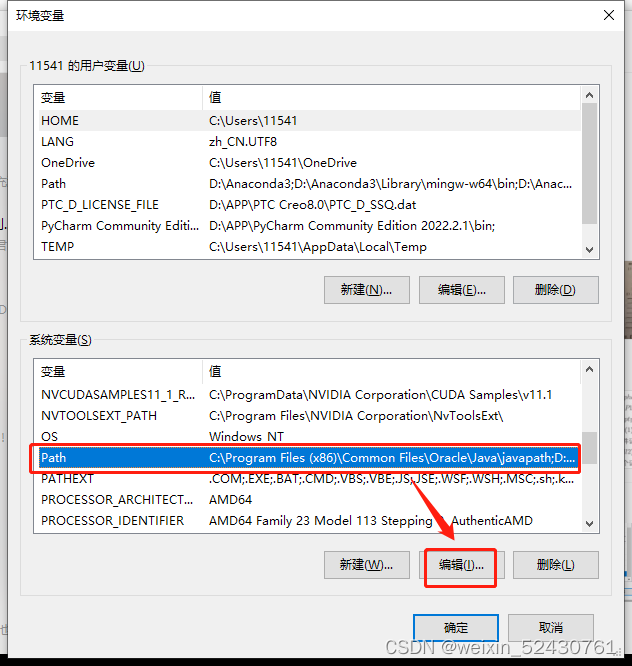
简单说明一下,第一个文件夹是adb调试工具;第二个文件夹是用来图像识别的;第三个文件夹是用来暂时存放截图的,工作的时候可以看看这个文件夹里内容的变化;最后一个是源代码。 最后配置一下环境变量,下面给出win10的操作,这步很简单,win11百度一下应该就会。首先去到电脑设置界面搜索“环境变量”---编辑系统环境变量
然后进入环境变量
在系统变量找到Path,选中点编辑
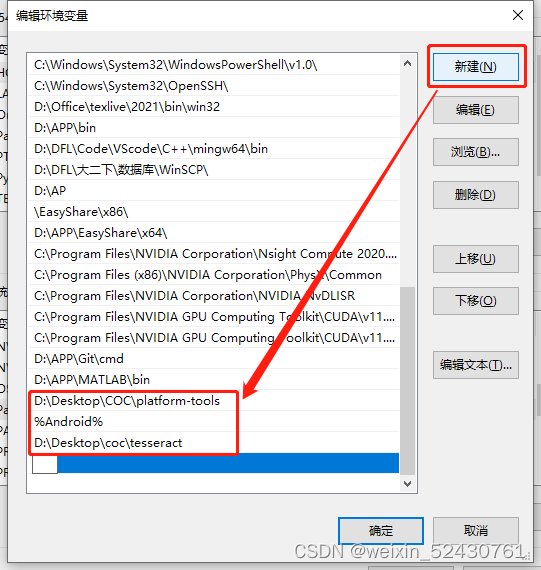
新建以下三个环境变量,第一行和第三行要换成自己电脑的文件夹路径, 具体路径就是刚刚那两个文件夹的路径 D:\Desktop\COC\platform-tools %Android% D:\Desktop\coc\tesseract
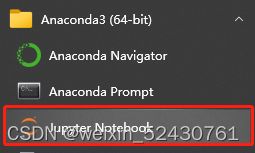
接下来就无脑按几个确定就好了,这样子环境就配置好了。 然后修改一些参数:有一定代码基础的伙伴可以看看最后面附加的思路,自己修改,小白直接改下面几个参数就好: 首先要打开源代码,找到Jupyter Notebok
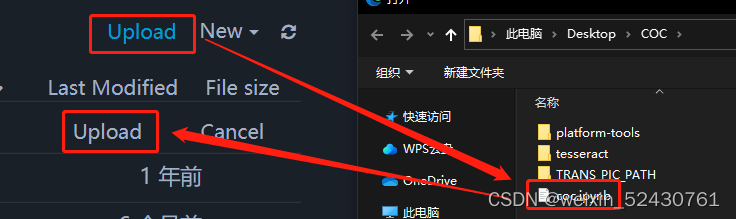
打开后把coc.ipynb文件Upload进工作区
在工作区里找到coc.ipynb文件,单击打开
具体提取像素坐标的方法有很多,这里用PS,其他方法可以百度一下,PS的具体做法就是先把图片reshape成100×100像素(1000×1000也行,按比例换算就好了,不要等比缩放),然后读取像素,具体就是下面两张图: 首先打开信息版 然后用选择工具滑到你想要像素坐标的位置,右边就有像素坐标 代码里面的四个按钮坐标都要换,要不然会点不到按钮 然后还要改一下资源的位置,在 PicScanner类里,找不到就Ctrl+F,搜索im.crop;这里需要把资源的位置坐标量出来 。
上面的改完就差不多好啦,然后就开心的找🐟吧~(记得在手机上打开COC并且回到大本营) 运行所有Cell
系统会在指定文件夹里生成两张图片和一个txt文件,然后找到🐟了就会响一声同时弹窗提醒:
但....
激动的心!颤动的手!
啊这...你管这叫🐟 ???听我说,谢谢你。 算了,毕竟是AI,就这样凑合着用吧~ 基于权限问题,该方法还是只适用于安卓平台 也不能说100%不会被抓,但感觉被抓的可能性不大,毕竟电脑啥也没干,就一个劲地按下一个 最后祝每一个部落人都能天天打大鱼,肥到滴油的那种~ 附上代码的简单说明:大概解释一下,首先是超参数的设置,这里要把路径改成本地的绝对路径,不能用相对路径(应该不能吧,可能有解决办法,我不知道,我只是一个代码能力不过七行的小白)然后就是搜索时长和鱼的判定,这个可以自己设定: # 复制TRANS_PIC_PATH的路径来粘贴,只能用绝对路径,因为要调用cmd path = r'D:\Desktop\COC' # 改成自己的path pic_path = path + r'\TRANS_PIC_PATH' adb_path =path + r'\platform-tools\adb.exe' tesseract_path = path + r'\tesseract\tesseract.exe' # 搜索对手预估时长[t_min,t_max]随机生成一个数字。单位毫秒 t_min = 5000 t_max = 6000 #自己设置是🐟的条件,我就单纯金币+圣水>150K算🐟了 def is_fish(gold,water,oil): if gold+water>1500000: return True else: return False然后是参考上面那篇博客的思路,创建了三个类。 首先是ScreenCapturer类,主要作用是截屏传到电脑同时定义一些在手机上的操作。 from time import sleep import random import os class ScreenCapturer: #获取截图,同时定义一些在手机上的操作 phoneResolution = [] # 手机分辨率 def __init__(self,andriod="",trans=""): if andriod!="" and trans != "": # 判断是否为默认参数 self.ANDRIOD_PIC_PATH = andriod self.TRANS_PIC_PATH = trans def getPhoneScreen(self): # 获取屏幕截图 os.system(adb_path+' shell screencap -p /sdcard/screenshot.png') def transPhoneScreen(self): # 将截图传输至电脑 command = adb_path+' pull /sdcard/screenshot.png '+pic_path+'\screenshot.png' os.system(command) # 模拟点击某一位置 def pointOnPhone(self,x=0.0,y=0.0): strX = str(x) strY = str(y) command = adb_path+" shell input tap " + strX + " " + strY os.system(command) pass # 获取屏幕分辨率 def getPhoneResolution(self): # 获取命令行的打印值 r = os.popen(adb_path+" shell dumpsys window displays") text = str(r.read()) # 查找init=字符串,其后为手机分辨率情况 beginC = text.find("init=") # 获取其后的10个字符 line = text[beginC+5:beginC+15] resolution = line.split("x") self.phoneResolution.append(float(resolution[0])) self.phoneResolution.append(float(resolution[1])) r.close() pass # 点击进攻按钮 def pointAttackBtn(self): # 保留两位小数 x = random.uniform(0.021,0.098) * self.phoneResolution[1] y = random.uniform(0.838,0.964) * self.phoneResolution[0] self.pointOnPhone(x,y) print("点击-进攻-按钮") # 点击搜索对手按钮 def pointSearchAttacker(self): # 保留两位小数 x = random.uniform(0.652,0.83) * self.phoneResolution[1] y = random.uniform(0.543,0.69) * self.phoneResolution[0] self.pointOnPhone(x, y) print("点击-搜索对手-按钮") # 点击搜索下一个按钮 def pointNextAttacker(self): # 保留两位小数 x = random.uniform(0.853,0.975) * self.phoneResolution[1] y = random.uniform(0.714,0.8) * self.phoneResolution[0] self.pointOnPhone(x, y) print("点击-搜索下一个-按钮") # 点击结束战斗按钮 def pointEndAttack(self): # 保留两位小数 x = random.uniform(0.02,0.1) * self.phoneResolution[1] y = random.uniform(0.769,0.8) * self.phoneResolution[0] self.pointOnPhone(x, y) print("点击-结束战斗-按钮")这里的x和y都改成了范围,避免太呆被抓。 然后是PicScanner类,作用就是识别截图到的图片,对图像做一些变化,比如说灰度处理和二值化处理,提高识别精度,然后把它转成文字,传进一个数组里。 from PIL import Image from io import open import cv2 import numpy as np import re class PicScanner: #从截图识别资源 def __init__(self,path=""): if path!="": self.filePath = path def get_file_content(self,filePath): with open(filePath, mode='rb') as f: return f.read() def cutPicToSource(self): # 将截图裁剪至仅剩资源的部分,方便于图片识别 im = Image.open(pic_path+'\screenshot.png', 'r') if im: width, height = im.size img = im.crop((0.045 * width, 0.105 * height, 0.135 * width, 0.225 * height)) #裁剪 img = cv2.cvtColor(np.array(img), cv2.COLOR_RGBA2BGRA) #PIL->np img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY); #灰度处理 ret,img=cv2.threshold(img, 230, 255, cv2.THRESH_BINARY); #二值化处理 cv2.imwrite(pic_path+'\sourse.png',img) def readPicNum(self): #图像识别,即图像转文字,所用包为tesseract,也可以换成其他的包 command = tesseract_path+' '+pic_path+'\sourse.png '+pic_path+'\sourse -l eng' os.system(command) f=open(pic_path+'\sourse.txt', encoding='gbk') txt=[] i = 0; for line in f: txt.append(line.strip()) string = ''.join(ch for ch in txt[i] if ch.isalnum()) string = string.replace(" ",'') #删掉多余的空格 #AI的蜜汁识别 string = string.replace("S",'5') string = string.replace("O",'0') string = string.replace("I",'1') string = string.replace("l",'1') string = string.replace("e",'2') #可能识别出各种奇奇怪怪的单词,识别不出直接不要,找选下一个🐟 try: txt[i] = int(string) except: return [] i = i+1 return txt最后就是autoFind类,就是集成了上面两个类,然后用while循环一直找🐟,找到的话提醒你 import win32con, win32api import winsound class autoFind: # 对象实例 scanner = PicScanner() capture = ScreenCapturer() # 设置的搜索资源值 source = {} def setSourceValue(self,gold,water,oil): self.source['gold'] = gold self.source['water'] = water self.source['oil'] = oil def beginFind(self): self.capture.getPhoneResolution() # 获取屏幕分辨率 self.capture.pointAttackBtn() # 点击进攻按钮 sleep(1) print('\n----------------------------------------------------') self.capture.pointSearchAttacker() # 点击搜索对手按钮 sleep(random.randint(t_min,t_max)/1000) while(1): #无限循环,直到找到🐟 # 获取屏幕截图并判断资源 print("...........识别中..........") self.capture.getPhoneScreen() #截图 self.capture.transPhoneScreen() #传图片到电脑 self.scanner.cutPicToSource() #截取资源 words = self.scanner.readPicNum() #读取资源 if len(words) == 3 and words[0] |









【本文地址】
今日新闻 |
推荐新闻 |