如何判断线性回归模型(Linear Regression)的好坏 |
您所在的位置:网站首页 › 线性回归方程怎么判断是否相关 › 如何判断线性回归模型(Linear Regression)的好坏 |
如何判断线性回归模型(Linear Regression)的好坏
|
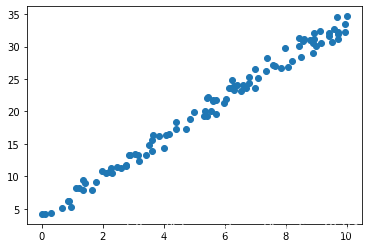
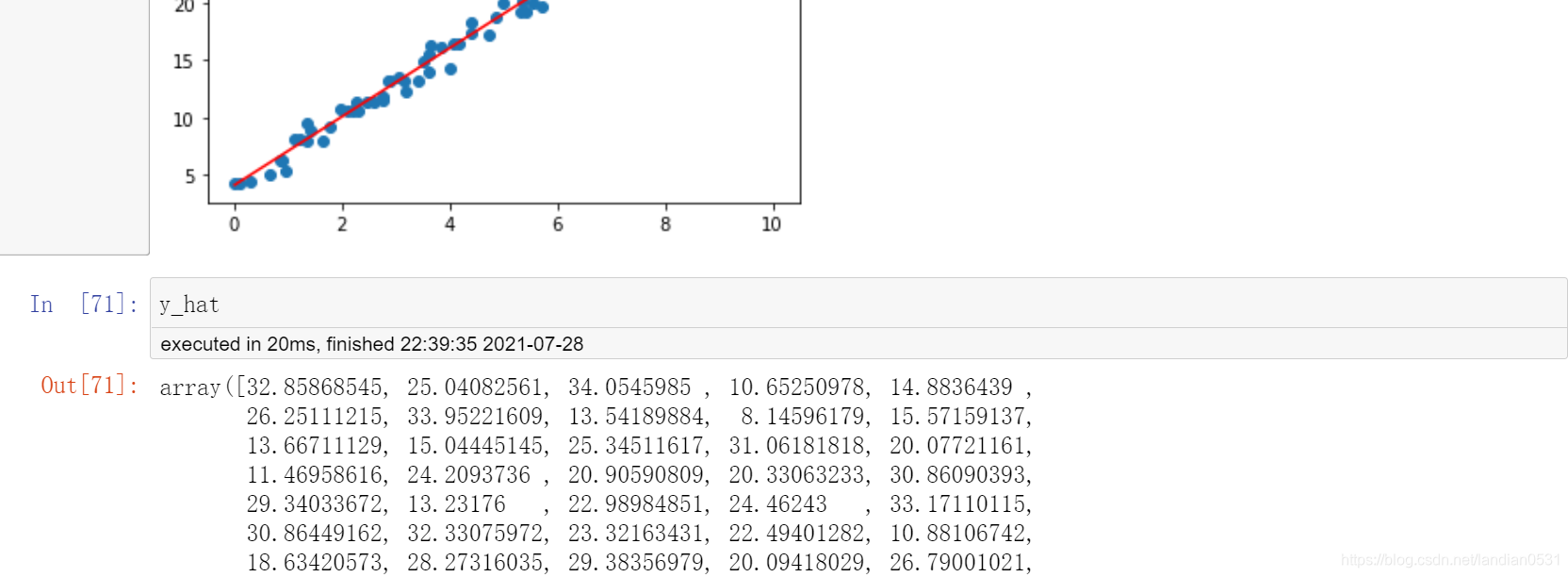
本文旨在对刚学了一点Linear Regression理论知识, 还不知道代码如何实现,以及代码复现后查看哪些参数可以确定线性回归模型训练的好坏的同学,有些许启发. 本文参考公众号’酷酷的算法’ 按照官方文档修订了R方的公式 一. 模型训练 一般我们需要通过模型求weight和bias, 但这次为了方便验证,我们假设已知方程 f ( x ) = 3 x + 4 f(x) = 3x +4 f(x)=3x+4来模拟实验环境, weight和bias是3和4.x x x: 通过random.uniform()来获得已知的特征矩阵 通过random.normal()来生成噪声, 和已知方程合并生成y import numpy as np import matplotlib.pyplot as plt np.random.seed(24) x=np.random.uniform(0,10,size=100) #左闭右开 随机生成浮点数 已知的特征矩阵 #x =np.random.randint(a,b) 左闭右开, 随机生成整数 X=x.reshape(-1,1) ##reshape新数组为1列, 以便 y=3*x+4+np.random.normal(0,1,100) # y是真实值 plt.scatter(x,y) plt.show()
查看数据 如下:
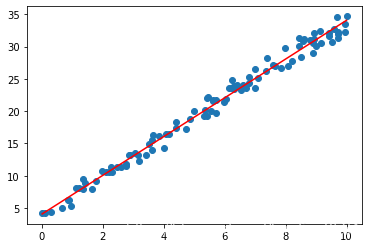
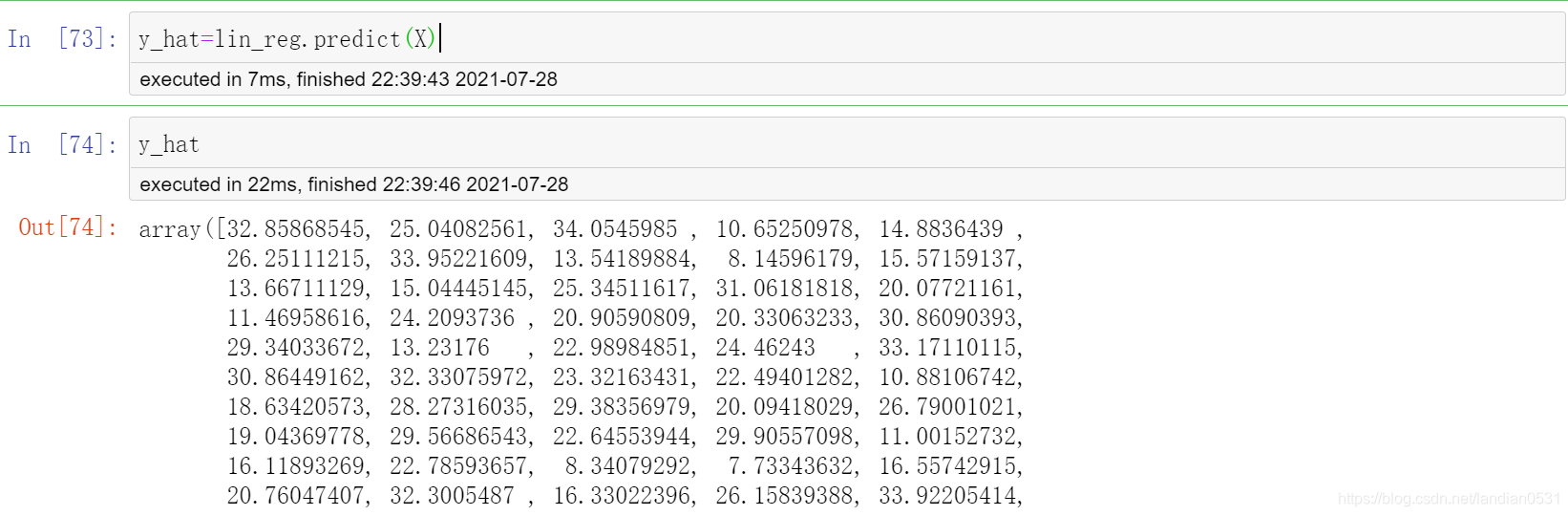
fit函数 from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X,y)Output: LinearRegression() 训练完成后即可得出weight和biasLinearRegression.coef_ 回归系数 即 权重weight lin_reg.coef_ #表示直线的斜率. 回归系数越大表示X 对y影响越大, 正回归系数表示y 随X增大而增大,负回归系数表示y 随X增大而减小Output: array([3.00103731])LinearRegression.intercept_ : 截距 即 bias lin_reg.intercept_ #表示直线在y轴上的截距,代表直线的起点Output: 4.048208007900303因此, 预测值y_hat, 即可根据上面得出的weight和bias代入方程得出, 代码如下图: y_hat=lin_reg.coef_[0]*x+lin_reg.intercept_ plt.scatter(x,y) #散点图 plt.plot(np.sort(x),y_hat[np.argsort(x)],color='r') #np.sort 对给定的数组的元素进行排序 #np.argsort(x) 将x中的元素从小到大排列, 提取其对应的index plt.show()
y_hat 由方程求得, 数值如下:
如果直接使用LinearRegression.predict(X), 所得数值与方程求得数值相同
数值约接近1, 代表模型拟合越好. 2.1 均方误差MSE(MeanSquaredError)1 m ∑ i = 1 m ( y − y ^ ) 2 \frac1m \sum_{i=1}^m(y -\hat y)^2 m1i=1∑m(y−y^)2 使用样本的真实值减去样本的预测值,然后平方(因为可能减出来的是负数),假设一共m个样本,乘以1/m以便最终值和样本个数无关 from sklearn.metrics import mean_squared_error MSE=mean_squared_error(y,y_hat) MESOutput: 0.9255820462274633 2.2 均方根误差RMSE(RootMeanSquaredError)1 m ∑ i = 1 m ( y − y ^ ) 2 \sqrt{\frac1m \sum_{i=1}^m(y -\hat y)^2} m1i=1∑m(y−y^)2 RMSE是MSE的平方根 from math import sqrt RMSE=sqrt(mean_squared_error(y,y_hat)) RMSEOutput: 0.962071746922995 2.3 平均绝对误差MAE (MeanAbsoluteError)1 m ∑ i = 1 m ∣ y − y ^ ∣ \frac1m \sum_{i=1}^m|y -\hat y| m1i=1∑m∣y−y^∣ MAE的计算方法和MSE的计算方法不同在于抵消符号使用的是绝对值的方法 from sklearn.metrics import mean_absolute_error MAE=mean_absolute_error(y,y_hat) MAEOutput: 0.7953110680751729 2.4 R方 ( R 2 R^2 R2) (R_Squared) 最好的标准
R方也叫确定系数(coefficient of determination) R 2 = 1 − ∑ i ( y − y ^ ) 2 ∑ i ( y − y ‾ ) 2 R^2 = 1- \frac{ \sum_{i}(y-\hat y)^2}{ \sum_{i}(y-\overline{y} )^2} R2=1−∑i(y−y)2∑i(y−y^)2 from sklearn.metrics import r2_score R2=r2_score(y,y_hat) R2Output: 0.987840340927941注意: 默认LinearRegression对象中直接封装了一个成员函数,即R方,调用函数并传入需要预测的特征矩阵以及每个样本的真实值 lin_reg.score(X,y)Output: 0.987840340927941 |


【本文地址】
今日新闻 |
推荐新闻 |