转:激活函数sigmoid、tanh、softmax、relu、swish原理及区别 |
您所在的位置:网站首页 › 常用激活函数silu › 转:激活函数sigmoid、tanh、softmax、relu、swish原理及区别 |
转:激活函数sigmoid、tanh、softmax、relu、swish原理及区别
|
常见和常用的激活函数: 主要用于二分类:Sigmoid、Tanh 主要用于多分类:Relu、Swish、Softmax 主要用于深层网络:Relu、Swish、及Relu变形 如果没有激活函数的神经网络,在这种情况下,每个神经元将只使用权重和偏差对输入执行线性变换。虽然线性变换使神经网络更简单,但这种网络的功能会减弱,并且无法从数据中学习复杂的模式。没有激活函数的神经网络本质上只是一个线性回归模型。因此,我们对神经元的输入使用非线性变换,并且网络中的这种非线性是由激活函数引入的。 一、Sigmoid数学表达式:

sigmoid函数也叫 Logistic 函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。 函数导数:

梯度值对于范围 -3和3是显著的,但是图形在其他区域变得更平坦,这意味着对于大于3或小于-3的值,梯度将非常小,当梯度值趋近于零时,网络并没有真正学习。 什么情况下适合使用Sigmoid? 1.sigmoid函数的输出范围是0到1。由于输出值在0和1之间,它相当于将每个神经元的输出归一化。 2. 特别适合用于需要将预测概率作为输出的模型。因为任何概率值的范围是[0,1],而且我们往往希望概率值尽量确定(即概率值远离0.5),所以s型曲线是最理想的选择。 3. 平滑梯度。显然,sigmoid函数在定义域上处处可导。 4. sigmoid函数是可微的,这意味着我们可以找到任意两点之间的斜率。 5. 明确的预测值。也就是说倾向于接近0或1。 sigmoid缺点:1.激活函数计算量大,反向传播求误差梯度时,求导涉及除法。2.反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练 二、Tanh激活函数:

值的范围在 -1到1之间,除此之外,tanh 函数的所有其他性质都与 Sigmoid形函数函数的性质相同。与 sigmoid 函数类似,tanh 函数在所有点上都是连续可微的。让我们来看一下 tanh 函数的梯度。 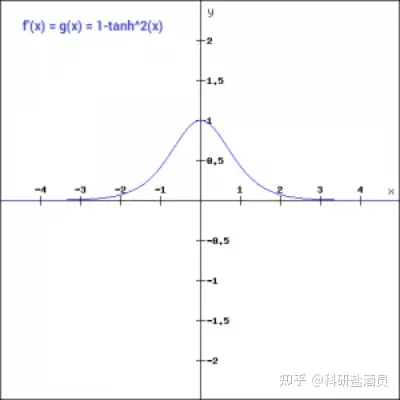
与 sigmoid 函数相比,tanh 函数的梯度更陡峭。通常 tanh 优于 sigmoid 函数,因为它以零为中心,并且梯度不限于在某个方向上移动。tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。 Note: 在二分类问题中,一般tanh被用在隐层,而sigmoid被用在输出层。但这不是一成不变的,应当根据网络结构以及问题的特点进行灵活调整。 三、ReluReLU 函数是另一种在深度学习领域广受欢迎的非线性激活函数。与其他激活函数相比,使用 ReLU 函数的主要优点是它不会同时激活所有神经元。这意味着只有当线性变换的输出小于 0 时,神经元才会被停用。

求导函数:  
梯度值为零在反向传播过程中,一些神经元的权重和偏差没有更新。 这会产生永远不会被激活的死神经元。 ReLU 的优点: 使用ReLU得到的SGD的收敛速度会比 sigmoid/tanh 快很多。 ReLU 的缺点:训练的时候很脆弱,大部分神经元会在训练中死忙,例如,一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元的梯度就永远都会是 0。如果 learning rate 很大,那么很有可能网络中的 40% 的神经元都死了。 还有两种变形,主要解决梯度值为0,部分神经元不会被激活的问题Leaky ReLU 、Parametric ReLU、Exponential Linear Units。既保留了Rrlu的有点,也有相应的创新。 四、SwishSwish 是一种鲜为人知的激活函数,由 Google 的研究人员发现。 Swish 在计算上与 ReLU 一样高效,并且在更深的模型上表现出比 ReLU 更好的性能。 swish 的值范围从负无穷到无穷。 该函数定义为

函数的曲线是平滑的,并且函数在所有点上都是可微的。这在模型优化过程中很有帮助,被认为是 swish 优于 ReLU 的原因之一。 
关于这个函数的一个独特的事实是 swich 函数不是单调的。 这意味着即使输入值增加,函数的值也可能会减小。 五、SoftmaxSoftmax 函数通常被描述为多个 sigmoid 的组合。 我们知道 sigmoid 返回 0到1之间的值,可以将其视为属于特定类的数据点的概率。 因此 sigmoid 被广泛用于二分类问题。 softmax 函数可用于多类分类问题。此函数返回属于每个单独类的数据点的概率。 数学表达式  六、区别
六、区别
总的来说:、 sigmoid 容易产生梯度消失问题,ReLU 的导数就不存在这样的问题 sigmoid将一个real value映射到(0,1)的区间,用来做二分类,而 softmax 主要进行进行多分类的任务。二分类问题时 sigmoid 和 softmax 是一样的,求的都是 cross entropy loss,而 softmax 可以用于多分类问题。 softmax建模使用的分布是多项式分布,而logistic则基于伯努利分布,多个logistic回归通过叠加也同样可以实现多分类的效果,但是 softmax回归进行的多分类,类与类之间是互斥的,即一个输入只能被归为一类;多个logistic回归进行多分类,输出的类别并不是互斥的,即"苹果"这个词语既属于"水果"类也属于"3C"类别。 如果使用 ReLU,要小心设置 learning rate,注意不要让网络出现很多 “dead” 神经元,如果不好解决,可以试试 Leaky ReLU,Swish等。
转自:https://zhuanlan.zhihu.com/p/494417245 本文来自博客园,作者:河北大学-徐小波,转载请注明原文链接:https://www.cnblogs.com/xuxiaobo/p/17203533.html |





【本文地址】
今日新闻 |
推荐新闻 |