五分钟带你理解常用的激活函数 |
您所在的位置:网站首页 › 常用激活函数图像 › 五分钟带你理解常用的激活函数 |
五分钟带你理解常用的激活函数
|
建议学习激活函数前首先对神经网络有初步了解
引言一、什么是激活函数二、为什么要用激活函数三、常用激活函数1、 Sigmoid函数1)函数图像2)导数图像3)Simoid函数的非零均值问题
2、tanh函数1)函数图像2)导数图像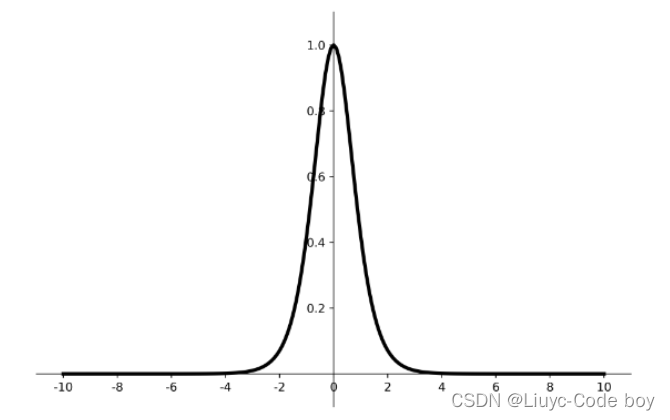
3、Relu函数1)函数图像2)导数图像3)Relu函数的一些问题3)一些Relu的改进函数
四、应用中我们应该如何选择合适的激活函数?五、参考资料
引言
学习神经网络理论知识包括自己搭建神经网络初始化的时候,我们总听到一个叫做激活函数(Activation Function)。所谓激活函数,就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。 常见的激活函数比如Sigmoid函数、tanh函数、Relu函数。 如果你已经具备了一定的深度学习的基础知识,那么下面对激活函数的分析将会帮你对激活函数有一个更好的理解。 一、什么是激活函数我们以神经网络模型的工作方式为例 假设没有激活函数,也就是上一层的输出直接作为下一层的输入,那么这种情况下每一层节点的输入和上一层输出之间都是线性的关系。那么隐藏层就失去了意义,因为无论神经网络一共有多少层最终输出都是输入的线性组合(最原始的感知机),这种情况下网络的逼近能力非常有限。 所以我们引入了非线性函数作为激活函数目的就是可以使得输出不再是输入的简单线性组合,而是可以逼近任何函数。 三、常用激活函数 1、 Sigmoid函数 1)函数图像Sigmoid常作为激活函数,其图像如下: Sigmoid函数的导数图像如下: 首先我们回顾一下simoid的函数图像我们可以发现,由于输出结果恒大于零,所以输出结果并不是以0为均值(eg,输出结果为[-5,5]均值就是0)。 回顾一下梯度下降的公式:

但是通过观察导数图像我们发现tanh函数两侧依然接近于0,在反向求导过程中依然有梯度消失的问题。 3、Relu函数 1)函数图像Relu函数的解析式是:Relu = max(0,x) 图像如下:
 3)一些Relu的改进函数
3)一些Relu的改进函数
Relu函数也有很多改进函数比如Leaky Relu函数、ELU(Exponential Linear Units)函数、MaxOut函数等等,在这里我就不一 一展示了,感兴趣的小伙伴可以自己百度学习一下。 四、应用中我们应该如何选择合适的激活函数?由于博主也只是刚开始学习这部分知识所以目前还没什么比较好的对于激活函数选择的见解,但是结合上面的内容我们可以知道的是: 尽量使用0均值的数据(可以对数据进行一些预处理)进行输入和输出,这样能够有更好的收敛效果。如果使用Relu函数的话要注意学习率α的设置,避免网络出现过多的dead神经元。最好不用sigmoid,可以试试tanh,不过现在最受大家认可的还是Relu和Relu的一些改进。 五、参考资料 https://blog.csdn.net/tyhj_sf/article/details/79932893?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166346808916800182112211%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=166346808916800182112211&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-79932893-null-null.142v47pc_rank_34_2,201v3control_1&utm_term=%E6%BF%80%E6%B4%BB%E5%87%BD%E6%95%B0&spm=1018.2226.3001.4187 2.https://blog.csdn.net/songyufeishibyr/article/details/108683269https://blog.csdn.net/a1097304791/article/details/119135913 |
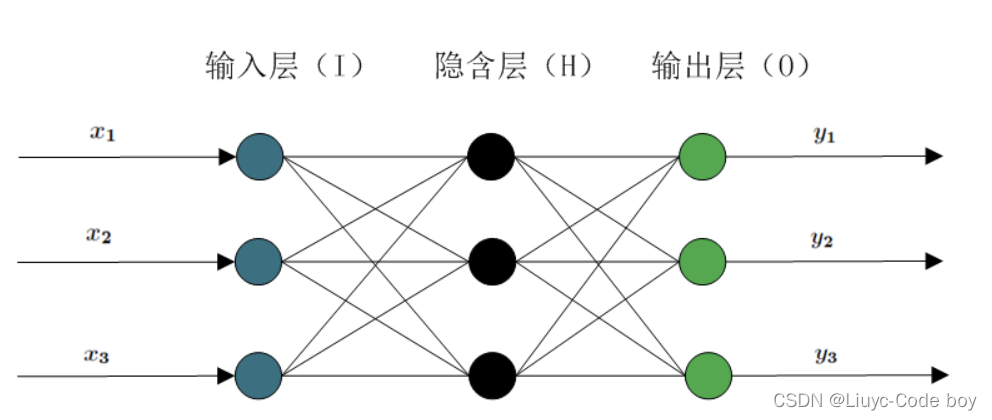 我们将一组输入输送给神经网络模型最终得到输出之前,都要经过一系列的隐藏层。在多层的神经网络中,上一层的输出结果并不会直接作为下一层的输入,而是会经过一个函数关系的处理,这个函数关系就叫做激活函数。
我们将一组输入输送给神经网络模型最终得到输出之前,都要经过一系列的隐藏层。在多层的神经网络中,上一层的输出结果并不会直接作为下一层的输入,而是会经过一个函数关系的处理,这个函数关系就叫做激活函数。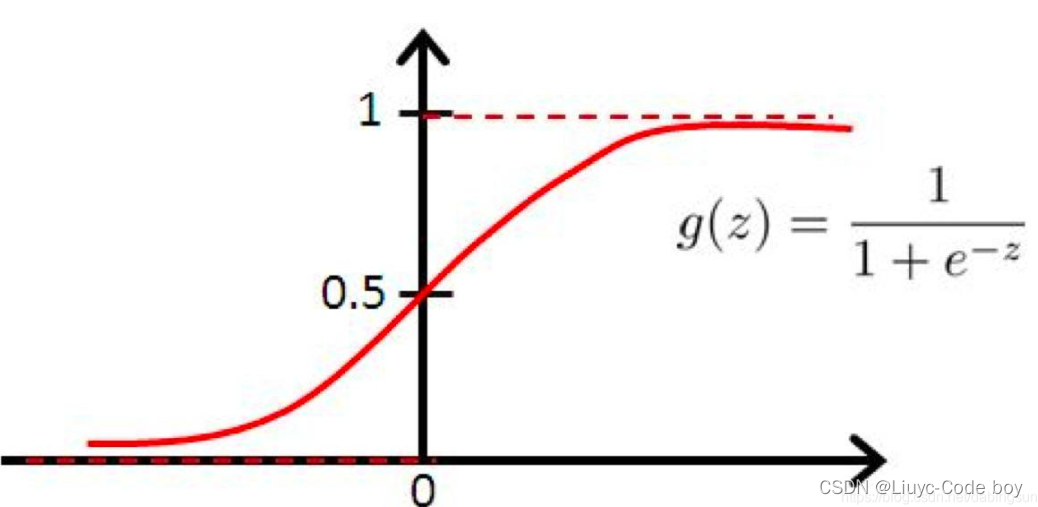 我们可以发现sigmoid函数的特点就是可以把连续的数据变换到0-1之间输出,如果输入接近于-∞就输出0,如果输入接近+∞就输出1。
我们可以发现sigmoid函数的特点就是可以把连续的数据变换到0-1之间输出,如果输入接近于-∞就输出0,如果输入接近+∞就输出1。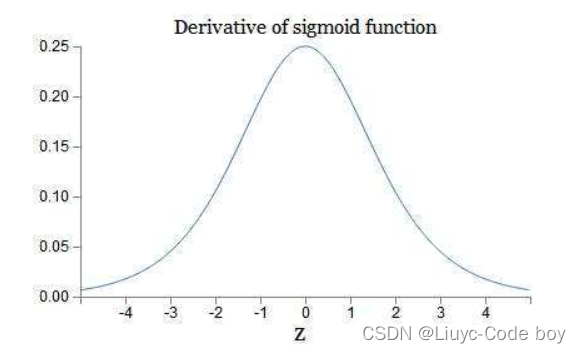 可以看到Sigmoid的值域及其导数恒大于0,并且在两侧都接近于0,所以Simoid函数可能会引起梯度消失,产生梯度消失的原因主要是,当我们进行反向传播的时候,如果神经网络的隐藏层比较多,那么梯度在穿过多层的反向求导之后可能会变得非常的小接近于0,或者输出结果非常大那么反向求导的结果非常靠右我们发现他也是接近于0,也就是梯度消失现象。
可以看到Sigmoid的值域及其导数恒大于0,并且在两侧都接近于0,所以Simoid函数可能会引起梯度消失,产生梯度消失的原因主要是,当我们进行反向传播的时候,如果神经网络的隐藏层比较多,那么梯度在穿过多层的反向求导之后可能会变得非常的小接近于0,或者输出结果非常大那么反向求导的结果非常靠右我们发现他也是接近于0,也就是梯度消失现象。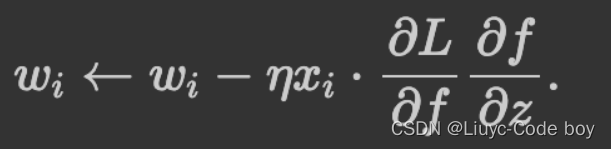 我考虑wi更新的方向,后几项中超参数,他是人为规定的,是默认值,不用考虑。再看最后两位乘积项,L是损失函数,z我认为就是表示已经反向传播完的那些层带来的参数,发现最后两位乘积项在某一次反向传播也是不变的,也不用考虑。 所以w值的更新方向只与xi值有关,(这个xi是梯度下降过程中损失函数对wi求偏导时wi的系数),这个值是上一层神经元经过Simoid激活函数处理过后的输入值,肯定是正值,那么可以得出结论:在某一次反向传播时,对于神经元来说,w1、w2…改变的方向是统一的,或正或负。所以如果你的最优值是需要w1增加,w2减少,那么只能走z字形才能实现。 这导致的结果是要么w都往正方向更新,要么w都往负方向更新,收敛缓慢。
我考虑wi更新的方向,后几项中超参数,他是人为规定的,是默认值,不用考虑。再看最后两位乘积项,L是损失函数,z我认为就是表示已经反向传播完的那些层带来的参数,发现最后两位乘积项在某一次反向传播也是不变的,也不用考虑。 所以w值的更新方向只与xi值有关,(这个xi是梯度下降过程中损失函数对wi求偏导时wi的系数),这个值是上一层神经元经过Simoid激活函数处理过后的输入值,肯定是正值,那么可以得出结论:在某一次反向传播时,对于神经元来说,w1、w2…改变的方向是统一的,或正或负。所以如果你的最优值是需要w1增加,w2减少,那么只能走z字形才能实现。 这导致的结果是要么w都往正方向更新,要么w都往负方向更新,收敛缓慢。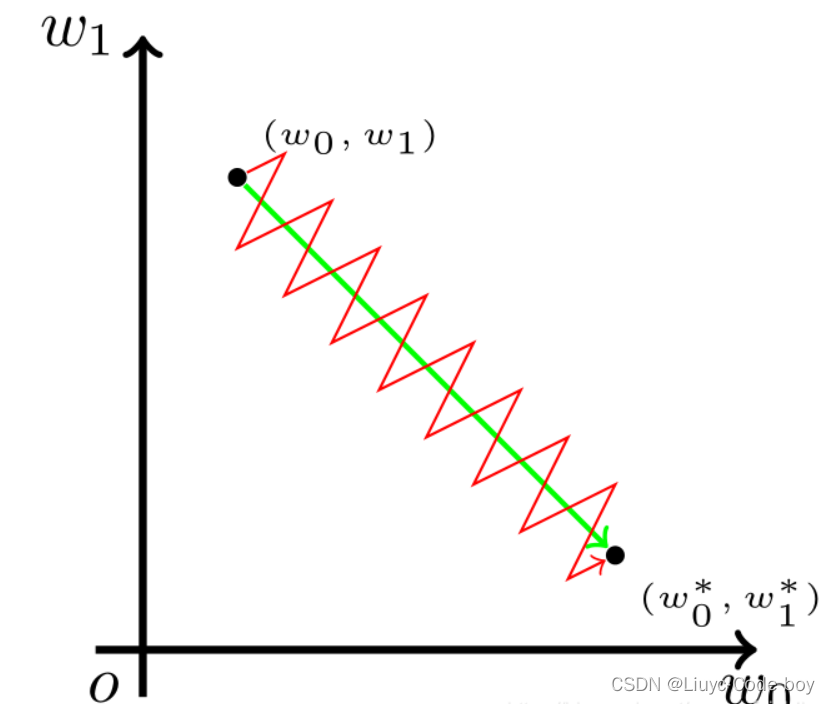 我们也可以通过一张图来了解原始数据分布、零均值化数据分布、归一化数据分布的区别:
我们也可以通过一张图来了解原始数据分布、零均值化数据分布、归一化数据分布的区别: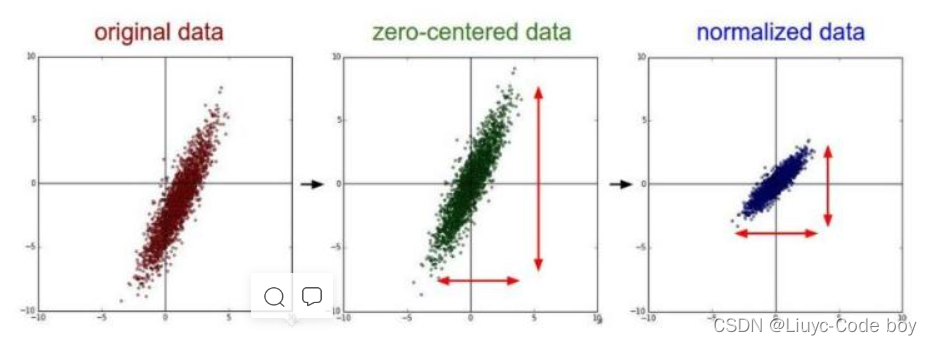
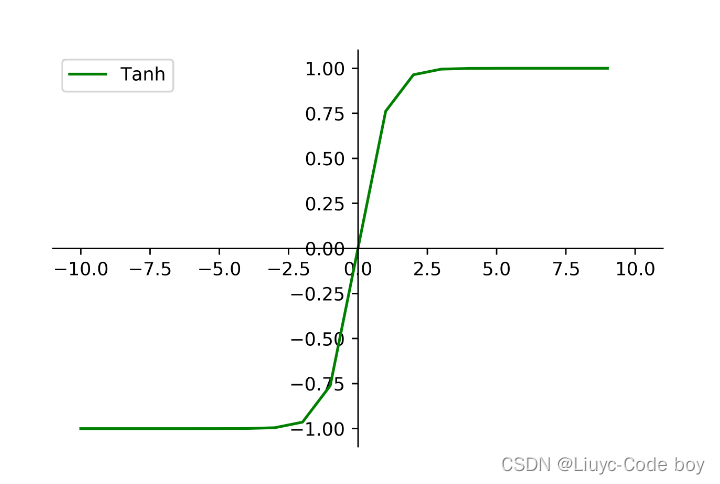 我们看图像就可以发现他解决了Sigmoid函数的非零均值的输出问题。
我们看图像就可以发现他解决了Sigmoid函数的非零均值的输出问题。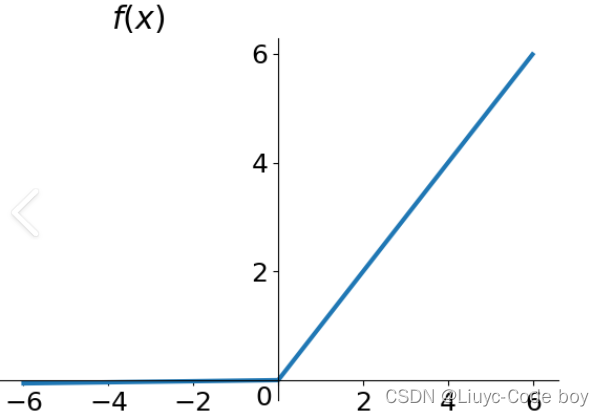 很简单的可以看出来Relu函数就是一个取最大值的函数,注意这并不是全区间可导,但是可以使用sub-gradient。我们发现Relu也没有解决零均值化的问题,但是由于①在正区间解决了grandient vanishing问题②计算速度非常快,只需要判断输入是否大于零③收敛速度远快于sigmoid和tanh,等以上优点所以Relu是目前最常用的activation function,我们在搭建神经网络的时候我们可以优先尝试Relu函数作为激活函数,相信你会有不错的体验。
很简单的可以看出来Relu函数就是一个取最大值的函数,注意这并不是全区间可导,但是可以使用sub-gradient。我们发现Relu也没有解决零均值化的问题,但是由于①在正区间解决了grandient vanishing问题②计算速度非常快,只需要判断输入是否大于零③收敛速度远快于sigmoid和tanh,等以上优点所以Relu是目前最常用的activation function,我们在搭建神经网络的时候我们可以优先尝试Relu函数作为激活函数,相信你会有不错的体验。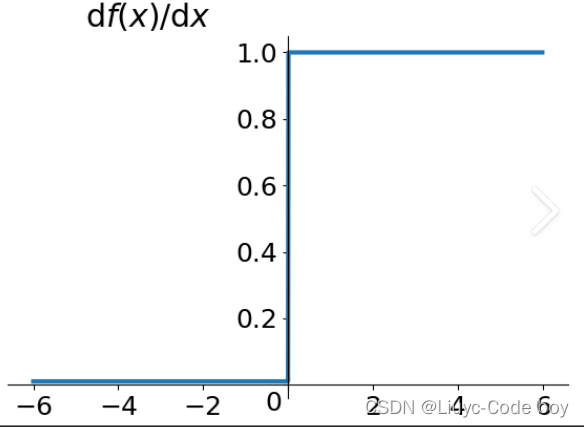
【本文地址】
今日新闻 |
推荐新闻 |