常用去除离群值的算法! |
您所在的位置:网站首页 › 如何检测离群值 › 常用去除离群值的算法! |
常用去除离群值的算法!
|
1.引言: 数据预处理的方法主要包括去极值、标准化、中性化。那么这里介绍几个常用的去离群值的方法,所谓离群值就是异常值,这个和极值其实并不一样。常用的剔除离群值的方法有MAD、 2.MAD算法 MAD,即median absolute deviation,可译为绝对中位值偏差。其大致思想是通过判断每一个元素与中位值的偏差是否处于合理的范围内来判断该元素是否为离群值。具体方法如下: (1)计算所有元素的中位值: (2)计算所有元素与中位值的绝对偏差: (3)取得绝对偏差的中位值: (4)确定参数n,则可以对所有的数据作如下调整:
在这里我没有调整离群值,而是直接将其剔除了。 代码如下: import numpy as np # MAD法: media absolute deviation def MAD(dataset, n): median = np.median(dataset) # 中位数 deviations = abs(dataset - median) mad = np.median(deviations) remove_idx = np.where(abs(dataset - median) > n * mad) new_data = np.delete(dataset, remove_idx) return new_data2. 3.百分位法 百分位计算的逻辑是将因子值进行升序的排序,对排位百分位高于97.5%或排位百分位低于2.5%的因子值,类似于比赛中”去掉几个最高分,去掉几个最低分“的做法。代码如下:这里参数采用的是20%和80%,具体取值,还需具体情况具体分析。 # 百分位法:原始参数 min=0.025, max=0.975 def percent_range(dataset, min= 0.20, max= 0.80): range_max = np.percentile(dataset, max * 100) range_min = -np.percentile(-dataset, (1 - min) * 100) # 剔除前20%和后80%的数据 new_data = [] for value in dataset: if value < range_max and value > range_min: new_data.append(value) return new_data这三个方法思路简单,易于实现,但是只能处理一维数据,接下来,再考虑更复杂但却更精准的可适用于多维数据的离群值处理方法!参考资料:离群点检测---基于kNN的离群点检测、LOF算法和CLOF算法 |
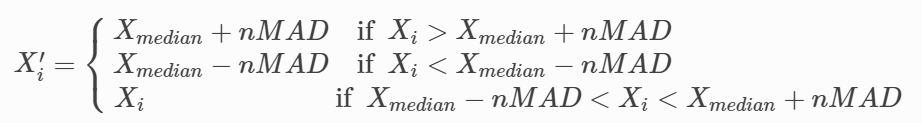
【本文地址】
今日新闻 |
推荐新闻 |