Neural Renderer神经网络渲染器:3D模型渲染 |
您所在的位置:网站首页 › 3d多角度渲染怎么调 › Neural Renderer神经网络渲染器:3D模型渲染 |
Neural Renderer神经网络渲染器:3D模型渲染
|
文章目录
简介一、Neural Renderer神经网络渲染器安装二、数据集介绍3D模型文件face文件carla数据集
三、代码实现参数设置读取.obj文件计算待渲染纹理信息neural renderer 相机参数设置函数get_params进行渲染添加背景结果展示
总结
简介
本篇文章利用Neural Renderer神经网络渲染器实现3D模型渲染的任务 (主要即复现论文FCA: Learning a 3D Full-coverage Vehicle Camouflage for Multi-view Physical Adversarial Attack中的渲染工作) 一、Neural Renderer神经网络渲染器安装关于Neural Renderer神经网络渲染器的安装方法以下文章有详细讲解,可供参考: Neural Renderer神经网络渲染器安装 二、数据集介绍 3D模型文件.obj文件 包含3d模型的vertices(顶点)、faces(面片)、textures(纹理)信息,用于后续传递给neural renderer做渲染 face文件.txt文件 包含3d模型可供渲染的faces(面片)id号 carla数据集该数据集包含了15500组数据,数据集结构如下所示: |-- masks |-- phy_attack | |-- train | |-- test其中: masks文件夹中包含15500张图片,为车辆的mask掩码,如下图所示: veh_trans: 2 ∗ 3 2*3 2∗3的矩阵,包含车辆位置参数、欧拉角参数 cam_trans: 2 ∗ 3 2*3 2∗3的矩阵,相机位置参数、欧拉角参数 数据集已放于以下链接,有需要可自行下载 谷歌云盘 百度网盘(dual) 数据集较大,为便于学习,本文只选用一组图片,若无需使用全部数据集可直接使用后文完整代码链接处的文件 三、代码实现 参数设置step1.设置.obj文件路径 step2.设置.txt文件路径 step3.设置.npz文件路径 step4.设置mask文件路径 # 参数设置 parser = argparse.ArgumentParser() parser.add_argument('--filename_obj', type=str, default='audi_et_te.obj') parser.add_argument('--filename_face', type=str, default='exterior_face.txt') parser.add_argument('--filename_npz', type=str, default='data1.npz') parser.add_argument('--filename_mask', type=str, default='data1.png') parser.add_argument('--texture_size', type=int, default=2) args = parser.parse_args() 读取.obj文件step1.使用neural renderer中load_obj函数读取.obj文件 # 加载obj(顶点、面片、贴图) print('load obj file...') vertices, faces, texture_origin = nr.load_obj(filename_obj=args.filename_obj, texture_size=2, load_texture=True) 计算待渲染纹理信息step1.随机初始化纹理信息 step2.加载可渲染面片的id,并创建纹理mask掩码 step3.数据置于gpu step3.利用纹理mask掩码计算最终待渲染的纹理信息 print('create texture...') texture_size = args.texture_size texture_param = torch.rand(faces.shape[0], texture_size, texture_size, texture_size, 3) print('load faces which can be painted...') texture_mask = torch.zeros(faces.shape[0], texture_size, texture_size, texture_size, 3) with open(args.filename_face) as f: faces_id = f.readlines() for face_id in faces_id: if face_id != '\n': texture_mask[int(face_id)-1, :, :, :, :] = 1 print('to gpu...') texture_origin = texture_origin.cuda() texture_mask = texture_mask.cuda() texture_param = texture_param.cuda() print('compute new textures...') textures = texture_origin * (1 - texture_mask) + texture_param * texture_mask textures = textures[None,:,:,:,:,:] vertices = vertices[None, :, :] faces = faces[None, :, :] neural renderer 相机参数设置step1.加载.npz文件 step2.读取车辆与相机参数 step3.将车辆与相机参数转换为neural renderer需要的相机参数,下图展示了部分参数的含义 转换函数get_params讲解见后文 函数get_params讲解如下: (个人理解,如有误烦请读者批评指正) 世界坐标系与机体坐标系的转换原理可参考此文章 def get_params(carlaTcam, carlaTveh): # carlaTcam: tuple of 2*3 scale = 0.40 # 比例 # scale = 0.38 # calc eye eye = [0, 0, 0] for i in range(0, 3): # 读取相机位置参数 # eye[i] = (carlaTcam[0][i] - carlaTveh[0][i]) * scale eye[i] = carlaTcam[0][i] * scale # calc camera_direction and camera_up # 欧拉角 pitch = math.radians(carlaTcam[1][0]) # 绕y轴旋转角度 yaw = math.radians(carlaTcam[1][1]) # 绕z轴旋转角度 roll = math.radians(carlaTcam[1][2]) # 绕x轴旋转角度 cam_direct = [math.cos(pitch) * math.cos(yaw), math.cos(pitch) * math.sin(yaw), math.sin(pitch)] # 相机在相机坐标系的方向 cam_up = [math.cos(math.pi / 2 + pitch) * math.cos(yaw), math.cos(math.pi / 2 + pitch) * math.sin(yaw), # 相机顶部在相机坐标系的方向 math.sin(math.pi / 2 + pitch)] # 如果物体也有旋转,则需要调整相机位置和角度,和物体旋转方式一致(坐标系变换) # 先实现最简单的绕Z轴旋转 p_cam = eye p_dir = [eye[0] + cam_direct[0], eye[1] + cam_direct[1], eye[2] + cam_direct[2]] # 相机在世界坐标系的方向 p_up = [eye[0] + cam_up[0], eye[1] + cam_up[1], eye[2] + cam_up[2]] # 相机顶部在世界坐标系的方向 p_l = [p_cam, p_dir, p_up] # 绕z轴 trans_p = [] for p in p_l: if math.sqrt(p[0] ** 2 + p[1] ** 2) == 0: cosfi = 0 sinfi = 0 else: cosfi = p[0] / math.sqrt(p[0] ** 2 + p[1] ** 2) sinfi = p[1] / math.sqrt(p[0] ** 2 + p[1] ** 2) cossum = cosfi * math.cos(math.radians(carlaTveh[1][1])) + sinfi * math.sin(math.radians(carlaTveh[1][1])) sinsum = math.cos(math.radians(carlaTveh[1][1])) * sinfi - math.sin(math.radians(carlaTveh[1][1])) * cosfi trans_p.append([math.sqrt(p[0] ** 2 + p[1] ** 2) * cossum, math.sqrt(p[0] ** 2 + p[1] ** 2) * sinsum, p[2]]) # 绕x轴 trans_p2 = [] for p in trans_p: if math.sqrt(p[1] ** 2 + p[2] ** 2) == 0: cosfi = 0 sinfi = 0 else: cosfi = p[1] / math.sqrt(p[1] ** 2 + p[2] ** 2) sinfi = p[2] / math.sqrt(p[1] ** 2 + p[2] ** 2) cossum = cosfi * math.cos(math.radians(carlaTveh[1][2])) + sinfi * math.sin(math.radians(carlaTveh[1][2])) sinsum = math.cos(math.radians(carlaTveh[1][2])) * sinfi - math.sin(math.radians(carlaTveh[1][2])) * cosfi trans_p2.append([p[0], math.sqrt(p[1] ** 2 + p[2] ** 2) * cossum, math.sqrt(p[1] ** 2 + p[2] ** 2) * sinsum]) # 绕y轴 trans_p3 = [] for p in trans_p2: if math.sqrt(p[0] ** 2 + p[2] ** 2) == 0: cosfi = 0 sinfi = 0 else: cosfi = p[0] / math.sqrt(p[0] ** 2 + p[2] ** 2) sinfi = p[2] / math.sqrt(p[0] ** 2 + p[2] ** 2) cossum = cosfi * math.cos(math.radians(carlaTveh[1][0])) + sinfi * math.sin(math.radians(carlaTveh[1][0])) sinsum = math.cos(math.radians(carlaTveh[1][0])) * sinfi - math.sin(math.radians(carlaTveh[1][0])) * cosfi trans_p3.append([math.sqrt(p[0] ** 2 + p[2] ** 2) * cossum, p[1], math.sqrt(p[0] ** 2 + p[2] ** 2) * sinsum]) trans_p = trans_p3 # camera_direction与camera_up参数转换至相机坐标系 return trans_p[0], \ [trans_p[1][0] - trans_p[0][0], trans_p[1][1] - trans_p[0][1], trans_p[1][2] - trans_p[0][2]], \ [trans_p[2][0] - trans_p[0][0], trans_p[2][1] - trans_p[0][1], trans_p[2][2] - trans_p[0][2]] 进行渲染step1.将顶点、面片、纹理信息传入neural renderer,将得到根据所设定的相机参数拍摄得到的图片 images, _, _ = render(vertices, faces, textures) 添加背景step1.读取图片mask掩码 step2.resize至统一大小 step3.组合得到最终图片 step4.保存结果 img_mask = cv2.imread(args.filename_mask) img_mask = cv2.resize(img_mask, (images[0].shape[1],images[0].shape[1])) img = cv2.resize(img, (images[0].shape[1],images[0].shape[1])) tool = transforms.ToTensor() img = tool(img).cuda() img_mask = tool(img_mask).cuda() final_img = img_mask * images[0] + (1-img_mask) * img tool = transforms.ToPILImage() outcome = np.asarray(tool(final_img)) cv2.imwrite('./outcome.png', outcome) print('end...') 结果展示
以上就是利用Neural Renderer神经网络渲染器实现3D模型渲染的介绍,完整代码如下,项目完整代码链接处可供下载(无需积分,包含所需的.obj、.txt文件): import neural_renderer as nr import argparse import numpy as np import torch import torchvision.transforms as transforms import cv2 import math def get_params(carlaTcam, carlaTveh): # carlaTcam: tuple of 2*3 scale = 0.40 # scale = 0.38 # calc eye eye = [0, 0, 0] for i in range(0, 3): # eye[i] = (carlaTcam[0][i] - carlaTveh[0][i]) * scale eye[i] = carlaTcam[0][i] * scale # calc camera_direction and camera_up # 欧拉角 pitch = math.radians(carlaTcam[1][0]) yaw = math.radians(carlaTcam[1][1]) roll = math.radians(carlaTcam[1][2]) cam_direct = [math.cos(pitch) * math.cos(yaw), math.cos(pitch) * math.sin(yaw), math.sin(pitch)] # 相机在相机坐标系的方向 cam_up = [math.cos(math.pi / 2 + pitch) * math.cos(yaw), math.cos(math.pi / 2 + pitch) * math.sin(yaw), # 相机顶部在相机坐标系的方向 math.sin(math.pi / 2 + pitch)] # 如果物体也有旋转,则需要调整相机位置和角度,和物体旋转方式一致 # 先实现最简单的绕Z轴旋转 p_cam = eye p_dir = [eye[0] + cam_direct[0], eye[1] + cam_direct[1], eye[2] + cam_direct[2]] # 相机在世界坐标系的方向 p_up = [eye[0] + cam_up[0], eye[1] + cam_up[1], eye[2] + cam_up[2]] # 相机顶部在世界坐标系的方向 p_l = [p_cam, p_dir, p_up] # 绕z轴 trans_p = [] for p in p_l: if math.sqrt(p[0] ** 2 + p[1] ** 2) == 0: cosfi = 0 sinfi = 0 else: cosfi = p[0] / math.sqrt(p[0] ** 2 + p[1] ** 2) sinfi = p[1] / math.sqrt(p[0] ** 2 + p[1] ** 2) cossum = cosfi * math.cos(math.radians(carlaTveh[1][1])) + sinfi * math.sin(math.radians(carlaTveh[1][1])) sinsum = math.cos(math.radians(carlaTveh[1][1])) * sinfi - math.sin(math.radians(carlaTveh[1][1])) * cosfi trans_p.append([math.sqrt(p[0] ** 2 + p[1] ** 2) * cossum, math.sqrt(p[0] ** 2 + p[1] ** 2) * sinsum, p[2]]) # 绕x轴 trans_p2 = [] for p in trans_p: if math.sqrt(p[1] ** 2 + p[2] ** 2) == 0: cosfi = 0 sinfi = 0 else: cosfi = p[1] / math.sqrt(p[1] ** 2 + p[2] ** 2) sinfi = p[2] / math.sqrt(p[1] ** 2 + p[2] ** 2) cossum = cosfi * math.cos(math.radians(carlaTveh[1][2])) + sinfi * math.sin(math.radians(carlaTveh[1][2])) sinsum = math.cos(math.radians(carlaTveh[1][2])) * sinfi - math.sin(math.radians(carlaTveh[1][2])) * cosfi trans_p2.append([p[0], math.sqrt(p[1] ** 2 + p[2] ** 2) * cossum, math.sqrt(p[1] ** 2 + p[2] ** 2) * sinsum]) # 绕y轴 trans_p3 = [] for p in trans_p2: if math.sqrt(p[0] ** 2 + p[2] ** 2) == 0: cosfi = 0 sinfi = 0 else: cosfi = p[0] / math.sqrt(p[0] ** 2 + p[2] ** 2) sinfi = p[2] / math.sqrt(p[0] ** 2 + p[2] ** 2) cossum = cosfi * math.cos(math.radians(carlaTveh[1][0])) + sinfi * math.sin(math.radians(carlaTveh[1][0])) sinsum = math.cos(math.radians(carlaTveh[1][0])) * sinfi - math.sin(math.radians(carlaTveh[1][0])) * cosfi trans_p3.append([math.sqrt(p[0] ** 2 + p[2] ** 2) * cossum, p[1], math.sqrt(p[0] ** 2 + p[2] ** 2) * sinsum]) trans_p = trans_p3 return trans_p[0], \ [trans_p[1][0] - trans_p[0][0], trans_p[1][1] - trans_p[0][1], trans_p[1][2] - trans_p[0][2]], \ [trans_p[2][0] - trans_p[0][0], trans_p[2][1] - trans_p[0][1], trans_p[2][2] - trans_p[0][2]] def main(): # 参数设置 parser = argparse.ArgumentParser() parser.add_argument('--filename_obj', type=str, default='audi_et_te.obj') parser.add_argument('--filename_face', type=str, default='exterior_face.txt') parser.add_argument('--filename_npz', type=str, default='data1.npz') parser.add_argument('--filename_mask', type=str, default='data1.png') parser.add_argument('--texture_size', type=int, default=2) args = parser.parse_args() # 加载obj(顶点、面片、贴图) print('load obj file...') vertices, faces, texture_origin = nr.load_obj(filename_obj=args.filename_obj, texture_size=2, load_texture=True) print('create texture...') texture_size = args.texture_size texture_param = torch.rand(faces.shape[0], texture_size, texture_size, texture_size, 3) print('load faces which can be painted...') texture_mask = torch.zeros(faces.shape[0], texture_size, texture_size, texture_size, 3) with open(args.filename_face) as f: faces_id = f.readlines() for face_id in faces_id: if face_id != '\n': texture_mask[int(face_id)-1, :, :, :, :] = 1 print('to gpu...') texture_origin = texture_origin.cuda() texture_mask = texture_mask.cuda() texture_param = texture_param.cuda() print('compute new textures...') textures = texture_origin * (1 - texture_mask) + texture_param * texture_mask textures = textures[None,:,:,:,:,:] vertices = vertices[None, :, :] faces = faces[None, :, :] print('begin renderer...') data = np.load(args.filename_npz) # camera param img, veh_trans, cam_trans = data['img'], data['veh_trans'], data['cam_trans'] eye, camera_direction, camera_up = get_params(cam_trans, veh_trans) render = nr.Renderer(camera_mode='look_at', image_size=640) render.eye = eye render.camera_direction = camera_direction render.camera_up = camera_up render.background_color = [1,1,1] render.viewing_angle = 45 render.light_direction = [0, 0, 1] images, _, _ = render(vertices, faces, textures) img_mask = cv2.imread(args.filename_mask) img_mask = cv2.resize(img_mask, (images[0].shape[1],images[0].shape[1])) img = cv2.resize(img, (images[0].shape[1],images[0].shape[1])) tool = transforms.ToTensor() img = tool(img).cuda() img_mask = tool(img_mask).cuda() final_img = img_mask * images[0] + (1-img_mask) * img tool = transforms.ToPILImage() outcome = np.asarray(tool(final_img)) cv2.imwrite('./outcome.png', outcome) print('end...') if __name__ == '__main__': main() |
 phy_attack文件夹中包含训练集和测试集,训练集中有12500组数据,测试集中有3000组数据 每组数据为一个data.npz文件,该文件中包含img、veh_trans、cam_trans三组参数,其中: img:采集得到的图片
phy_attack文件夹中包含训练集和测试集,训练集中有12500组数据,测试集中有3000组数据 每组数据为一个data.npz文件,该文件中包含img、veh_trans、cam_trans三组参数,其中: img:采集得到的图片 
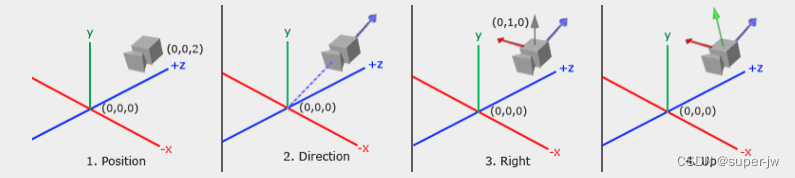 eye:相机位置 direction:拍摄方向 up:相机顶部方向
eye:相机位置 direction:拍摄方向 up:相机顶部方向
【本文地址】
今日新闻 |
推荐新闻 |