python实战之通过爬虫实现火车票查询 |
您所在的位置:网站首页 › 高铁车次名称怎么查 › python实战之通过爬虫实现火车票查询 |
python实战之通过爬虫实现火车票查询
|
前言: 学了挺近的python了,一直在初级徘徊不前,想着应该找点实战性的案例来操练一下,以便熟悉各模块的使用;在网上找到了一些有关通过爬虫实现火车票查询的,就拿来参考练练手了。 最终想要的实现效果就是用户通过在命令行输入相关的命令,然后将查询到的车次信息打印输出到屏幕上。命令格式:tickets [-gdtkz] ;并且用户可以通过输入[-gdtkz]参数去筛选想要查找的车次类型,默认不添加参数时候输出全部车次。此次用到的模块有docopt、prettytable、re、urllib3、requests,其中: docopt 模块:是在 python 中引入了一种针对命令行参数的形式语言模块,在代码的最开头使用 """ """ 文档注释的形式写出符合要求的文档,就会自动生成对应的 parse。 prettytable模块:是 python 中的一个第三方库,可用来生成美观的 ASCII 格式的表格,这里主要是用来将爬取到的车次信息按照 ASCII 格式打印到屏幕。 re模块:是python的标准库中表示正则表达式的模块,用来对爬取到的车次数据进行筛选匹配,得到我们最终想要的数据。 requests模块:是用 python 语言编写的基于 urllib 采用 Apache2 Licensed 开源协议的 HTTP 库,主要就是用它来获取12306网站车次信息。 urllib3模块:详解请参考 https://www.cnblogs.com/lincappu/p/12801817.html,这里是因为 requests 模块在访问 HTTPS 网站设置移除SSL认证参数 “verify=False” 后,会提示 “InsecureRequestWarning” 警告,在请求代码前加入 “requests.packages.urllib3.disable_warnings()” 就可以过滤警告。
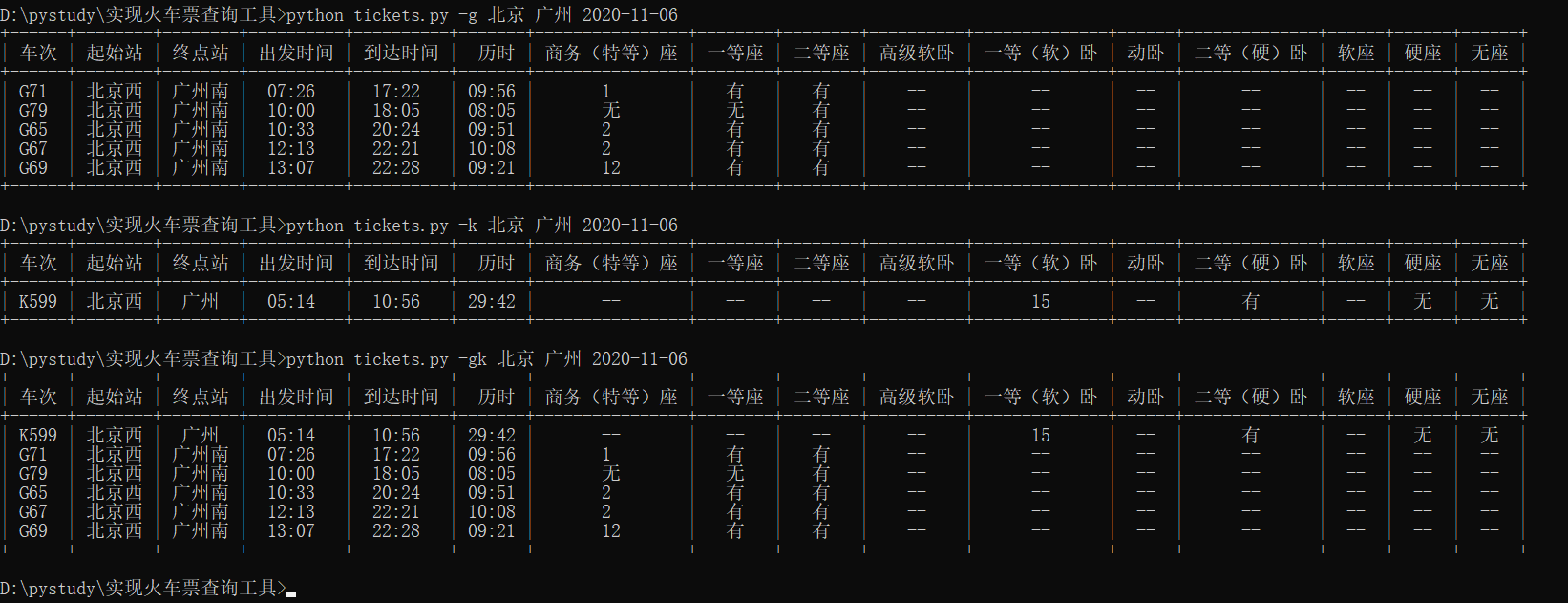
效果截图:
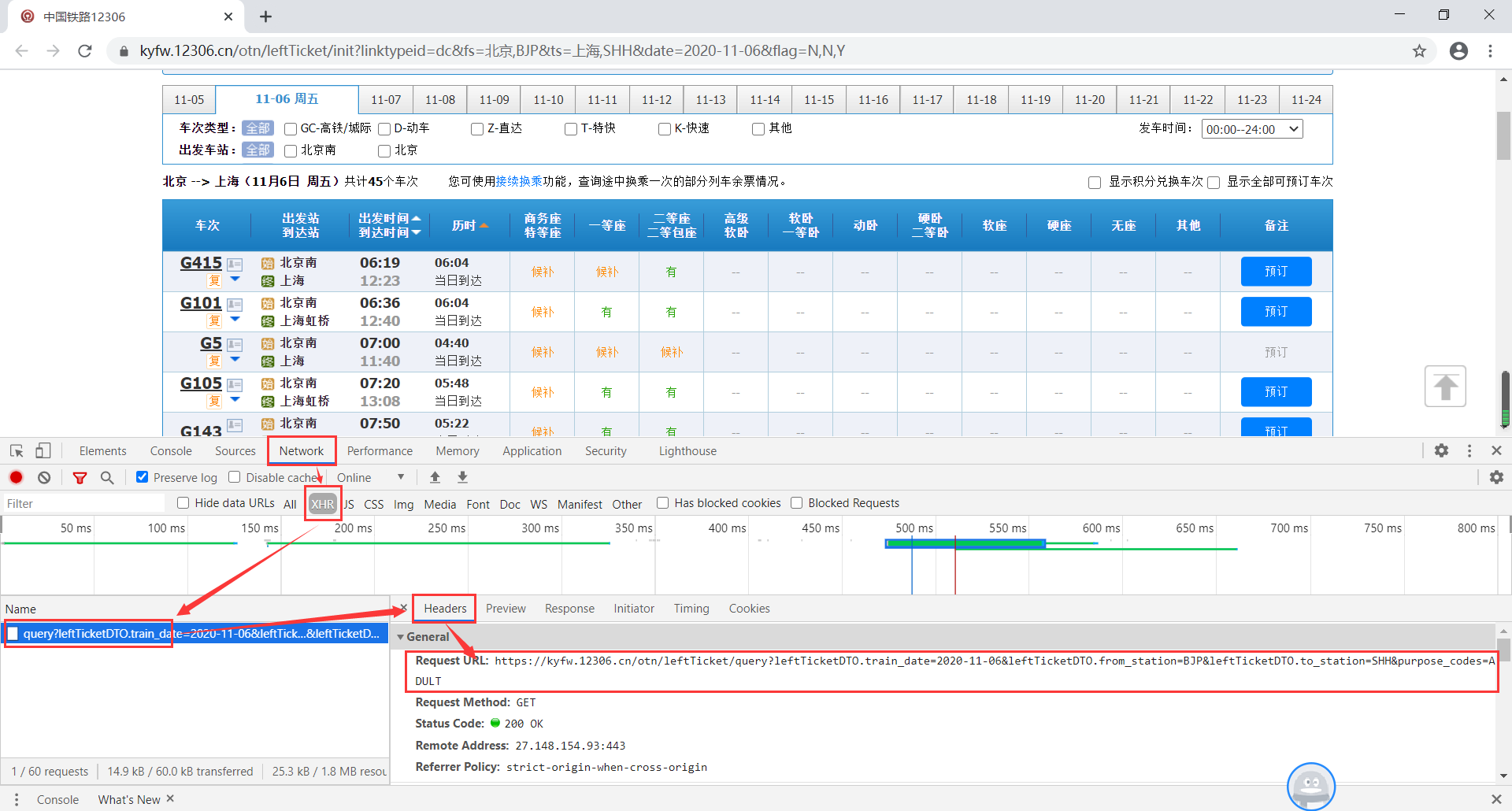
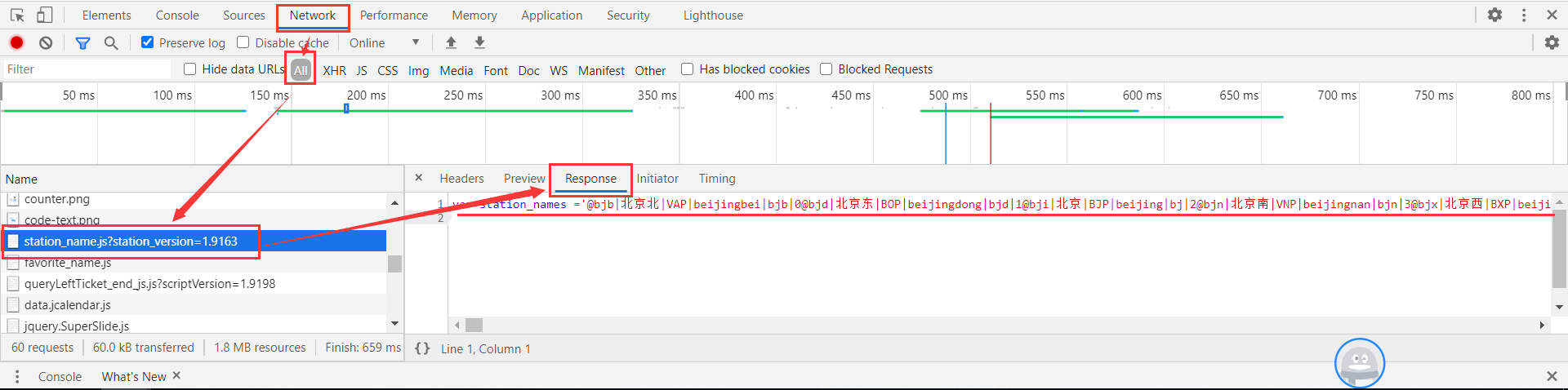
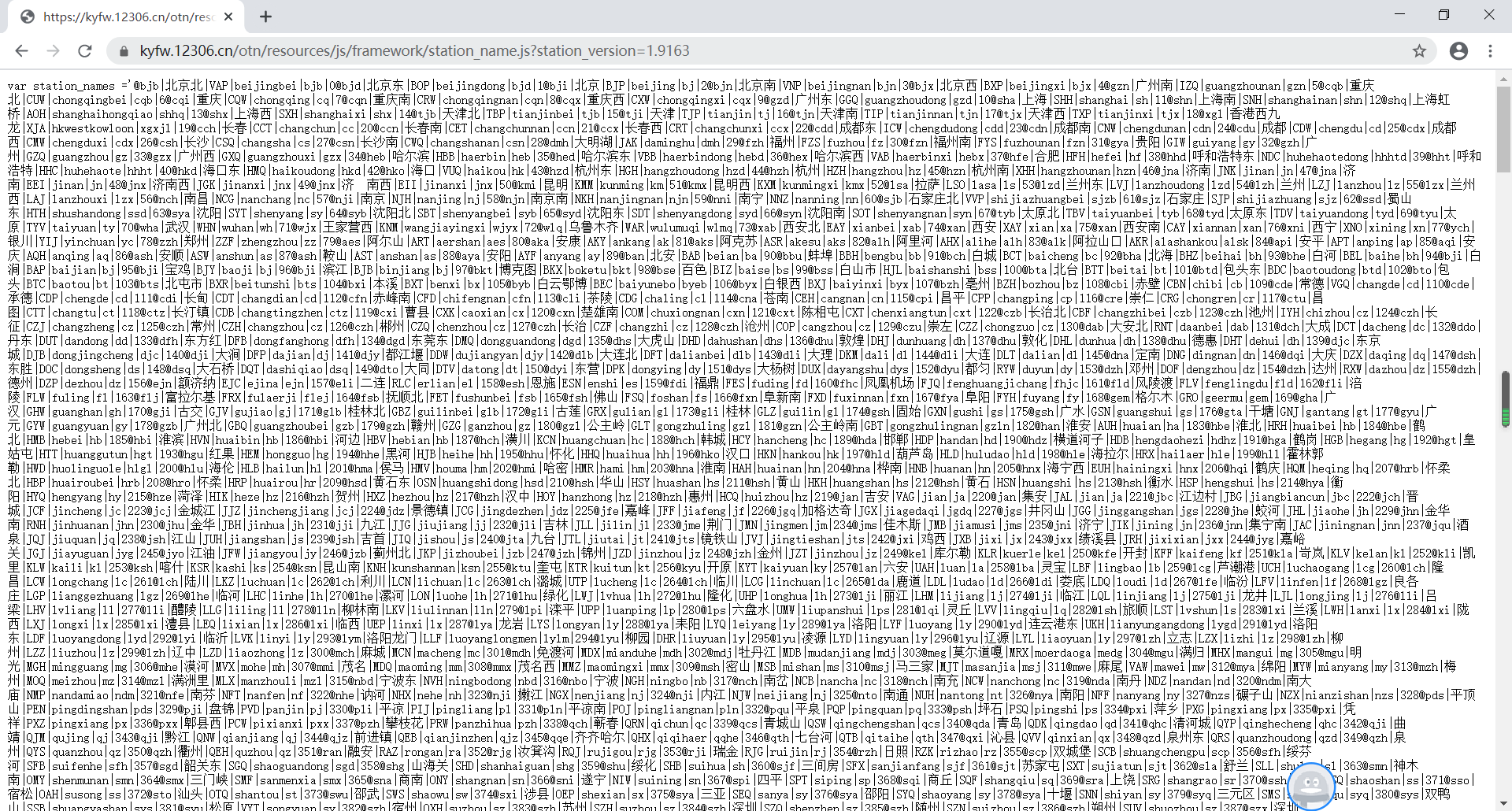
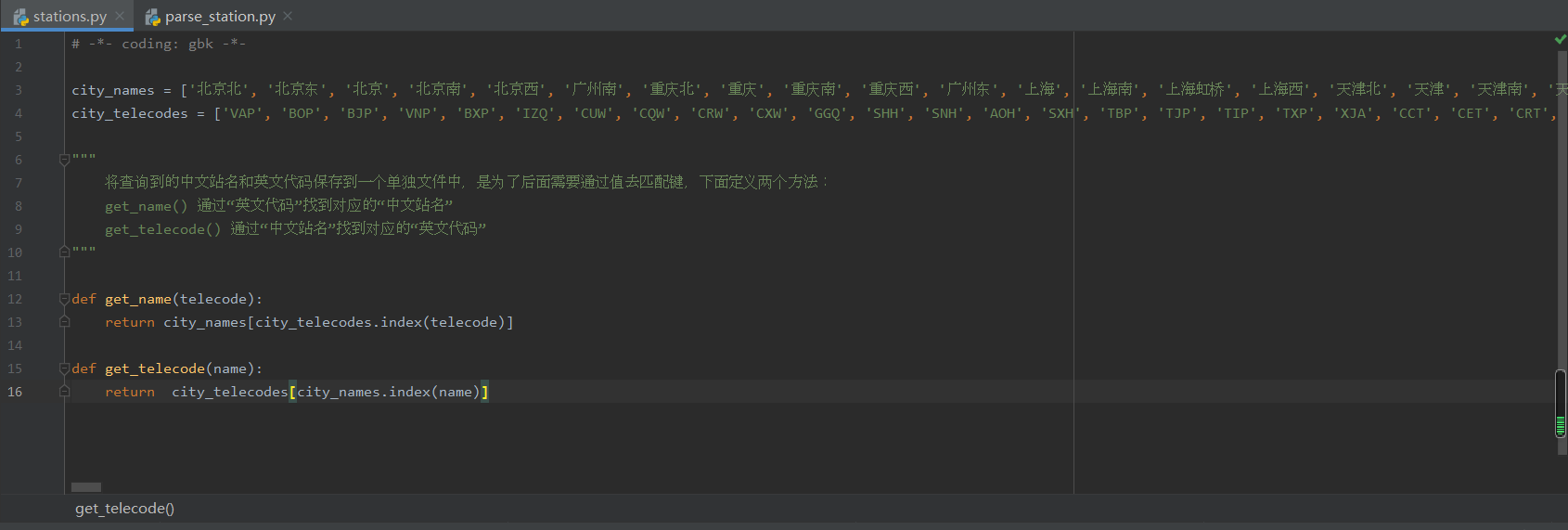
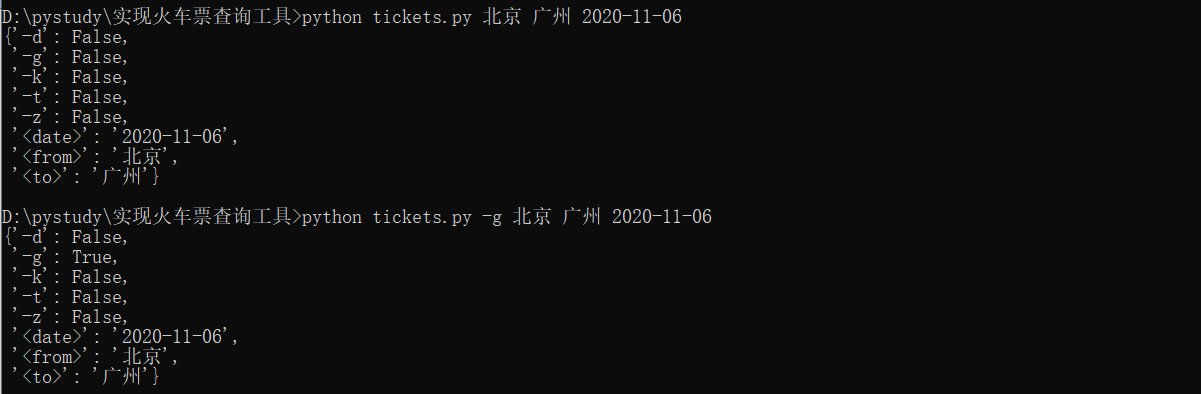
下面就来说一下实现的步骤: 打开12306网站查询北京到上海的火车票,并且开启浏览器开发者工具界面,然后找到“Network-XHR”选项,选中左下方框中的链接,其中右边“Headers”框下方中“Request URL”显示的链接就是我们要找的12306火车票查询URL。 将其复制出来分析发现,我们只需要修改train_date、from_station和to_station这三个固定参数的值就可以查询到我们想要的列车信息了,其中train_date是列车的日期,from_station和to_station分别是首发站和终点站,但是from_station和to_station的值却不是我们常见的中文车站名,分析对比后可以确定它是中文车站的英文编号。因此,我们需要先找到全部站点的英文编号数据。 经过查找12306页面发现“station_name.js?station_version=1.9163”行对应的“Response”数据应该是我们需要的数据。 那么我们就把“Headers”的“Request URL”链接地址复制出来贴到浏览器上去查看一下,看看是不是我们想要的数据。“https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9163” 查看了上面的数据,的确是我们想要的数据,并且这些数据是有一定的规律的,都是通过“|”分隔,这样我们在用正则去匹配想要的数据时候就比较容易了。好了,既然想要的数据都已经拿到了,那么我们就开始编写代码把我们想要的数据提取出来,下面我直接把代码和执行结果贴出来吧。 1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 4 import re 5 import urllib3, requests # python 访问 HTTP 资源的必备库 6 from pprint import pprint # 打印出任何python数据结构类和方法的模块 7 8 9 url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9163" 10 requests.packages.urllib3.disable_warnings() # requests模块在访问HTTPS网站时,如果设置移除SSL认证参数“verify=False”,执行代码是会提示“InsecureRequestWarning”警告,再请求页面时加入此段代码可以屏蔽掉警告信息 11 r = requests.get(url, verify=False) # 请求12306网站的所有城市的拼音和代号网页,verify=False参数表示不验证证书 12 # result = re.findall(r'([A-Z]+)\|([a-z]+)', r.text) # 通过正则表达式来匹配车站中文拼音和英文编号对应的数据 13 result = re.findall(r"([\u4e00-\u9fa5]+)\|([A-Z]+)", r.text) # 通过正则表达式来匹配车站中文名和英文编号对应的数据 14 stations = dict(result) # 将获取的数据转成字典 15 # print(stations["上海虹桥"]) # 验证用 16 """ 17 请将下面输出的结果保存到stations.py中,并在文件开头添加一行:# coding=gbk 18 否则在调用stations.py文件时,会提示报错。 19 """ 20 print(stations.keys()) 21 print(stations.values()) 执行结果如下: 随后将输出的数据保存到另一个文件(stations.py)中,在文件开头加上一句“# coding=gbk”,并在文件中定义两函数进行中文名字和英文编码的对应获取,如下: 车站中文名和英文编码已经拿到了,接下来就可以开始爬取12306网页的车次数据了,首先我们设计一下用户调用的接口方式。按照前面所说的我们希望用户只要输入出发站、终点站和出发日期就能获得想要的列车信息,例如要查看2020年11月6日的火车票信息,只需输入如下: $ tickets 北京 广州 2020-11-06对其进行抽象可以得到接口如下: $ tickets另外,我们在12306页面查询火车票时候可以对车次类型进行筛选,例如选择高铁就只显示当天高铁的车次信息,同时选择高铁和动车就显示高铁和动车的车次信息,那么我们就要提供一个选项来查询特定的一种或者几种类型的火车,所有我们应该有下面这些选项: -g 高铁 -d 动车 -t 特快 -k 快速 -z 直达将这些选项和上面的接口组合起来,最终的接口的样子应该是这样: $ tickets [-gdtkz]下面我们直接贴出实现的代码: 1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 4 #!/usr/bin/env python3 5 # -*- coding: utf-8 -*- 6 7 """Train tickets query via command-line. 8 9 Usage: 10 tickets [-gdtkz] 11 12 Options: 13 -h,--help 显示帮助信息菜单 14 -g 高铁 15 -d 动车 16 -t 特快 17 -k 快速 18 -z 直达 19 20 Example: 21 tickets beijing shanghai 2020-11-05 22 """ 23 24 from docopt import docopt 25 # docopt 模块是 python3 命令行参数解析工具 26 # docopt 模块本质上是在 Python 中引入了一种针对命令行参数的形式语言,在代码的最开头使用 """ """文档注释的形式写出符合要求的文档,就会自动生成对应的 parse 27 # 所有出现在 Usage:(区分大小写)和一个空行之间的文本都会被识别为一个命令组合, Usage 后的第一个字母将会被识别为这个程序的名字,所有命令组合的每一个部分(空格分隔)都会成为字典中的一个key 28 29 30 def cli(): 31 """command-line interface""" 32 arguments = docopt(__doc__) 33 print(arguments) 34 35 if __name__ == "__main__": 36 cli()通过命令行方式运行上面代码,得到结果如下: $ python tickets.py 北京 广州 2020-11-06 $ python tickets.py -g 北京 广州 2020-11-06
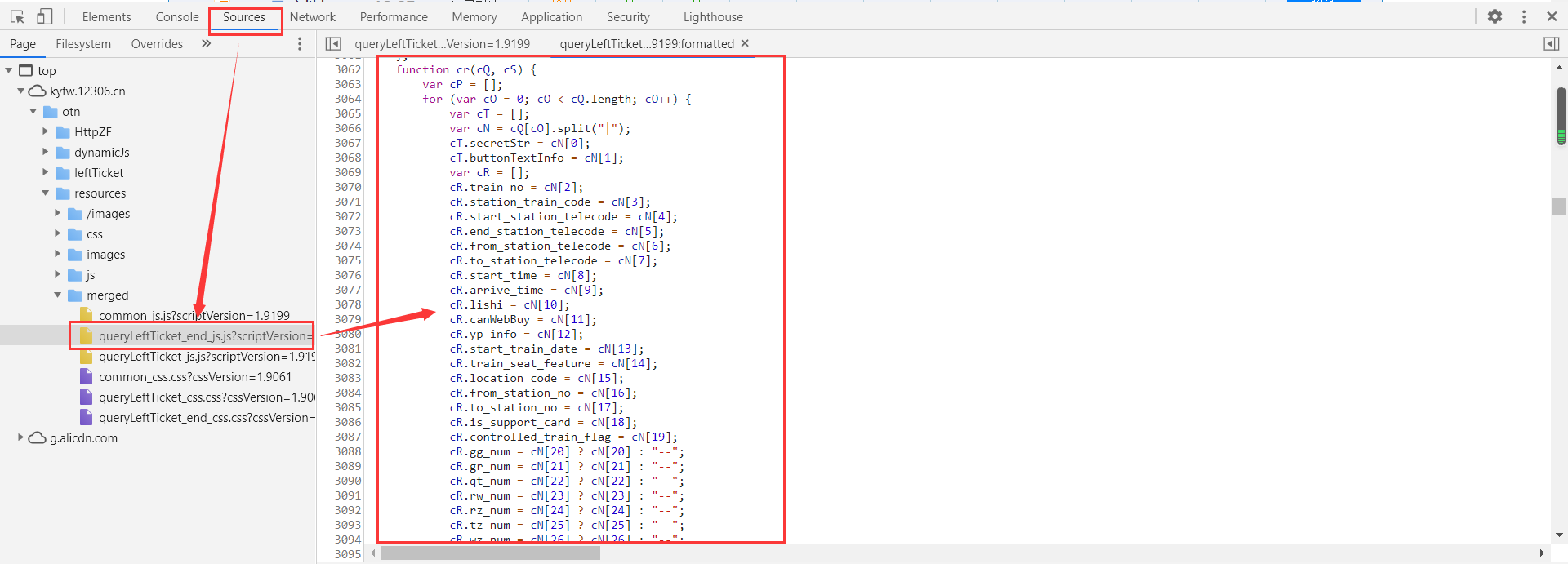
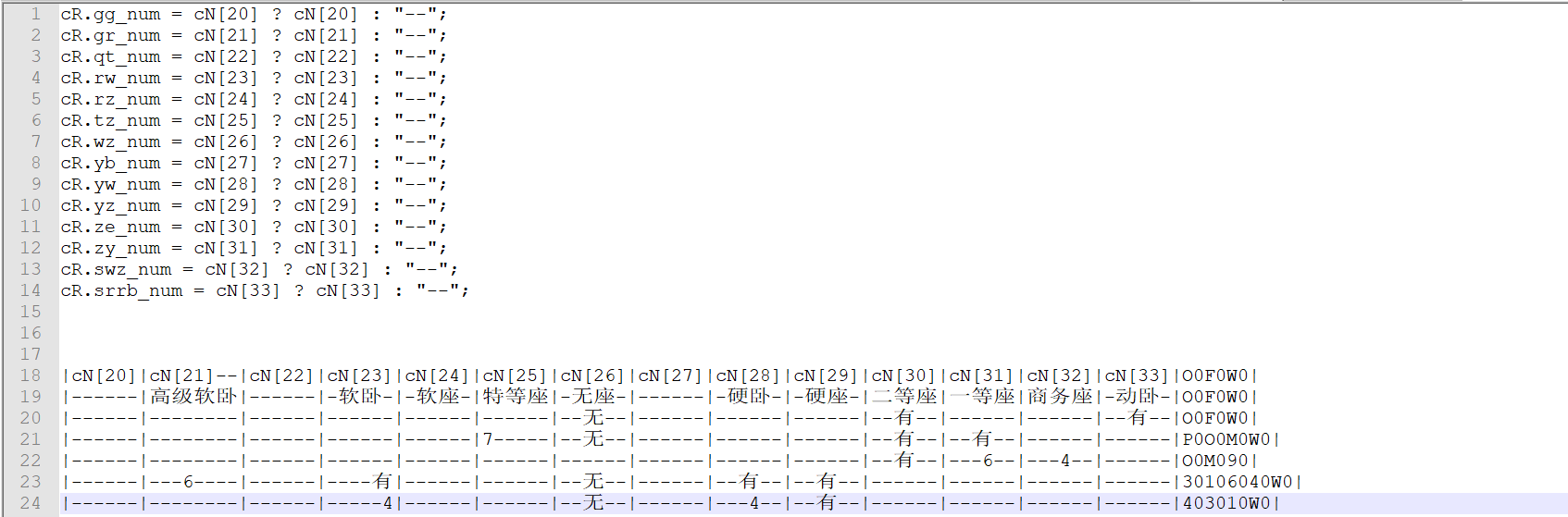
接口已经实现了,接下来就是要获取12306页面的车次数据了,根据前面分析的只需要修改“https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-11-06&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT”链接中train_date、from_station和to_station参数的值就可以得到想要查询的火车票信息。其中from_station和to_station参数的值是英文编号,需要根据用户输入的中文车站名去stations.py文件中找到对应的英文编号进行替换,因此需要import stations,然后通过requests模块去抓取车次数据。实现代码如下: 1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 4 #!/usr/bin/env python3 5 # -*- coding: utf-8 -*- 6 7 """Train tickets query via command-line. 8 9 Usage: 10 tickets [-gdtkz] 11 12 Options: 13 -h,--help 显示帮助信息菜单 14 -g 高铁 15 -d 动车 16 -t 特快 17 -k 快速 18 -z 直达 19 20 Example: 21 tickets beijing shanghai 2020-11-05 22 """ 23 24 from docopt import docopt 25 # docopt 模块是 python3 命令行参数解析工具 26 # docopt 模块本质上是在 Python 中引入了一种针对命令行参数的形式语言,在代码的最开头使用 """ """文档注释的形式写出符合要求的文档,就会自动生成对应的 parse 27 # 所有出现在 Usage:(区分大小写)和一个空行之间的文本都会被识别为一个命令组合, Usage 后的第一个字母将会被识别为这个程序的名字,所有命令组合的每一个部分(空格分隔)都会成为字典中的一个key 28 import re # 正则表达式模块 29 import stations 30 import urllib3, requests # python 访问 HTTP 资源的必备库 31 32 def cli(): 33 """command-line interface""" 34 arguments = docopt(__doc__) 35 # print(arguments) 36 from_stion = stations.get_telecode(arguments[""]) # 调用 get_telecode() 方法根据用户输入的起始车站中文名找到对应的英文编号 37 to_stion = stations.get_telecode(arguments[""]) # 调用 get_telecode() 方法根据用户输入的终点车站中文名找到对应的英文编号 38 date = arguments[""] # 获取用户输入的日期 39 40 # 构建 URL 41 url = ("https://kyfw.12306.cn/otn/leftTicket/query?" 42 "leftTicketDTO.train_date={}&" 43 "leftTicketDTO.from_station={}&" 44 "leftTicketDTO.to_station={}&" 45 "purpose_codes=ADULT").format(date, from_stion, to_stion) 46 headers = { 47 # Cookie 的值自行替换一下,可以通过打开浏览器开发者模式复制过来 48 "Cookie": "_uab_collina=160395250285657341202147; JSESSIONID=7C56E896658518A4E5BF99889839D00C; _jc_save_wfdc_flag=dc; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; BIGipServerotn=1725497610.50210.0000; RAIL_EXPIRATION=1604632917257; RAIL_DEVICEID=DeBrCMshZyD9JIK2yazJV4op0oxRXXKpeio_Y27U75ZkWKFwOd6Q_i2JRVBJeN3Q9qQ7ybyTw4Vv3ImAEwdTAAh8XLXL6WGn3irR65rZyYeWtvToLkq8oVAprmAw6OPgPnqI9a9ItALNr0kFjzDkncjjGPINbqfa; BIGipServerpassport=770179338.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_fromDate=2020-11-02; _jc_save_toDate=2020-11-01", 49 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36" 50 } 51 requests.packages.urllib3.disable_warnings() # 屏蔽 “InsecureRequestWarning” 警告 52 r = requests.get(url, headers=headers, verify=False) # 通过 requests 模块获取页面信息,verify=False 参数表示不进行证书验证 53 raw_trains = r.json()['data']['result'] 54 print(raw_trains) 55 56 57 if __name__ == "__main__": 58 cli() 执行结果如下: 根据获取到的数据进行分析其车次信息中车次代号、始发站、终点站、出发时间、到达时间以及座位类别等应该是有分别对应的字段,再返回12306网站去查找发现“Sources”有相关的数据信息,如下所示: 拿到这些信息之后,就开始和抓取到的车次数据以及12306页面显示的数据进行对比(这个过程是比较久的,需要有耐心)。我这边抓取了很多车次的数据信息进行了对比,其中需要注意的是“商务座”和“特等座”12306页面上虽然显示在一起的,但是“Sources”对应的数据字段却不是一样的(还有我猜测二等座和二等包座的字段也可能不是一样的,因为没有数据去做比较,后面就忽略掉了),下面是我对比出来的结果截图:
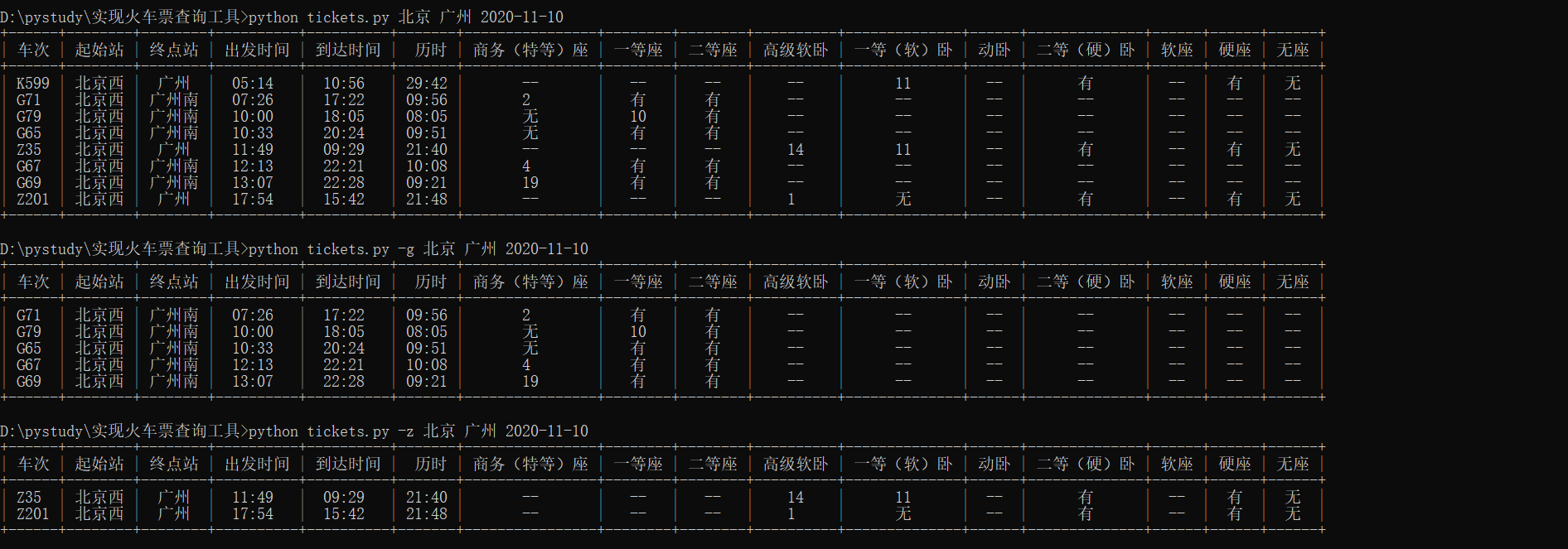
找到了车次信息对应的字段,就开始把数据编排成我们想要的格式吧。这里使用PrettyTable库来进行信息对齐表格美化(这个库要注意大小写),因为考虑到可以根据用户输入的参数“-gdtkz”来筛选车次数据,所有我们要通过用户的输入和火车类型进行判断,并定义一个filtrate_train()方法去筛选用户想查看相关的车次信息,下面是此次实战的全部代码: 1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 4 """Train tickets query via command-line. 5 6 Usage: 7 tickets [-gdtkz] 8 9 Options: 10 -h,--help 显示帮助信息菜单 11 -g 高铁 12 -d 动车 13 -t 特快 14 -k 快速 15 -z 直达 16 17 Example: 18 tickets 北京 上海 2020-10-29 19 """ 20 21 from docopt import docopt 22 # docopt 模块是 python3 命令行参数解析工具 23 # docopt 模块本质上是在 Python 中引入了一种针对命令行参数的形式语言,在代码的最开头使用 """ """文档注释的形式写出符合要求的文档,就会自动生成对应的 parse 24 # 所有出现在 Usage:(区分大小写)和一个空行之间的文本都会被识别为一个命令组合, Usage 后的第一个字母将会被识别为这个程序的名字,所有命令组合的每一个部分(空格分隔)都会成为字典中的一个key 25 from prettytable import PrettyTable 26 import re # 正则表达式模块 27 import stations 28 import urllib3, requests # python 访问 HTTP 资源的必备库 29 30 # 定义一个filtrate_train()函数,用来筛选查询到列车车次的数据 31 def filtrate_train(pt, data_list): 32 station_train_code = data_list[3] # 车次 33 from_station_code = data_list[6] # 起始站英文代号 34 to_station_code = data_list[7] # 终点站英文代号 35 from_station_name = stations.get_name(from_station_code) # 起始站中文名称 36 to_station_name = stations.get_name(to_station_code) # 终点站中文名称 37 start_time = data_list[8] # 出发时间 38 arrive_time = data_list[9] # 到达时间 39 lishi = data_list[10] # 历时 40 # 通过对比12306代码和页面上座位显示结果分析出“商务座”和“特等座”对应的参数是不同的,cN[25]是特等座,cN[32]是商务座 41 business_seat = data_list[25] or data_list[32] or "--" # 商务座和特等座 42 first_class_seat = data_list[31] or "--" # 一等座 43 second_class_seat = data_list[30] or "--" # 二等座,查看12306页面时,二等座下方有个“二等包座”,对比代码应该是cN[27],但是没有找到有对应数据暂时不写上去 44 advanced_soft_sleeper = data_list[21] or "--" # 高级软卧 45 soft_sleeper = data_list[23] or "--" # 软卧 46 bullet_sleeper = data_list[33] or "--" # 动卧 47 hard_sleeper = data_list[28] or "--" # 硬卧 48 soft_seat = data_list[24] or "--" # 软座,因为没有查询到有软座的信息,对比了代码参数,猜测cN[24]应该是软座 49 hard_seat = data_list[29] or "--" # 硬座 50 not_seat = data_list[26] or "--" # 无座 51 pt.add_row([ 52 station_train_code, # 车次 53 from_station_name, # 起始站中文名称 54 to_station_name, # 终点站中文名称 55 start_time, # 出发时间 56 arrive_time, # 到达时间 57 lishi, # 历时 58 business_seat, # 商务座和特等座 59 first_class_seat, # 一等座 60 second_class_seat, # 二等座 61 advanced_soft_sleeper, # 高级软卧 62 soft_sleeper, # 软卧 63 bullet_sleeper, # 动卧 64 hard_sleeper, # 硬卧 65 soft_seat, # 软座 66 hard_seat, # 硬座 67 not_seat # 无座 68 ]) 69 return pt 70 71 def cli(): 72 """command-line interface""" 73 arguments = docopt(__doc__) 74 from_stion = stations.get_telecode(arguments[""]) 75 to_stion = stations.get_telecode(arguments[""]) 76 date = arguments[""] 77 # print(from_stion, to_stion, date) 78 79 # 构建 URL 80 url = ("https://kyfw.12306.cn/otn/leftTicket/query?" 81 "leftTicketDTO.train_date={}&" 82 "leftTicketDTO.from_station={}&" 83 "leftTicketDTO.to_station={}&" 84 "purpose_codes=ADULT").format(date, from_stion, to_stion) 85 headers = { 86 # Cookie的值可以通过打开浏览器的开发者模式复制过来 87 "Cookie": "_uab_collina=160395250285657341202147; JSESSIONID=7C56E896658518A4E5BF99889839D00C; _jc_save_wfdc_flag=dc; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; BIGipServerotn=1725497610.50210.0000; RAIL_EXPIRATION=1604632917257; RAIL_DEVICEID=DeBrCMshZyD9JIK2yazJV4op0oxRXXKpeio_Y27U75ZkWKFwOd6Q_i2JRVBJeN3Q9qQ7ybyTw4Vv3ImAEwdTAAh8XLXL6WGn3irR65rZyYeWtvToLkq8oVAprmAw6OPgPnqI9a9ItALNr0kFjzDkncjjGPINbqfa; BIGipServerpassport=770179338.50215.0000; route=c5c62a339e7744272a54643b3be5bf64; _jc_save_fromDate=2020-11-02; _jc_save_toDate=2020-11-01", 88 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36" 89 } 90 requests.packages.urllib3.disable_warnings() 91 r = requests.get(url, headers=headers, verify=False) # verify=False参数表示不进行证书验证 92 raw_trains = r.json()['data']['result'] 93 # print(raw_trains) 94 pt = PrettyTable() 95 pt.field_names = '车次 起始站 终点站 出发时间 到达时间 历时 商务(特等)座 一等座 二等座 高级软卧 一等(软)卧 动卧 二等(硬)卧 软座 硬座 无座'.split() 96 # print(pt) 97 for raw_train in raw_trains: 98 data_list = raw_train.split("|") 99 if data_list[1] == "预订": # 因为有停运列车,需判定该车次列车是否可以预约 100 initial = data_list[3][0].lower() # 获取车次代号,g:高铁,d:动车,t:特快,k:快速,z:直达 101 if not arguments["-g"] and not arguments["-d"] and not arguments["-t"] and not arguments["-k"] and not arguments["-z"]: 102 filtrate_train(pt, data_list) 103 elif arguments["-g"] and initial == "g": 104 filtrate_train(pt, data_list) 105 elif arguments["-d"] and initial == "d": 106 filtrate_train(pt, data_list) 107 elif arguments["-t"] and initial == "t": 108 filtrate_train(pt, data_list) 109 elif arguments["-k"] and initial == "k": 110 filtrate_train(pt, data_list) 111 elif arguments["-z"] and initial == "z": 112 filtrate_train(pt, data_list) 113 print(pt) 114 115 if __name__ == "__main__": 116 cli()代码执行结果截图:
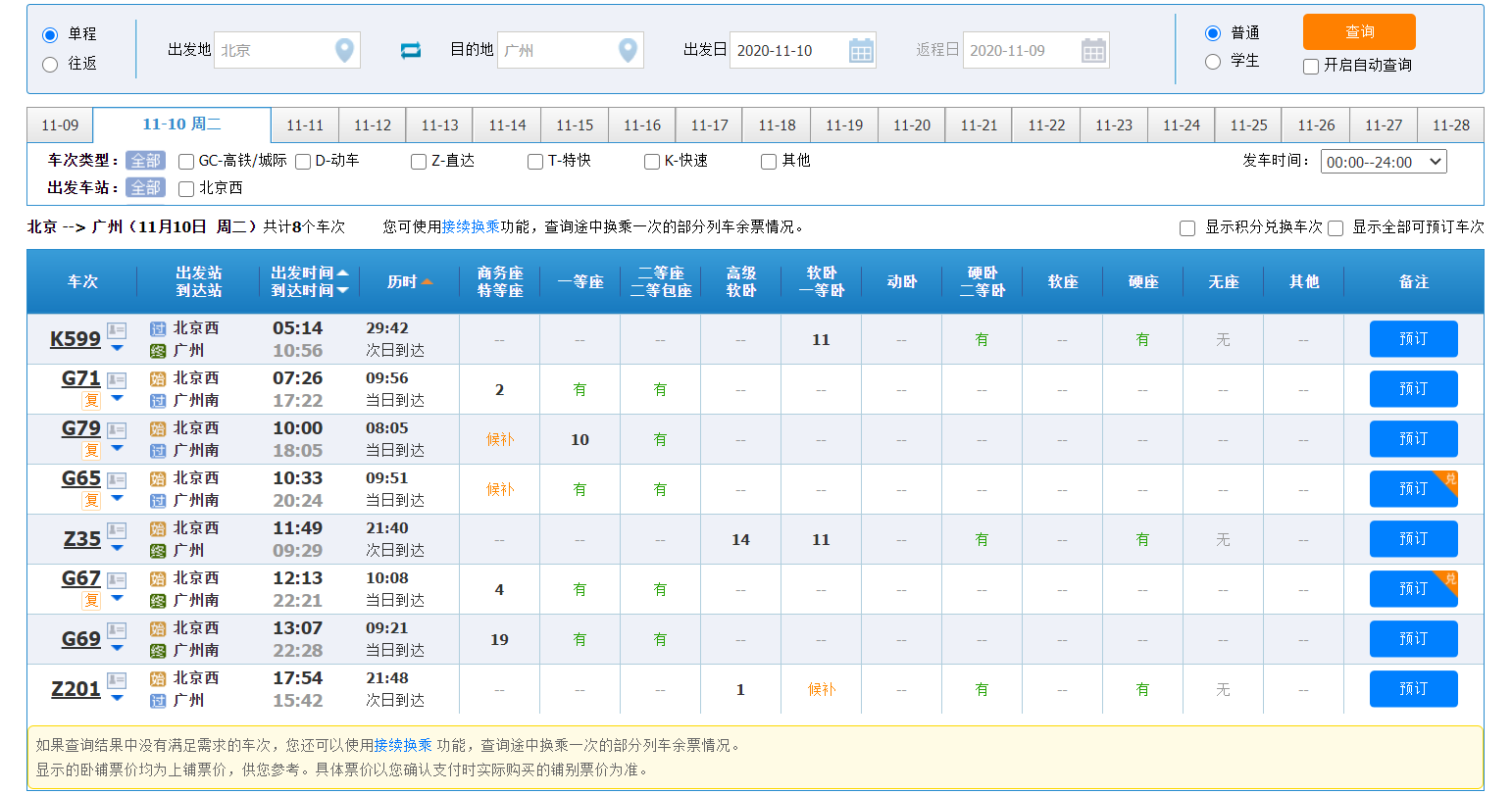
同时对比12306查询到的车次信息结果截图:
最后贴上参考链接:https://blog.csdn.net/qq_39380075/article/details/79841339?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v28-5-79841339.nonecase&utm_term=%E5%88%A9%E7%94%A8python%E5%AE%9E%E7%8E%B012306%E7%88%AC%E8%99%AB&spm=1000.2123.3001.4430 |


【本文地址】
今日新闻 |
推荐新闻 |