beautifulsoup爬虫应用之豆瓣电影top25爬取 |
您所在的位置:网站首页 › 豆瓣电影排名250名 › beautifulsoup爬虫应用之豆瓣电影top25爬取 |
beautifulsoup爬虫应用之豆瓣电影top25爬取
|
BeautifulSoup爬虫应用之豆瓣电影TOP25爬取
BeautifulSoup介绍
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间. 豆瓣电影喜欢看电影的小伙伴一定都听说过豆瓣评分 那什么是豆瓣电影TOP250呢? 下面给出该榜单的介绍:豆瓣用户每天都在对“看过”的电影进行“很差”到“力荐”的评价,豆瓣根据每部影片看过的人数以及该影片所得的评价等综合数据,通过算法分析产生豆瓣电影 Top 250。
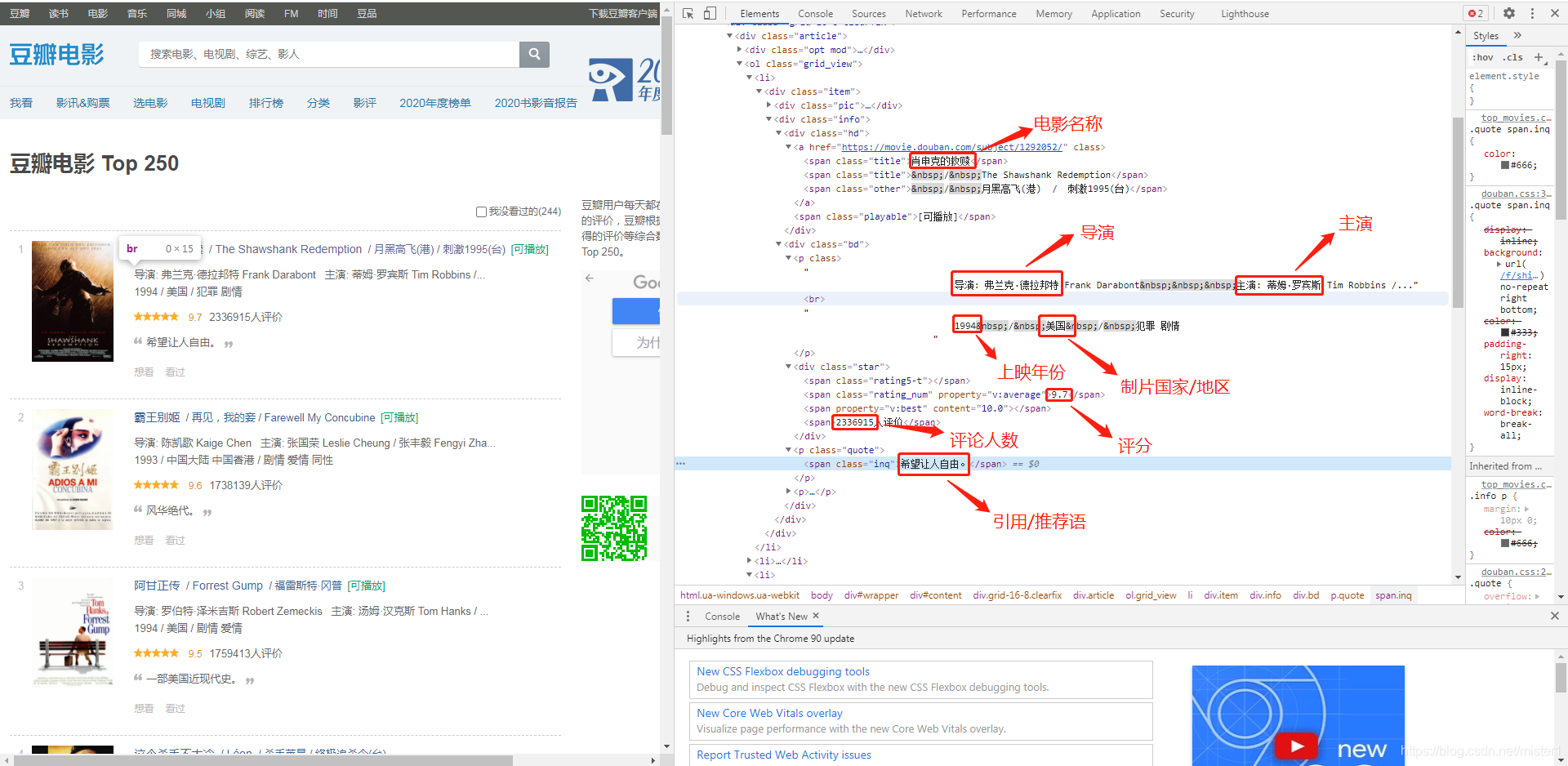
爬取内容包括电影名称、导演、主演、上映年份、制片国家/地区、评分、评论人数、引用/推荐语 这里用到主要用到BeautifulSoup和pandas import requests from bs4 import BeautifulSoup import pandas as pd设置headers,用get请求方式,显示200则表示成功 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.0; WOW64; rv:24.0) Gecko/20100101 Firefox/23.0' } r = requests.get("https://movie.douban.com/top250", headers=headers)用beautifulsoup将网页解析成lxml bs=BeautifulSoup(r.text,'lxml')然后用find_all进行抓取相关数据 movie=[i.find('span').text for i in bs.find_all('div','hd')] #名称 short_comment=[i.find('span' |

【本文地址】
今日新闻 |
推荐新闻 |