【基础理论】专题1 泛化到底是什么? |
您所在的位置:网站首页 › 认知灵活性训练方法是什么意思 › 【基础理论】专题1 泛化到底是什么? |
【基础理论】专题1 泛化到底是什么?
|
文章目录
1 欠拟合、过拟合2 期望误差、经验误差、结构误差3 什么是“泛化性(Generalization)”4 奥卡姆剃刀原理5 一些定义5.1 假设空间5.2 学习算法5.3 一致性(Consistency)5.4 经验风险最小化(Empirical Risk Minimization(ERM))
6 VC-维(VC-Dimension)7 Vpnik的贡献是什么?8 Poggio的贡献是什么?9 Rademacher的贡献是什么?10 读者可以思考其他一些问题10.1 什么样的函数具有泛化性能?10.2 什么是稳定性?10.3
C
V
L
O
O
、
E
L
O
O
、
E
E
L
O
O
、
C
V
E
E
E
L
O
O
CV_{LOO}、E_{LOO}、EE_{LOO}、CVEEE_{LOO}
CVLOO、ELOO、EELOO、CVEEELOO的稳定性?如何证明?其一致性呢?
1 欠拟合、过拟合
欠拟合:学习器的学习能力不够,不能很好的捕捉到数据特征。过拟合:只关注经验误差,过度“迎合”训练样本。
2 期望误差、经验误差、结构误差
误差:学习器的实际预测输出与样本的真实输出之间的差异。 经验误差(Empirical Error):学习器在训练集上的误差。经验误差是局部的,是可求的。 期望误差(Expected Error):对训练集中的所有样本点损失函数的平均最小化。期望误差是全局的,是理想化的,不可求的。 结构误差:只考虑经验风险的话,会出现过拟合的现象。这时候就引出了结构误差,是对经验误差和期望误差的折中,在经验误差后面加一个正则化项(惩罚项)。 3 什么是“泛化性(Generalization)”泛化性:在已知训练集上好的性能,在未知测试集上也有好的性能。【泛化性就是一般化】(在训练集上表现出某种稳定性,我们认为它可能是泛化的。)不泛化 = 过拟合 通俗解释:你在训练集上得到好的性能,是否意味着在整体上得到好的性能,这就是泛化。 这个原理就是“如非必要,勿增实体”(Entities should not be multiplied unnecessarily)。 奥卡姆剃刀原理是指,在科学研究任务中,应该优先使用较为简单的公式或者原理,而不是复杂的。应用到机器学习任务中,可以通过减小模型的复杂度来降低过拟合的风险,即模型在能够较好拟合训练集(经验风险)的前提下,尽量减小模型的复杂度(结构风险)。 https://blog.csdn.net/oppo62258801/article/details/89174877 在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。 《统计学习方法》李航 问:奥卡姆剃刀原理是否是正确的? 可能正确,他不保证100%正确。但可以保证在现有已知事实下,不做无谓的思考。奥卡姆剃刀原理理解为“问题的复杂度应该和方法的复杂度相匹配”会更贴切一些,简单问题不应去增加模型的复杂度来解决。通俗点讲,对于一个简单问题,应该用简单的方法去解决,而不应该去增加模型的复杂度。 5 一些定义 5.1 假设空间一系列函数。Hypothesis f s ∈ H : X → Y f_s \in H : X \rightarrow Y fs∈H:X→Y 5.2 学习算法
选出的算法是否是分类其中最优的。“一致”指的是与“最优的”一致。 在函数族中,找到最好的假设函数 H H H使在训练集上经验误差最小。 公式详解等后期补更。。。。。 经验风险最小化是寻找一个假设函数 h h h,使得该函数在训练集上的经验误差最小。对于损失函数 L ( h ( x ) , y ) L(h(x), y) L(h(x),y),经验风险最小化问题可以表示为: h E R M = arg min h ∈ H 1 n ∑ i = 1 n L ( h ( x i ) , y i ) h_{ERM} = \arg\min_{h \in H} \frac{1}{n} \sum_{i=1}^{n} L(h(x_i), y_i) hERM=argh∈Hminn1i=1∑nL(h(xi),yi) 这里, n n n 是训练样本的数量, x i x_i xi 和 y i y_i yi 分别是第 i i i 个训练样本的输入和输出。 6 VC-维(VC-Dimension)VC-维是衡量分类器复杂度的一种指标,定义了一个分类器能够“打散”的样本集合的最大容量。对于一个假设空间 H H H,如果存在一个包含 d + 1 d+1 d+1 个点的集合,该集合可以被 H H H 中的假设以任意方式分类,那么 H H H 的VC-维至少为 d d d。 7 Vpnik的贡献是什么?Vapnik的主要贡献是提出了支持向量机(SVM)算法,这是一种基于找到最优超平面来最大化样本间的边界的分类算法。他还提出了结构风险最小化(Structural Risk Minimization, SRM)的概念,它是经验风险最小化的一种泛化。 8 Poggio的贡献是什么?Poggio的工作主要集中在统计学习理论和神经网络理论上,特别是在理解学习算法的泛化能力方面做出了重要贡献。 9 Rademacher的贡献是什么?Rademacher复杂度提供了一种衡量模型在训练集上的表现与在未知数据集上可能表现之间差异的方法。 10 读者可以思考其他一些问题 10.1 什么样的函数具有泛化性能? 10.2 什么是稳定性? 10.3 C V L O O 、 E L O O 、 E E L O O 、 C V E E E L O O CV_{LOO}、E_{LOO}、EE_{LOO}、CVEEE_{LOO} CVLOO、ELOO、EELOO、CVEEELOO的稳定性?如何证明?其一致性呢?参考文献: [1] Poggio T , Rifkin R , Mukherjee S , et al. General conditions for predictivity in learning theory[J]. Nature, 2004, 428(6981):419-22. [2]Cucker, Felipe, Smale, et al. ON THE MATHEMATICAL FOUNDATIONS OF LEARNING.[J]. Bulletin (New Series) of the American Mathematical Society, 2002. |
 对于上图,蓝色函数与数据集吻合(因为经验误差为0)。但很明显,在未知的数据中,性能将表现不佳。因此,该模型的泛化性较差。
对于上图,蓝色函数与数据集吻合(因为经验误差为0)。但很明显,在未知的数据中,性能将表现不佳。因此,该模型的泛化性较差。
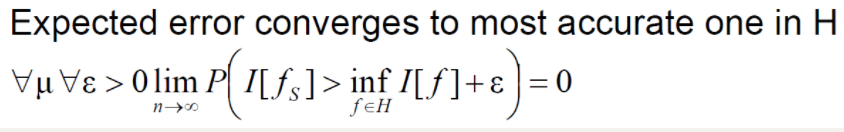
【本文地址】
今日新闻 |
推荐新闻 |