python实现模拟登录云课堂智慧职教并获取课程信息(2) |
您所在的位置:网站首页 › 职教云数据异常 › python实现模拟登录云课堂智慧职教并获取课程信息(2) |
python实现模拟登录云课堂智慧职教并获取课程信息(2)
|
python实现模拟登录云课堂智慧职教并获取课程信息
1.说明2.验证码图片内容识别解决方案1.图片识别接口库的使用效果1.百度ocr识别2.腾讯ocr识别3.图鉴
2.图片识别接口代码
3.今天遇到的大坑1.多窗口切换问题2.时间等待问题
1.说明
上篇文章 python实现模拟登录云课堂智慧职教并获取课程信息(1) 本次通过基于上次的缺陷实现了模拟自动化登录的功能.上次由于验证码问题没有得到解决,本次主要将验证码问题的解决 2.验证码图片内容识别解决方案1 使用pytesseract本地库,但是识别率真的很低, 2 今天尝试了用OpenCV但是对于图片的处理要想极度准确需要做好对于图片的处理过程,常见的步骤是图片–>灰度化–>二值化–>降噪处理–>然后在对图片进行区域识别—>切割区域保存–>最后识别内容,如何加上人工智能进行训练的话,感兴趣的可以看这个传送门 这个工作估计一时半伙完成不了,于是我就找了网上的识别库,分别使用的百度的,腾讯的和图鉴的接口来识别,下面介绍使用效果 1.图片识别接口库的使用效果 1.百度ocr识别1免费使用每天多少次,但是识别率较差,由于图片验证码进行了防识别的处理,导致在是识别的过程中准确率很低,可以参考文档传送门 2.腾讯ocr识别需要钱好像,相对于百度识别的内容而言效果更好一点,同样的问题是他们的ocr识别主要是针对企业的各类信息的识别,所以用于验证码的识别准确率就下降了很多. 3.图鉴这个是在百度的时候发现的,然后用了一下不错的,主要的是他相对于前两者可操作空间较大,可以对识别类型进行人为的控制,就会使得识别率大大提高官方地址 专门弄了一个识别的类对象,可以直接调用就可以. import base64 import json import requests class OcrCodeInfo: def __init__(self,img): self.img=img def base64_api(self): with open(self.img, 'rb') as f: base64_data = base64.b64encode(f.read()) b64 = base64_data.decode() # typeid = '1001' 识别类型 1003:数英混合2 1002:纯英文2 1001:纯数字2 data = {"账号": '密码', "password": 'Aa568718926',"typeid": '1001', "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/base64", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] return "" 3.今天遇到的大坑由于我是python新手,我主业是安卓开发,感觉python可以用于副业赚取,于是就像动手做一做,今天遇到一个大坑,搞了一天才发现原因 1.多窗口切换问题在网页的跳转过程中会有两种情况,一种是直接在当前页面中打开新的地址,一种是打开一个新的窗口放入改地址显示,Selenium库中的窗口切换只针对于第二种情况,同样如果是第一种情况那么跳转前和跳转后获取的窗口句柄都是一样的. 2.时间等待问题由于本人所在地方网络较差,加载速度较慢,会出现跳转第二个页面的时候需要加载几秒钟,那么这个时候获取新页面的元素总是提升没有获取到,导致自己想法与上面1的想法产生了矛盾,以为是切换的问题, 其实就是网络延迟导致的没有发现该标签,代码处理如下图所示.我是通过当前页面的URL来判断是否是新的页面 |
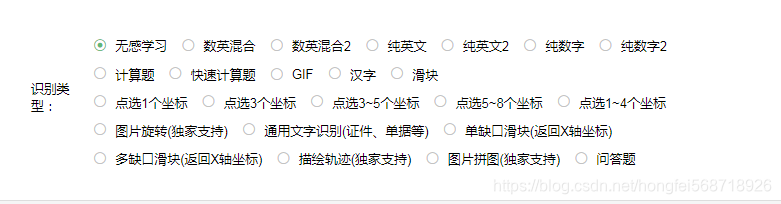 最后选择了第三个,1元钱买了500次的使用机会,使用文档传送门
最后选择了第三个,1元钱买了500次的使用机会,使用文档传送门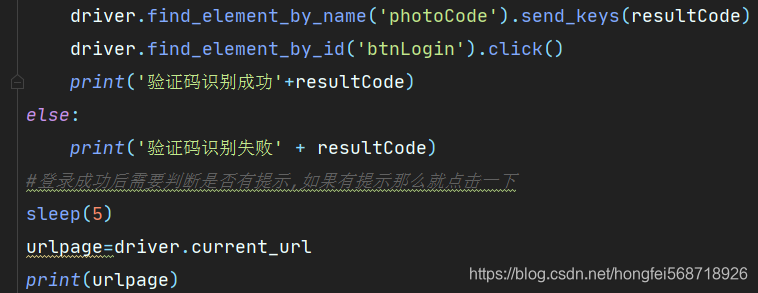 最后推荐一篇关于讲述如何处理selenium中等待的几种情况传送门 好了现在就可以实现登录,继续向下走获取课程信息. 明天周一上班,下一次更新估计需要一段时间 最后打个信息 公众号 搜搜网课答案库 关注一下,csdn别给我不通过啊
最后推荐一篇关于讲述如何处理selenium中等待的几种情况传送门 好了现在就可以实现登录,继续向下走获取课程信息. 明天周一上班,下一次更新估计需要一段时间 最后打个信息 公众号 搜搜网课答案库 关注一下,csdn别给我不通过啊【本文地址】
今日新闻 |
推荐新闻 |