清华博士创业之路:从程序员工作量化到开源价值分配 |
您所在的位置:网站首页 › 程序员工作如何量化工资的计算 › 清华博士创业之路:从程序员工作量化到开源价值分配 |
清华博士创业之路:从程序员工作量化到开源价值分配
|
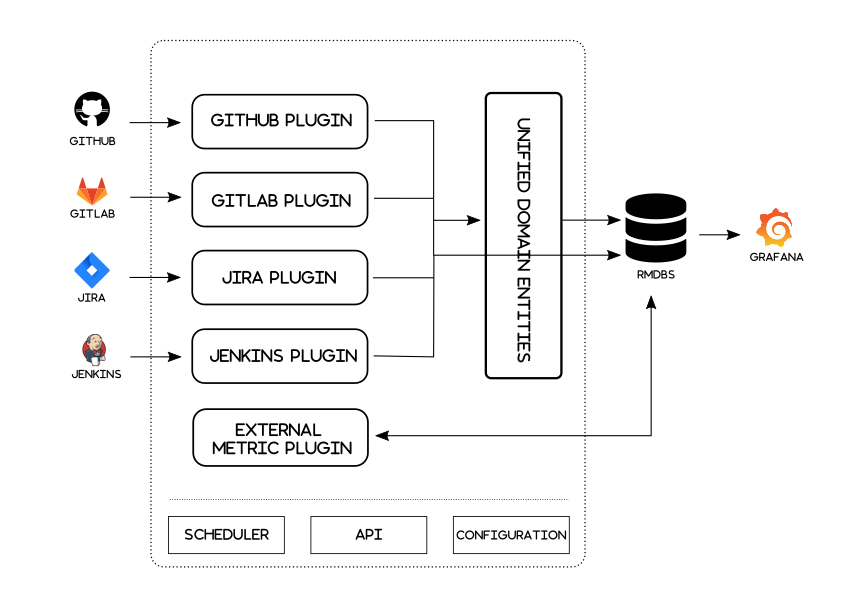
由于不涉及利益分配,开源社区用代码行数来统计开发者贡献比重的方式无伤大雅。但在商业公司中,这种按照代码行数来计算员工绩效的方法就显得非常不合理。 2016 年,Facebook 内部仍在采用统计代码行数的方式计算员工项目奖金,这种简单粗暴的衡量方式遭到了业界的质疑。图灵奖获得者 Edsger Dijkstra 早在上个世纪 80 年代就指出,用 “每月生产的代码行数” 来衡量 “程序员的生产力” ,忽略了程序员的创造性带来的更大价值,反而会鼓励人们编写没有意义的多余代码。 为了探寻能够合理衡量开发者贡献比例的方法,任晶磊和来自 UC Berkely、清华大学、FreeBSD 项目组的团队成员开启了相关领域的探索。他们利用程序分析和机器学习技术,对代码的结构化价值和非结构化价值进行分析,以期找到能够更加全面、合理量化开发者工作的指标。 2018 年,团队在软件工程领域顶级国际学术会议 FSE 2018 上发表论文《关于量化代码贡献的开发价值》,引发了业内的广泛关注。基于该论文的学术成果,任晶磊与研究团队成员共同创建了思码逸(Merico)公司,以解决开源社区与软件行业的价值分配问题为终极愿景开启了创业之路。 合理评估开发者的工作量以思码逸研发团队推出的一种新的量化指标“代码当量(ELOC)”为例,它可以用来替代 LOC。 ELOC 不是统计源代码层面的信息,而是评估源代码编译成的抽象语法树的复杂度。这样自然避免了源代码中注释、空行、换行等噪音。同时,对代码抽象语法树中的编辑类型、节点类型、函数内重复代码进行了加权计算,能够更加合理地反映代码工作量。 编辑类型加权:将抽象语法树从一个形态修改成另一个形态涉及四种编辑操作(Edit Type Factor):新增节点 Inserts,删除节点 Deletes,更新节点 Updates,移动节点 Moves。可以近似地类比为:新增代码,删除代码,更新代码中某语法结构的值,移动一段代码。通常可以认为这四种编辑类型的单位工作量是不一样的,例如删除一个节点比新增一个节点更“轻松”。 节点类型加权:抽象语法树的节点类型对应代码语法结构的类型,例如 If 节点表示一个 If 语句,Call 节点表示一次函数调用,String 节点表示一个字符串字面量。而生产不同类型的节点所需的工作量也是不同的,例如在代码中添加一个字符串比添加一个 If 条件语句更“轻松”。基于这个假设,ELOC 为不同的节点类型设置了不同权重。 节点重复加权:开发者在编写代码时,通常会有一些复制或者近似复制(复制后稍作修改)的行为。复制一段代码和原创一段代码的工作量是不同的,复制或复制后稍作修改会更“轻松”。因此在计算代码当量时,ELOC 加入了对相似代码段的检测,并降低其权重。 代码当量仅仅是任晶磊和其团队合理量化开发者工作而做出的诸多努力之一,其他的度量技术或指标还包括代码依赖关系、复用度、模块性、缺陷密度等等。任晶磊也作为起草专家参与了由中关村智联软件服务业质量创新联盟、中国软件协会过程改进分会发起的《软件研发效能度量规范》标准,其中定义了五大认知域几十种度量指标。 然而技术并非愿景实现道路上的唯一障碍。由于软件研发本身是十分复杂的系统工程,长期以来许多管理与协作都是在黑盒中进行,信息不对称的情况下只能依赖主观判断,市场上也没有使用量化数据的习惯。 一方面,当前市面上一些主要面向企业或者管理者的工具,通过统计代码行数的方式来度量开发者工作量,这对于开发者来说是显然是不合理的;另一方面,开发者自身的工作难以量化,往往只能依靠“PPT”、“演讲”等汇报形式向外界介绍自己的工作,这造成了软件行业中很多职场不公平问题的出现。 思码逸产品经理张开云告诉我们,公司目前的商业产品正是以此切入,通过代码当量等技术度量与分析数据,在评估开发者工作时不再单纯统计代码行数,而是聚合开发过程中的代码交付效率、交付质量、故障恢复时间、交付成本、社区贡献度等可视化数据,帮助企业研发团队客观评估、定位并快速解决研发过程的问题,主要面向企业或开发团队的管理者。 而在开发者侧,他们的产品也能帮助开发者更加客观地复盘自己的开发过程,补足技能树上的短板,同时也能够充分体现个人工作的价值,从一定程度上消除行业“内卷”。 通过这些商业化的尝试,一方面帮助研发团队在实际场景中不断打磨提升技术,另一方面也使量化开发数据逐渐被市场采纳,成为研发日常中的基础设施。这都为思码逸团队追求终极愿景打下了基础。 为了将已有的技术回馈社区,同时吸引更多的开发者参与共建,思码逸于 2021 年末开始将其产品的核心能力陆续开源出来。 DevLake 是其首批开源的项目,定位是开源的 DevOps 研发效能数据平台,在团队计划开源的三大产品模块中扮演着数据整合者的角色,帮助开发者团队在整个软件开发生命周期(SDLC)中整合和分析软件开发数据。 针对当前 DevOps 工具链复杂、数据散乱难以收集的问题,DevLake 可以汇聚需求、设计、开发、测试、交付和运营六大软件研发环节的研发效能数据,连通软件研发全生命周期;同时支持数据源的多样性,目前可接入主流工具 JIRA、GitHub、GitLab 及 Jenkins 的研发数据,并采用灵活的架构和插件设计,方便用户进行二次开发,接入自己的数据源进行分析。
张开云透露,尽管 DevLake 主打从复杂、异构的研发流程中收集并汇聚数据的能力,仅有基础的分析功能,但已经可以解决很多中小型研发团队基本的效能分析需求。知名开源数据库 TiDB 研发团队就在使用 DevLake 进行质量侧的效能分析,其背后的商业公司 PingCAP 内部也订阅了他们的付费产品进行更深入的研发效能分析工作。 DevLake 的开源只是思码逸回归开源的第一步,后续他们还将把包括量化开发者工作的数据分析技术在内的核心能力陆续开源出来,一步一步向公司创立之初的终极愿景迈进。 终极愿景在创业之初,任晶磊曾在哈佛大学的演讲上描述了自己的终极愿景 —— 他希望能够把完善的开发者工作量化技术与股份制公司系统结合起来,创造一个开放的虚拟公司。 任晶磊在开源项目中引入了一个智力股权(intellectual shareholding)的概念。开发者向一个项目贡献代码,得到相应的股权,其数量由他们正在研究的量化算法动态计算;而项目的收益,如捐赠或赞助等,会按照股份比例(即贡献)分配到开发者手中。通过智力股份制,开发者可持续获得预期收入,即便他们选择退出一个项目或者这个项目只在一年后才产生利润。这种新的模型可以为开源开发者带来更加公平和长期的回报。 通过结合代码贡献量化和未来的智力股权模式,开发者将避免传统公司低效的层级组织、死板的工资体系和严格的知识产权分隔。特别地,非软件开发贡献也同样可以融入这个新模型。一个项目可以预留一定比例的股权或收益给非软件开发贡献者,例如外包的财务或市场团队。总之,一个开放的虚拟公司,既可以像传统商业公司一样获得利润,又可以保持开源项目一样的软件开发流程。程序员们将获得更多的自由选择他们真正喜爱和擅长的工作。 “也许在未来的某一天,所有的软件都将以开源或开放的形式构建,每一个程序员都能以自己的脑力付出获得持续、合理的报酬,只要你参与构建的软件能够持续创造利润,你可以在任何喜欢的地方写代码。”任晶磊说。 嘉宾介绍
任晶磊 清华大学计算机系博士,前微软亚洲研究院研究员,斯坦福大学、卡内基梅隆大学访问学者;《软件研发效能度量规范》标准专家组核心专家。在软件系统、软件工程领域从事前沿研究多年,具备丰富经验。曾在 FSE、OSDI 等顶级国际学术会议上发表论文多篇,亦参与过微软下一代服务器系统架构设计与实现。同时,也是一位积极的开源贡献者。 现任思码逸 CEO,通过打造先进的深度代码分析技术和研发大数据平台,以数据驱动软件工程,助力企业和团队提升研发效能。 DevLake 项目地址:https://gitee.com/merico-dev/lake |

【本文地址】
今日新闻 |
推荐新闻 |