Python 离群点检测算法 |
您所在的位置:网站首页 › 离群值的计算 › Python 离群点检测算法 |
Python 离群点检测算法
|
局部离群因子(LOF)是一种有效的无监督学习方法,它使用最近邻搜索来识别异常点,是一种基于密度的技术。在本章中,我将解释其动机和算法,并带领大家在 PyOD 中进行实践。基于密度的算法都对异常值很敏感,很容易出现过拟合,解决方法是训练多个模型,然后汇总得分。通过聚合多个模型,过拟合的几率会降低,预测精度也会提高。PyOD 模块提供了几种汇总结果的方法:平均法(Average)、最大值的最大值法(MOM)、最大值的平均值法(AOM)和平均值的最大值法(MOA)。在文中,我将只演示平均法。 离群点可以是全局性的,也可以是局部性的 离群点很容易感知,但用数学定义却不容易。相距甚远的数据点就是离群点。一次我在海滩岩石上看日落,一群海鸥站在我旁边的岩石上,有一只灰色的海鸥独自站在另一块岩石上。从我坐的地方看,那只灰色的海鸥是个异类。虽然海滩很长,海滩上还有很多其他的单身海鸥。从海滩的近处向远处看,那只灰色海鸥并不像离群的。 上述故事表明,离群点可能是全局离群点,也可能是局部离群点。数据点远离其附近的数据体时,会被视为离群值。图 (A) 展示了局部异常值和全局异常值。全局的算法可能只能捕捉到全局离群值。如果需要识别局部异常值,就需要一种能够关注局部邻域的算法。局部邻域中数据点的密度是关键,而 LOF 将不同密度的局部邻域纳入了识别局部离群值的考虑范围。
局部离群因子(LOF)旨在调整不同局部密度的变化。它分为五个步骤,其中第四步涉及局部密度,第五步比较点的邻域密度与附近数据集群的密度。 Step 1: K-neighbors Step 2: K-distance Step 3: Reachability-distance (RD) Step 4: Local reachability density (LRD) Step 5: Local Outlier Factor of K-neighbor: LOF(k) Reachability-distance 首先,K-近邻是指 K-近邻之前的圆周区域。在图 (B) 中,O点的第一、第二和第三近邻分别是p1、p2 和p3。虚线圆是 K=3 时 K 最近邻的面积。这一定义与 KNN 相同。 其次,K-distance(o) 是点O到 K 最近邻居的距离。该距离可以用欧氏距离或曼哈顿距离测量。 第三,点 O 的可达性距离是 K-distance*(o*)或任意点P 与O 之间距离的最大值。P2到O的距离为d(P2,O),小于点P3到O 的距离,即 K-distance(o)。因此P2的 RD 为 K-distance(o),即P3到O 的距离。 步骤 1 和 2 只是帮助定义步骤 3 中的可达性距离。可及距离公式是为了减少所有靠近O 点的点P的*d(p,o)*的统计波动。 在步骤 4 中,LRD 是O点与其邻居的平均可达距离的倒数。LRD 值低意味着最近的数据体远离O 点。
最后,在步骤 5 中,LOF 是点O的 K 个邻居的平均 LRD 与其 LRD 之比,如下式所示。第一项是 K 个邻居的平均 LRD。LOF 是p的 LRD 与点p的 K 个近邻的 LRD 之比的平均值。第二项是点O 的 LRD。
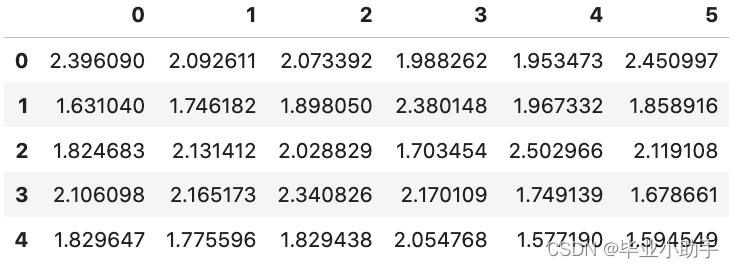
如果O点不是离群点,则邻近点的平均 LRD 与 O 点的 LRD 大致相等,此时 LOF 几乎等于 1。另一方面,如果O点是一个离群点,则第一期的邻居平均 LRD 将高于第二期,此时 LOF 将大于 1。 在 LOF 中使用距离比可以确保考虑到不同的局部密度。无论聚类密度如何,聚类中数据点的 LOF 值通常都接近于 1。例如,在图(A)中,蓝色或绿色聚类中数据点的 LOF 值都接近 1,尽管这两个聚类的密度不同。 一般来说,如果 LOF> 1,则被视为离群点。该数据点与相邻数据点的距离比预期的要远。另一方面,如果一个数据点位于数据密集区域,它就不是离群点。它的 LOF 值将接近 1。 建模流程 可以通过选择一个阈值来区分离群点得分高的异常观测值和正常观测值。如果先验知识表明异常值的百分比不应超过1%,那么您可以选择一个相应的阈值。 对于模型的合理性,两组之间特征的描述统计数据(比如均值和标准差)非常关键。如果预期异常组的某一特征平均值应该高于正常组,而结果恰恰相反,就需要对该特征进行调查、修改或放弃,并重新建模。 第一步:建立 LOF 模型 我将使用 PyOD 的generate_data()函数生成百分之十的离群值。数据生成过程(DGP)将创建六个变量,并且模拟数据集中包含目标变量 Y,但无监督模型只使用 X 变量。目的是为了增加案例的趣味性,异常值的百分比设置为 5%,“contamination=0.05”。 import numpy as np import pandas as pd import matplotlib.pyplot as plt from pyod.utils.data import generate_data contamination = 0.05 # percentage of outliers n_train = 500 # number of training points n_test = 500 # number of testing points n_features = 6 # number of features X_train, X_test, y_train, y_test = generate_data( n_train=n_train, n_test=n_test, n_features= n_features, contamination=contamination, random_state=123) X_train_pd = pd.DataFrame(X_train) X_train_pd.head()
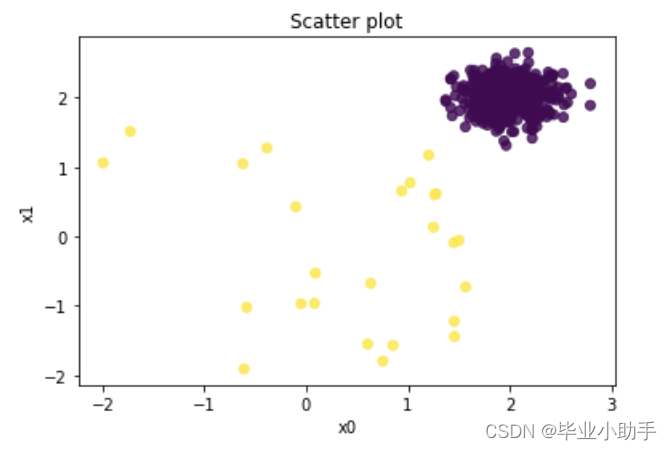
前两个变量绘制成散点图。散点图中的黄色点是百分之十的异常值。紫色点为正常观测值。 # Plot plt.scatter(X_train_pd[0], X_train_pd[1], c=y_train, alpha=0.8) plt.title('Scatter plot') plt.xlabel('x0') plt.ylabel('x1') plt.show()
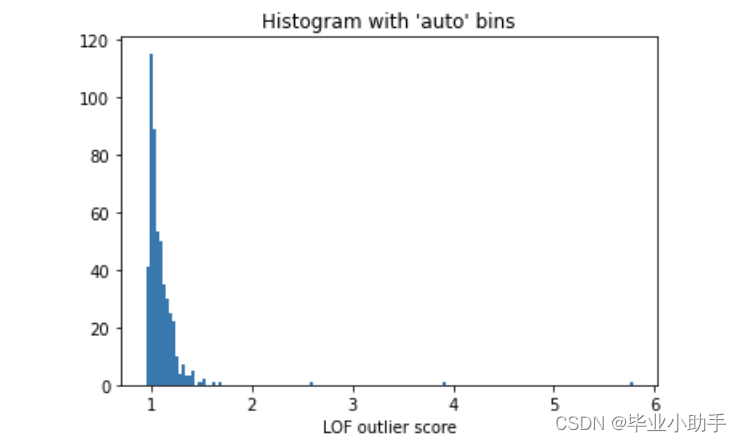
PyOD提供了统一的应用程序接口,使得使用PyOD来建立模型非常容易。接下来,我们声明并拟合模型,然后使用函数decision_functions()来生成训练数据和测试数据的离群值。 在这里,参数contamination=0.05表示污染率为5%。污染率是异常值的百分比。通常情况下,我们可能不知道离群值的百分比,因此可以根据先验知识来指定一个值。PyOD将污染率默认为10%。尽管该参数不影响离群值分数的计算,但PyOD使用它来推导离群值的阈值,并应用函数predict()来分配标签(1 或 0)。我已经创建了一个简短的函数count_stat(),用于显示预测值"1"和"0"的计数。threshold_语法显示了指定污染率的阈值。任何高于阈值的离群值都被视为离群值。 from pyod.models.lof import LOF lof = LOF(contamination=0.05) lof.fit(X_train) # Training data y_train_scores = lof.decision_function(X_train) y_train_pred = lof.predict(X_train) # Test data y_test_scores = lof.decision_function(X_test) y_test_pred = lof.predict(X_test) # outlier labels (0 or 1) def count_stat(vector): # Because it is '0' and '1', we can run a count statistic. unique, counts = np.unique(vector, return_counts=True) return dict(zip(unique, counts)) print("The training data:", count_stat(y_train_pred)) print("The training data:", count_stat(y_test_pred)) # Threshold for the defined comtanimation rate print("The threshold for the defined comtanimation rate:" , lof.threshold_) The training data: {0: 477, 1: 23} The training data: {0: 472, 1: 28} The threshold for the defined comtanimation rate: 1.321258785666126 lof.get_params() {'algorithm': 'auto', 'contamination': 0.05, 'leaf_size': 30, 'metric': 'minkowski', 'metric_params': None, 'n_jobs': 1, 'n_neighbors': 20, 'novelty': True, 'p': 2}第 2 步–为 LOF 模型确定一个合理的阈值 PyOD内置了一个名为threshold_的函数,可根据污染率计算训练数据的阈值。默认情况下,污染率为0.10,因此训练数据的阈值为1.2311。这意味着任何异常值大于1.2311的观测值都会被视为离群值。另一种确定阈值的方法是使用PCA离群点得分的直方图。我们可以根据业务需求来选择阈值。图©展示了得分直方图。我们可以采取更保守的方法,选择一个较高的阈值,这样离群值组中的离群值会更少,但期望更准确。 import matplotlib.pyplot as plt plt.hist(y_train_scores, bins='auto') # arguments are passed to np.histogram plt.title("Histogram with 'auto' bins") plt.xlabel('LOF outlier score') plt.show()
第三步–展示 LOF 模型正常组和异常组的汇总统计量 在第 1 章中提到了两组特征之间的描述性统计数据(如均值和标准差)对于证明模型的合理性非常重要。我创造了一个名为 descriptive_stat_threshold() 的简短函数,用于展示基于阈值的正常组和离群组特征的大小和描述性统计。我将阈值简单地设置为 5%。您可以尝试不同的阈值来确定离群值组的合理大小。 threshold = lof.threshold_ # Or other value from the above histogram def descriptive_stat_threshold(df,pred_score, threshold): # Let's see how many '0's and '1's. df = pd.DataFrame(df) df['Anomaly_Score'] = pred_score df['Group'] = np.where(df['Anomaly_Score'] |
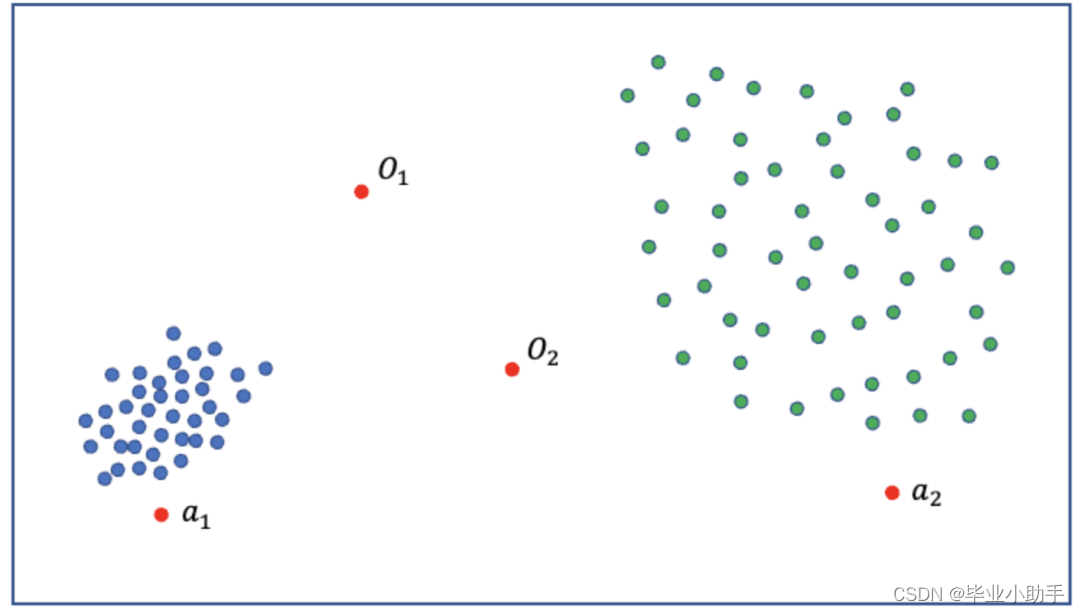 全局和局部离群值 LOF 如何工作? LOF计算的是数据点相对于其相邻数据点的密度偏差,用于识别离群点。下图中a1点的密度远低于蓝色簇的点,显示蓝色聚类比绿色聚类更密集。当数据密度不同,LOF尤其有效。点a2是绿色聚类的局部离群点。LOF可以检测局部离群点。
全局和局部离群值 LOF 如何工作? LOF计算的是数据点相对于其相邻数据点的密度偏差,用于识别离群点。下图中a1点的密度远低于蓝色簇的点,显示蓝色聚类比绿色聚类更密集。当数据密度不同,LOF尤其有效。点a2是绿色聚类的局部离群点。LOF可以检测局部离群点。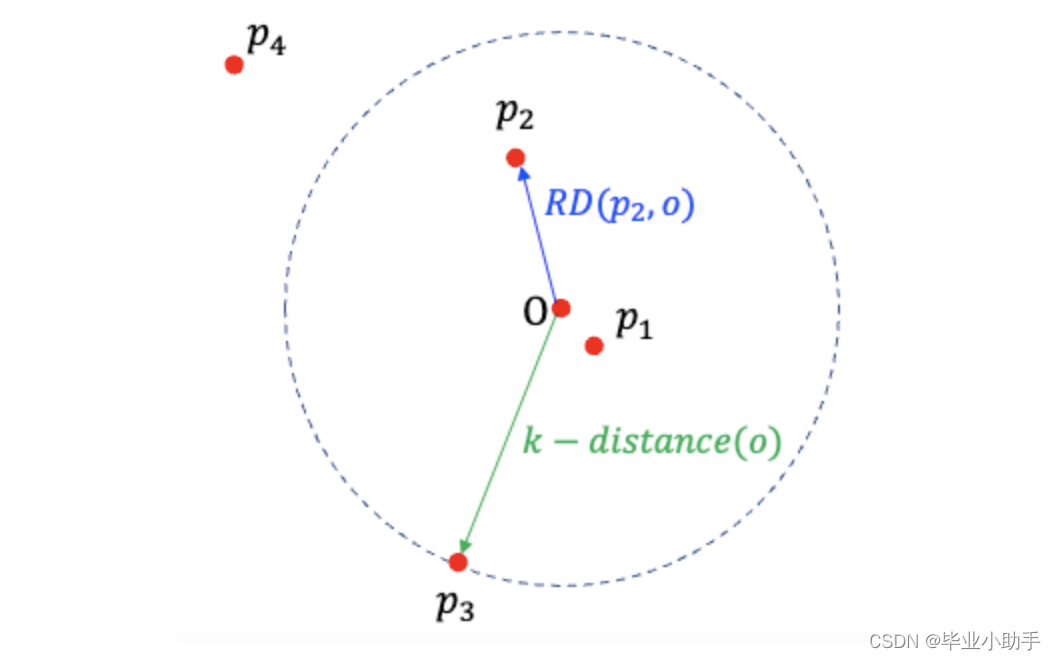
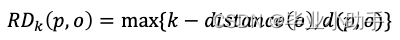
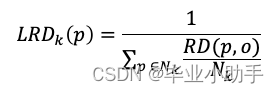
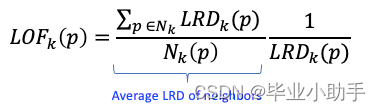
【本文地址】
今日新闻 |
推荐新闻 |