异常检测Anomaly Detection(一)定义、分类及方法 |
您所在的位置:网站首页 › 离群值定义 › 异常检测Anomaly Detection(一)定义、分类及方法 |
异常检测Anomaly Detection(一)定义、分类及方法
|
1. 什么是异常检测?1.1 定义1.2 应用场景1.3 异常检测为什么难做
2. 异常检测的分类2.1 根据数据集性质分类2.2 根据异常的类别分类2.3 根据标签的可获得性分类
3. 异常检测方法综述3.1 基础方法3.1.1 基于统计学的方法3.1.2 谱方法3.1.3 基于距离的方法
3.2 集成方法3.2.1 feature bagging :3.2.2 孤立森林:
3.3 基于分类的机器学习方法3.3.1 神经网络方法3.3.2 贝叶斯网络3.3.3 SVM方法
1. 什么是异常检测?
1.1 定义
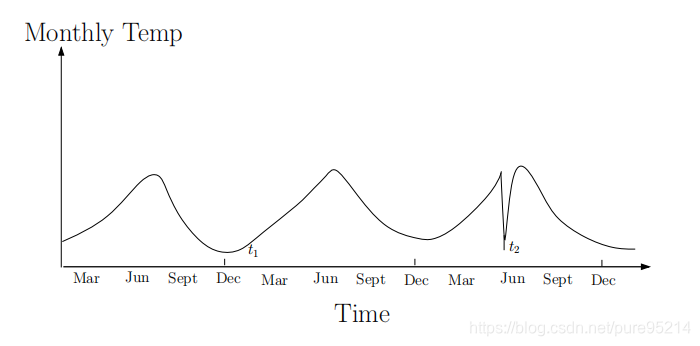
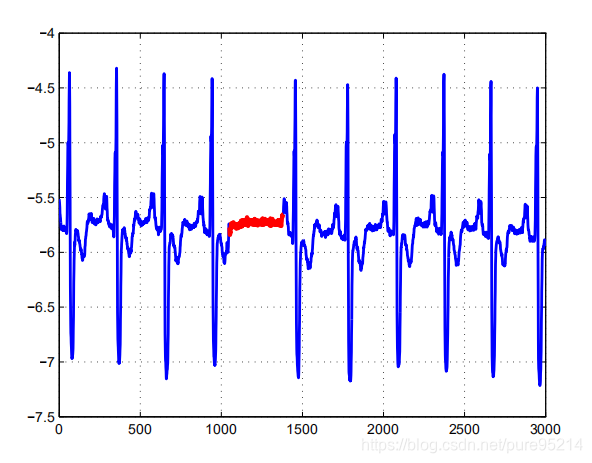
Anomaly detection refers to the problem of finding patterns in data that do not conform to expected behavior. 1 异常检测,即寻找不符合预期行为的数据模式。 1.2 应用场景某些数据的异常表现可能蕴含重要信息。 例如,在金融风控场景中,脱离正常的行为模式可能意味着信用卡盗刷、骗保; 在医疗影像如CT、MRI中,异常图像可能意味着肿瘤等疾病; 计算机网络安全领域中,检测是否有违反安全策略的入侵等。 1.3 异常检测为什么难做正常和异常之间的界限不清晰。在靠近边界处,正常观测常被错分类为异常观测,而异常观测又容易被分类为正常的。 异常行为难以辨识。异常行为通常遭人“粉饰”,使之看起来正常。 异常行为多变导致处置方式需要及时调整。例如双十一网店的销量很大可能是正常的,但平日里突然销量暴增可能是人为刷单,需要及时调整策略。 不同场景下的异常定义不同。例如,医学领域的微小偏差(如体温波动)可能是异常,而在股市领域的类似偏差(如股票价值波动)可能被视为正常; 数据缺乏标签,很多场景下没有异常数据的标签,无法使用监督学习;即使使用人工打标创建标签,通常情况下负样本(异常样本)是极少的,属于样本不平衡问题。 异常和噪音有时候很难分清。 2. 异常检测的分类 2.1 根据数据集性质分类 统计型数据 static data(文本、网络流)序列型数据 sequential data(时间序列数据、基因组序列)空间型数据 spatial data(图像、视频、生态数据) 2.2 根据异常的类别分类点异常 Point Anomaly:一个单独的数据实例相对于其余的数据被认为是异常的。这是最简单的异常类型,也是大多数异常检测研究的重点。拿信用卡举例,如果一笔交易的支出金额与账户下的正常支出相比非常高,那么这将是一个点异常。 上下文异常(条件异常) Contextual Anomaly / Conditional Anomaly:指实例在特定情景中异常、其他环境中正常的情形,在时间序列和空间序列中最常见。比如下图中时间序列数据中,t2和t1处于同样的低点,但t2属于异常数据、t1不属于。 集体异常(群体异常) Collective Anomaly / Group Anomaly:指相关数据实例的集合相对于整个数据集是异常的,集体异常中的个别数据实例本身可能不是异常,但它们作为一个集合一起出现是异常的。比如下面表示房性过早搏动问题的心电图中,红色区域的值单独拿出来不是异常、但组合出现就是异常了。 统计学方法假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。统计技术将一个统计模型(通常用于正常行为)与给定的数据相匹配,然后应用统计推断测试来确定一个看不见的实例是否属于该模型。统计学方法的有效性高度依赖于对给定数据所做的统计模型假定是否成立。包含参数方法和非参数方法。 参数方法有高斯模型、高斯混合模型、回归方法等。一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。即利用统计学方法建立一个模型,然后考虑对象有多大可能符合该模型。 非参数方法有直方图、核函数等。 3.1.2 谱方法典型的如PCA方法,Principle Component Analysis是主成分分析,简称PCA。它的应用场景是对数据集进行降维。降维后的数据能够最大程度地保留原始数据的特征(以数据协方差为衡量标准)。其原理是通过构造一个新的特征空间,把原数据映射到这个新的低维空间里。PCA可以提高数据的计算性能,并且缓解"高维灾难"。 3.1.3 基于距离的方法这类算法适用于数据点的聚集程度高、离群点较少的情况。同时,因为相似度算法通常需要对每一个数据分别进行相应计算,所以这类算法通常计算量大,不太适用于数据量大、维度高的数据。 基于相似度的检测方法大致可以分为三类: 基于集群(簇)的检测,如DBSCAN等聚类算法。 聚类算法是将数据点划分为一个个相对密集的“簇”,而那些不能被归为某个簇的点,则被视作离群点。这类算法对簇个数的选择高度敏感,数量选择不当可能造成较多正常值被划为离群点或成小簇的离群点被归为正常。因此对于每一个数据集需要设置特定的参数,才可以保证聚类的效果,在数据集之间的通用性较差。聚类的主要目的通常是为了寻找成簇的数据,而将异常值和噪声一同作为无价值的数据而忽略或丢弃,在专门的异常点检测中使用较少。 基于距离的度量,如k近邻算法。 k近邻算法的基本思路是对每一个点,计算其与最近k个相邻点的距离,通过距离的大小来判断它是否为离群点。在这里,离群距离大小对k的取值高度敏感。如果k太小(例如1),则少量的邻近离群点可能导致较低的离群点得分;如果k太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使模型更加稳定,距离值的计算通常使用k个最近邻的平均距离。 基于密度的度量,如LOF(局部离群因子)算法。 局部离群因子(LOF)算法与k近邻类似,不同的是它以相对于其邻居的局部密度偏差而不是距离来进行度量。它将相邻点之间的距离进一步转化为“邻域”,从而得到邻域中点的数量(即密度),认为密度远低于其邻居的样本为异常值。 3.2 集成方法集成是提高数据挖掘算法精度的常用方法。集成方法将多个算法或多个基检测器的输出结合起来。其基本思想是一些算法在某些子集上表现很好,一些算法在其他子集上表现很好,然后集成起来使得输出更加鲁棒。集成方法与基于子空间方法有着天然的相似性,子空间与不同的点集相关,而集成方法使用基检测器来探索不同维度的子集,将这些基学习器集合起来。 常用的集成方法有Feature bagging,孤立森林等。 3.2.1 feature bagging :与bagging法类似,只是对象是feature。 3.2.2 孤立森林:孤立森林假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。然后我们继续用随机超平面来切割每个子空间并循环,直到每个子空间只有一个数据点为止。直观上来讲,那些具有高密度的簇需要被切很多次才会将其分离,而那些低密度的点很快就被单独分配到一个子空间了。孤立森林认为这些很快被孤立的点就是异常点。 3.3 基于分类的机器学习方法在有标签的情况下,可以使用树模型(gbdt,xgboost等)进行分类,缺点是异常检测场景下数据标签是不均衡的,但是利用机器学习算法的好处是可以构造不同特征。 3.3.1 神经网络方法可以应用于多类(multi-class)和一类(one-class)环境下的异常检测。一类检测的代表算法有Deep SVDD 、OC-NN、RNN等,多类的代表算法有采用深度学习的聚类方法Deep Clustering、自动编码器AutoEncoder、生成模型Generative Modelsd等。 3.3.2 贝叶斯网络通过对每个测试实例的每个属性后验概率进行聚合,并使用聚合值为测试实例分配一个类标签,基本技术可以推广到多变量分类数据集。 3.3.3 SVM方法应用于单类环境下的异常检测,适用于数据集较小的情况。 VARUN C, ARINDAM B, ARINDAM B. Anomaly Detection : A Survey. ACM Computing Surveys, 2019. ↩︎ |
【本文地址】