机器学习之聚类算法(一:聚类概述和相似度计算) |
您所在的位置:网站首页 › 相似度模型和分类模型的区别与联系 › 机器学习之聚类算法(一:聚类概述和相似度计算) |
机器学习之聚类算法(一:聚类概述和相似度计算)
|
作者:RayChiu_Labloy 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 目录 0.机器学习的四大任务 1.定义 2.聚类分析(Cluster Analysis) 3.聚类分析到底有什么用? 4.聚类分析的典型应用: 目标用户的群体分类 不同产品的价值组合 探测,发现离群点,异常值 5.聚类的五种类别 (1)基于层次的聚类 原理: 算法流程 代表算法:BIRCH、Chameleon、CURE等 BIRCH、Chameleon、CURE三种算法优缺点比较: (2)基于划分的聚类 原理: 基于划分的聚类代表方法有: k-means算法流程: 几种划分类的聚类算法具体描述 各类基于划分的算法优缺点比较: (3)基于密度的聚类 原理: 算法流程 代表的算法DBSCAN、OPTICS、DENCLUE和它们的具体描述 各种算法的优缺点比较: (4)基于网格的聚类 原理: 算法流程: 代表算法:STING、WaveCluster、CLIQUE和它们的具体描述 各个算法的优缺点比较: (5)基于模型的聚类 原理: 代表算法和它们的具体描述: 两类算法的优缺点比较: 6.相似性计算方法 数据标准化 样本的类型分类 连续型特征(如:重量、高度、年龄等) 二值离散型特征(如:性别、考试是否通过等) 多值离散型特征(如:收入分为高、中、低等) 混合类型特征(上述类型的属性至少同时存在两种) 连续型特征的相似度计算 二值离散型相似度计算 根据特征的对称性计算方式分为两种: 简单匹配系数SMC Jaccard系数JC 多值离散型计算 多值离散型计算有两种方式 混合类型属性的相似性计算方法 计算步骤一:对样本的属性值进行预处理 计算步骤二:根据公式计算相似度 0.机器学习的四大任务分类、回归、聚类 、降维,今天我们来说说聚类。 1.定义
聚类(无监督的分类)指的是按照某个特定标准(如距离准则)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。即聚类后同一类的数据尽可能聚集到一起,不同数据尽量分离。 2.聚类分析(Cluster Analysis)“物以类聚” 的过程就是聚类分析,是一个将数据集中的所有数据,按照相似性划分为多个类别(Cluster, 簇)的过程,簇是相似数据的集合。说白了就是根据样本(物或者人或者对象)的特征相似度进行分类的过程。聚类分析是无监督的学习,有几点需要我们关注: 1)聚类分析的对象是物(人),说的理论一点就是样本 2)聚类分析是根据物或者人的特征来进行聚集的,这里的特征说的理论一点就是变量。当然特征选的不一样,聚类的结果也会不一样; 3)聚类分析中评判相似的标准非常关键。说的理论一点也就是相似性的度量非常关键; 4)聚类分析结果的好坏没有统一的评判标准; 3.聚类分析到底有什么用?1) 说的官腔一点就是为了更好的认识事物和事情,比如我们可以把人按照地域划分为南方人和北方人,你会发现这种分法有时候也蛮有道理。一般来说南方人习惯吃米饭,北方习惯吃面食; 2) 说的实用一点,可以有效对用户进行细分,提供有针对性的产品和服务。比如银行会将用户分成金卡用户、银卡用户和普通卡用户。这种分法一方面能很好的节约银行的资源,另外一方面也能很好针对不同的用户实习分级服务,提高彼此的满意度。 再比如移动会开发全球通、神州行和动感地带三个套餐或者品牌,实际就是根据移动用户的行为习惯做了很好的用户细分——聚类分析; 3) 上升到理论层面,聚类分析是用户细分里面最为重要的工具,而用户细分则是整个精准营销里面的基础。精准营销是目前普遍接纳而且被采用的一种营销手段和方式。 一般在数据挖掘中预处理先用它粗分类,然后再用其他机器学习或者深度学习来进行深度的应用。 4.聚类分析的典型应用: 目标用户的群体分类通过对特定运营目的和商业目的所挑选出的指标变量进行聚类分析,把目标群体划分成几个具有明显特征区别的细分群体,从而可以在运营活动中为这些细分群体采取精细化,个性化的运营和服务,最终提升运营的效率和商业效果(如把付费用户按照几个特定维度,如利润贡献,用户年龄,续费次数等聚类分析后得到不同特征的群体) 不同产品的价值组合企业可以按照不同的商业目的,并依照特定的指标标量来为众多的产品种类进行聚类分析,把企业的产品体系进一步细分成具有不同价值,不同目的的多维度的产品组合,并且在此基础分别制定和相应的开发计划,运营计划和服务规划(如哪些产品畅销毛利率又高,哪些产品滞销且毛利又低) 探测,发现离群点,异常值这里的离群点指相对于整体数据对象而言的少数数据对象,这些对象的行为特征与整体的数据行为特征很不一致(***如某B2C电商平台上,比较昂贵,频繁的交易,就有可能隐含欺诈的风险尘封,需要风控部门提前关注,监控)
试图在不同层次上对数据集进行划分,从而形成树形的聚类结构。数据集的划分可采用“自底向上”的聚合策略和“自顶向下”的拆分策略。 算法流程以下流程以自下向上为例。 a.将每个对象看作一类,计算两两之间的最小距离; b. 将距离最小的两个类合并成一个新类; c. 重新计算新类与所有类之间的距离; d. 重复b, c, 直到所有类最后合并成一类。(在此我们了已选择我们需要多少个簇) 代表算法:BIRCH、Chameleon、CURE等BIRCH:BIRCH算法利用树结构对数据集进行处理,叶结点存储一个聚类,用中心和半径表示,顺序处理每一个对象,并把它划分到距离最近的结点,该算法也可以作为其他聚类算法的预处理过程 Chameleon:首先由数据集构造成一个K-最近邻图Gk ,再通过一个图的划分算法将图Gk划分成大量的子图,每个子图代表一个初始子簇,最后用一个凝聚的层次聚类算法反复合并子簇,找到真正的结果簇 CURE:先将每个数据点看成一个簇,然后再以一个特定的“收缩因子”向簇中心“收缩”它们,即合并距离最近的两个簇直到簇的个数为所要求得个数为止 BIRCH、Chameleon、CURE三种算法优缺点比较:BIRCH的优点: 可以在数据量很大时使用、节省内存、速度快、可识别噪声点。BIRCH的缺点: 对高维数据特征的聚类效果不好、若数据集分布簇不是类似于超球体或凸的则聚类效果不好。 Chameleon的优点: 可以处理非常复杂不规则形状的簇。Chameleon的缺点: 高维数据的运算复杂度比较高。 CURE的优点: 可以处理复杂空间的簇、受噪点影响小,对孤立点的处理更加健壮。CURE的缺点: 参数较多、对空间数据密度差异敏感 (2)基于划分的聚类 原理:首先要确定一堆散点最后聚成几类,然后挑选几个点作为初始中心点,再然后依据预先定好的启发式算法(heuristic algorithms)给数据点做迭代重置(iterative relocation),直到最后到达“类内的点都足够近,类间的点都足够远”的目标效果。 基于划分的聚类代表方法有:K-means及其变体包括k-medoids、k-modes、k-medians等、CLARA、PAM等算法。 k-means算法流程:a. 随机地选择k个样本,每个样本初始地代表了一个簇的中心; b.对剩余的每个样本,根据其与各簇中心的距离,将它赋给最近的簇; c.重新计算每个簇的平均值,更新为新的簇中心; d.不断重复b, c, 直到准则函数收敛。 几种划分类的聚类算法具体描述k-means:以集群点的平均值作为参考对象进行聚类 k-medoids:以集群点中最中心(中位数)的对象为参考进行聚类 k-modes: 以集群点特征的众数作为参考进行聚类 PAM:k-medoids的一个变体,使用迭代和贪心算法进行聚类 CLARA :在PAM的基础上对数据进行了抽样 各类基于划分的算法优缺点比较:k-means的优点: 算法简单,时间复杂度低。k-means的缺点: 无法处理非球形等不规则的数据、对初始值k的设置很敏感、对离群点敏感。 k-medoids的优点: 对噪点和离群点不敏感。k-medoids的缺点: 处理时间比k-means长、须事先指定所需聚类簇个数k。 k-modes的优点: 可适用于离散性数据集、时间复杂度更低。k-modes的缺点: 需要事先对k值进行确定。 PAM的优点: 对离群点数据不敏感。PAM的缺点: 时间复杂度高。 CLARA的优点: 可用于大规模数据集的聚类。CLARA的缺点: 在对数据进行随机抽样过程中采样不准确。 (3)基于密度的聚类 原理:定一个距离半径,最少有多少个点,然后把可以到达的点都连起来,判断为同类。 算法流程a.指定合适的r(点的半径)和M(在一个点半径内至少包含的点的个数); b.计算所有的样本点,如果点p的r邻域里有超过M个点,则创建一个以p为核心点的新簇; c.反复寻找这些核心点直接密度可达的点,将其加入到相应的簇,对于核心点发生"密度相连"状况的簇,给予合并; d.当没有新的点可以被添加到任何簇,算法结束。 代表的算法DBSCAN、OPTICS、DENCLUE和它们的具体描述DBSCAN:这类方法采用空间索引技术来搜索对象的邻域,将簇看做是数据空间中被低密度区域分割开的稠密对象区域 OPTICS:是DBSCAN算法的一种改进,对数据对象集合中的对象进行排序,得到一个有序的对象列表,其中包含了足够的信息用来提取聚类 DENCLUE:将每个数据点的影响用一个数学函数形式化地模拟出来,聚类簇通过密度吸引点(全局密度函数的局部最大值)来确定 各种算法的优缺点比较:DBSCAN的优点: 可以处理任何形状的聚类簇、能够检测异常点。DBSCAN的缺点: 需要给定数据点的半径r和最少数量m、对输入参数较敏感。 OPTICS的优点: 对输入参数不敏感。OPTICS的缺点: 计算量大、速度较慢。 DENCLUE的优点: 对有巨大噪声的数据点有良好的聚类效果、比DBSCAN算法快得多、有严格的数学基础。DENCLUE的缺点:需要大量的参数并且参数对结果的影响巨大。 (4)基于网格的聚类 原理:将数据空间划分为网格单元,将数据对象集映射到网格单元中,并计算每个单元的密度。根据预设的阈值判断每个网格单元是否为高密度单元,密度足够大的网格单元形成簇。 算法流程:a.划分网格; b.使用网格单元内数据的统计信息对数据进行压缩表达; c.基于这些统计信息判断高密度网格单元 ; d.最后将相连的高密度网格单元识别为簇。 代表算法:STING、WaveCluster、CLIQUE和它们的具体描述STING:将输入对象的空间区域划分成矩形单元,每个网格单元的统计信息(均值、最大值、最小值)被作为参数预先计算和存储 WaveCluster:把多维数据看做一个多微信号处理,即划分为网格结构后,通过小波变换将数据空间变换成频域空间进行处理 CLIQUE:对高维数据集采用了子空间的概念,划分为网格结构后识别出密集单元,然后运用深度优先算法发现空间中的聚类,再对每个聚类簇确定最小覆盖区域 各个算法的优缺点比较:STING的优点: 效率高、时间复杂度低。STING的缺点: 聚类质量受网格结构最底层的粒度影响、欠缺对网格单元之间的联系的考量。 WaveCluster的优点: 速度快、是一个多分辨率算法,高分辨率可获得细节信息,低分辨率可获得轮廓信息。WaveCluster的缺点: 对已处理簇与簇之间没有明显边缘的情况聚类效果较差。 CLIQUE的优点: 善于处理高维数据和大数据集。CLIQUE的缺点: 聚类的准确度较低。 (5)基于模型的聚类 原理:为每簇假定了一个模型,寻找数据对给定模型的最佳拟合,这一类方法主要是指基于概率模型的方法和基于神经网络模型的方法,尤其以基于概率模型的方法居多。这里的概率模型主要指概率生成模型(generative Model),同一”类“的数据属于同一种概率分布,即假设数据是根据潜在的概率分布生成的。 代表算法和它们的具体描述:代表算法有高斯混合模型(GMM)、SOM(Self Organized Maps) GMM:基于概率模型,将数据分解为若干个基于高斯概率密度函数形成的模型 SOM:基于神经网络模型,一种无监督学习网络,输入层接受输入信号,输出层由神经元按一定方式排列成一个二维节点矩阵 两类算法的优缺点比较:GMM的优点: 结果用概率表示,更具可视化并且可以根据俄这些概率在某个感兴趣的区域重新你和预测。GMM的缺点: 需要使用完整的样本信息进行预测、在高维空间失去有效性。 SOM的优点: 映射至二维平面,实现可视化、可获得较高质量的聚类结果。SOM的缺点: 计算复杂度较高、结果一定程度上依赖于经验的选择。 6.相似性计算方法在聚类分析中,样本之间的相似性通常采用样本之间的距离来表示。两个样本之间的距离越大,表示两个样本越不相似,差异性越大,两个样本之间的距离越小,表示两个样本越相似,差异性越小,当两个样本之间的距离为零时,表示两个样本完全一样,无差异。 相似性是针对样本 xi={xi1,xi2,xi3....,xin}的特征、维度xin来说的,比如人这个对象的一条样本张三来说,他的身高、体重、肤色、性别就是张三这个样本的特征。 数据标准化在进行聚类分析之前,为了消除聚类变量值数量级上的差异,通常需要先对数据进行标准化,常用的标准化方法有: 其中 假设两个样本Xi和Xj分别表示成如下形式: Xi=(xi1, xi2, …, xip ) 和 Xj=(xj1, xj2, …, xjp ) ,它们都是p维的特征向量,并且每维特征都是一个连续型数值。 对于连续型属性,样本之间的相似性通常采用如下几种距离公式进行计算:欧氏距离、曼哈顿距离、闵可夫距离、余弦距离(文章相似度)。这几种距离计算方式比较简单,在这里不做展开叙述了。 二值离散型相似度计算二值离散型特征值只有两个0和1,代表是和否,有或无,没有数值大小的含义。例如人的性别:0代表男1代表女。 这里我们依然用两个样本举例:Xi=(xi1, xi2) 和 Xj=(xj1, xj2) ,它们都是2维的特征向量(可以是多维),并且每维特征都是一个二值离散型数值,那么可以的到图:
高维样本比如xi是这样(0100101) ,xj是(1101001) 根据特征的对称性计算方式分为两种:a.简单匹配系数SMC(Simple Matching Coefficients) b.Jaccard系数JC(Jaccard Coefficients) 简单匹配系数SMC
如果样本的属性都是对称的二值离散型属性,则样本间的距离可用简单匹配系数计算。 对称的二值离散型属性是指属性取值为1或者0同等重要,例如:性别就是一个对称的二值离散型属性,即:用1表示男性,用0表示女性;或者用0表示男性,用1表示女性是等价的,属性的两个取值没有主次之分。 上边的例子计算SMC是 (2+1) / 7 = 3/7 = 0.42 Jaccard系数JC
如果样本的属性都是不对称的二值离散型属性,则样本间的距离可用Jaccard系数计算。 不对称的二值离散型属性是指属性取值为1或者0不是同等重要,例如:是否是癌症的结果,因此通常用1来表示阳性结果,而用0来表示阴性结果。 上边的例子计算JC是 (2+1) / 5 = 3/5 = 0.6 多值离散型计算多值离散型属性是指取值个数大于2的离散型属性,例如:成绩可以分为优、良、中、差。 假设一个多值离散型属性的取值个数为N, 给定数据集X={xi | i=1,2,…,total},其中每个样本xi可用一个d维特征向量描述,并且每维特征都是一个多值离散型属性,即:
对于两个多值离散型的样本 xi = (xi1, xi2, …, xid) 和 xj = (xj1, xj2, …, xjd) 有两种计算方式: 1.简单匹配法
其中: d为数据集中的属性个数,u为样本 xi 和 xj 取值相同的属性个数。 例如:
计算简答匹配值:d(x3, x2) = (3-1)/3 ≈ 0.667 2.Jaccard系数 先将多值离散型属性转换成多个二值离散型属性(one-hot编码),然后再使用Jaccard系数计算样本之间的距离。 例如上边的例子转为多个二值离散型数据如下:
计算jaccard系数方式和二值型一样了。 混合类型属性的相似性计算方法实际生产过程中,数据都是混合类型的,包含连续性、二值离散、多值离散两种或两种以上类型。 计算步骤一:对样本的属性值进行预处理对连续型属性,将其各种取值进行规范化处理,使得属性值规范化到区间[0, 1],对多值离散型属性,根据属性的每种取值将其转换成多个二值离散型属性。预处理之后,样本中只包含连续型属性和二值离散型属性。 计算步骤二:根据公式计算相似度两个样本 xi = (xi1, xi2, …, xid) 和 xj = (xj1, xj2, …, xjd) ,它们之间的距离公式为: 
其中: 情况一:当第k个属性为连续型时,使用如下公式来计算:
情况二:当第k个属性为二值离散型时,如果 情况二:如果xik=xjk=0,且第k个属性是不对称的二值离散型,则 情况三:除了上述情况一和情况二之外的其他情况下,则 参考:聚类总结:各种聚类算法的分类、优缺点、适用场景总结 - 程序员大本营 【如果对您有帮助,交个朋友给个一键三连吧,您的肯定是我博客高质量维护的动力!!!】 |


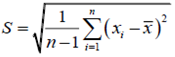 为标准差。
为标准差。 





【本文地址】
今日新闻 |
推荐新闻 |