RTX2060显卡 CUDA环境搭建 |
您所在的位置:网站首页 › 显卡2060可以用几年 › RTX2060显卡 CUDA环境搭建 |
RTX2060显卡 CUDA环境搭建
|
目录
写在前面RTX 2060 显卡支持window环境搭建1. 略述2.下载显卡驱动和CUDA Toolkit工具包(1) 查看显卡信息(2) 下载显卡驱动(3) 下载CUDA Toolkit工具箱
3. VS2019配置(1) 添加环境变量(2) 查看CUDA是否安装成功(3) 查看设置的环境变量情况(4) 验证CUDA是否安装成功(5) 在VS2019下配置CUDA调试环境(6) 配置VS2019下的NsightGPU代码编译器(7) 测试代码test1代码test2代码test3代码
Linux 的 Windows 子系统搭建(没成功 待完善)可能原因:子系统运行错误安装参考网址:WSL安装CUDA Toolkit 问题解释
写在前面
我还以为不会有人看呢, 得认知整理一下, 写的有问题的话可以提出交流。 RTX 2060 显卡支持RTX 2060 是一款NVIDIA推出的显卡,其支持 CUDA 加速技术,下面将详细介绍其支持的情况和使用方法。 CUDA 是一种针对NVIDIA GPU的并行计算平台和编程模型,通过 CUDA 编写程序可以利用GPU的并行处理能力加速计算。对于 RTX 2060 来说,其采用了 Turing 架构,支持 CUDA 10.1 和以上版本,可以充分发挥GPU的计算能力。 window环境搭建参考网站 CUDA学习:Windows下的CUDA环境配置_cuda环境变量-CSDN博客 1. 略述主要干两件事: (1) 安装两个API,CUDA提供两层API接口,CUDA驱动(driver)API 和 CUDA运行时(runtime)API。所以要安装两个API,一个是显卡驱动(drivers),一个是cuda运行时工具包(toolkit)。它们的关系如图所示。 (2)Visual Studio 开发环境配置。 2.下载显卡驱动和CUDA Toolkit工具包 (1) 查看显卡信息要使用nvidia-smi指令,必须先安装NUIDIA的CUDA驱动,一般会自带驱动,只是版本不是最新的。 打开终端,输入nvidia-smi,本机显卡的显卡驱动版本为:551.86(driver) CUDA支持版本为:12.4(toolkit)(这个是我安装好之后的)。 或者使用“DirectX诊断工具”查看显卡信息: 按下“Win+R”组合键打开“运行”,输入“dxdiag”。 点击“确定”后,在“DirectX诊断工具”中可以看到显卡型号、显存容量等详细信息。 地址:Official Drivers | NVIDIA 地址:CUDA Toolkit Archive | NVIDIA Developer
查看环境变量 用户需要手动添加以下的环境变量: CUDA_BIN_PATH=%CUDA_PAT%\bin CUDA_LIB_PATH=%CUDA_PATH%\lib\x64 CUDA_SDK_BIN_PATH=%CUDA_SDK_PATH%\bin\win64 CUDA_SDK_LIB_PATH=%CUDA_SDK_PATH%\common\lib\x64 CUDA_SKD_PATH=C:\ProgramData\NVIDIA Corporation\CUDA Sample\v12.4 添加上述环境变量后,在系统环境变量Path中添加下列路径: %CUDA_BIN_PATH% %CUDA_LIB_PATH% %CUDA_SDK_BIN_PATH% %CUDA_SDK_LIB_path% 在命令行中输入:nvcc --version查看nvcc编译器版本,如下图所示 在命令行中输入:set cuda,查看设置的环境变量情况.如下所示: 进入目录: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite 终端执行deviceQuery.exe 结果如下 ,运行结果为result=PASS则说明CUDA安装成功。 deviceQuery.exe Starting... CUDA Device Query (Runtime API) version (CUDART static linking) Detected 1 CUDA Capable device(s) Device 0: "NVIDIA GeForce RTX 2060" CUDA Driver Version / Runtime Version 12.4 / 12.4 CUDA Capability Major/Minor version number: 7.5 Total amount of global memory: 6144 MBytes (6442123264 bytes) (30) Multiprocessors, ( 64) CUDA Cores/MP: 1920 CUDA Cores GPU Max Clock rate: 1350 MHz (1.35 GHz) Memory Clock rate: 5501 Mhz Memory Bus Width: 192-bit L2 Cache Size: 3145728 bytes Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384) Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers Total amount of constant memory: zu bytes Total amount of shared memory per block: zu bytes Total number of registers available per block: 65536 Warp size: 32 Maximum number of threads per multiprocessor: 1024 Maximum number of threads per block: 1024 Max dimension size of a thread block (x,y,z): (1024, 1024, 64) Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535) Maximum memory pitch: zu bytes Texture alignment: zu bytes Concurrent copy and kernel execution: Yes with 2 copy engine(s) Run time limit on kernels: Yes Integrated GPU sharing Host Memory: No Support host page-locked memory mapping: Yes Alignment requirement for Surfaces: Yes Device has ECC support: Disabled CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model) Device supports Unified Addressing (UVA): Yes Device supports Compute Preemption: Yes Supports Cooperative Kernel Launch: Yes Supports MultiDevice Co-op Kernel Launch: No Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0 Compute Mode: deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.4, CUDA Runtime Version = 12.4, NumDevs = 1, Device0 = NVIDIA GeForce RTX 2060 **Result = PASS**终端执行bandwidthTest.exe 结果如下 ,运行结果为result=PASS则说明CUDA安装成功。 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite>bandwidthTest.exe [CUDA Bandwidth Test] - Starting... Running on... Device 0: NVIDIA GeForce RTX 2060 Quick Mode Host to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 6497.3 Device to Host Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 6425.2 Device to Device Bandwidth, 1 Device(s) PINNED Memory Transfers Transfer Size (Bytes) Bandwidth(MB/s) 33554432 144153.3 Result = PASS NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled. (5) 在VS2019下配置CUDA调试环境打开VS2019,新建空项目,右键项目,选择“生成依赖项”,选择“生成自定义”,在"生成自定义"中勾选"CUDA",如下所示: 在空项目中新建后缀为.cu的源文件.右键该文件,选择"属性"->“常规”->“项类型”.将"项类型设置为:CUDA C/C++.如下所示: 完成上述步骤后进行项目配置.右键项目,选择属性.配置选所有配置(即debug和Realise配置一致). 然后分平台(x64和win32)分别进行配置 x64平台下的配置 包含目录配置项目->“属性”->“配置属性”->“VC++目录”->"包含目录 添加包含目录:$(CUDA_PATH)\include 库目录配置“VC++目录”->“库目录” 添加库目录:$(CUDA_PATH)\lib\x64 依赖项“配置属性”->“链接器”->“输入”->“附加依赖项” 添加库文件(库文件数量较多,默认存储路径为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64,可在该路径下自己添加依赖项): cublas.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;OpenCL.lib Win32平台下的配置 包含目录与x64相同库目录配置添加库目录:$(CUDA_PATH)\lib\Win32 依赖项添加库文件(Win32平台与x64平台的库文件不相同): cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;OpenCL.lib (6) 配置VS2019下的NsightGPU代码编译器在VS2019的"扩展"->“管理扩展"中联机搜索"nsight”,下载"NVIDIA Nsight Intergration"的扩展组件,用于在VS中调试GPU代码.如下所示. 拓展下载完成后,可以使用该扩展对GPU代码进行编程. 在GPU的核函数中添加断点,点击"Start CUDA Debugging(Next-Gen)“便可进入GPU代码的调试,调试过程与VS调试CPU代码相同 使用"CUDA Debugging"只能对GPU部分的代码进行调试,即只能对核函数进行调试,不能对CPU代码进行调试 使用VS2019中的"本地Windows调试器”**只能对CPU部分的代码进行调试,无法调试GPU部分的代码 使用下面给出的测试程序进行测试,查看能否正常运行. (7) 测试代码 test1代码 #include "cuda_runtime.h" #include "device_launch_parameters.h" #include #include using namespace std; constexpr size_t MAXSIZE = 20; __global__ void addKernel(int* const c, const int* const b, const int* const a) { int i = threadIdx.x; c[i] = a[i] + b[i]; } int main() { constexpr size_t length = 6; int host_a[length] = { 1,2,3,4,5,6 }; int host_b[length] = { 10,20,30,40,50,60 }; int host_c[length]; //为三个向量在GPU上分配显存 int* dev_a, *dev_b, *dev_c; cudaMalloc((void**)&dev_c, length * sizeof(int)); cudaMalloc((void**)&dev_a, length * sizeof(int)); cudaMalloc((void**)&dev_b, length * sizeof(int)); //将主机端的数据拷贝到设备端 cudaMemcpy(dev_a, host_a, length * sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(dev_b, host_b, length * sizeof(int), cudaMemcpyHostToDevice); cudaMemcpy(dev_c, host_c, length * sizeof(int), cudaMemcpyHostToDevice); //在GPU上运行核函数,每个线程进行一个元素的计算 addKernel (dev_c, dev_b, dev_a); //将设备端的运算结果拷贝回主机端 cudaMemcpy(host_c, dev_c, length * sizeof(int), cudaMemcpyDeviceToHost); //释放显存 cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c); for (int i = 0; i |

 在查看完电脑的显卡信息后,需要对显卡驱动版本和CUDA版本对应的CUDA Toolkit工具包进行确认.
在查看完电脑的显卡信息后,需要对显卡驱动版本和CUDA版本对应的CUDA Toolkit工具包进行确认.
 search之后直接点击下载
search之后直接点击下载 
 安装完毕后也可以通过nvidia-smi指令查看安装的对不对。
安装完毕后也可以通过nvidia-smi指令查看安装的对不对。 安装完成后,系统环境变量中自动被添加上了如下所示的两个环境变量(版本号对应用户所下载的版本号)。
安装完成后,系统环境变量中自动被添加上了如下所示的两个环境变量(版本号对应用户所下载的版本号)。 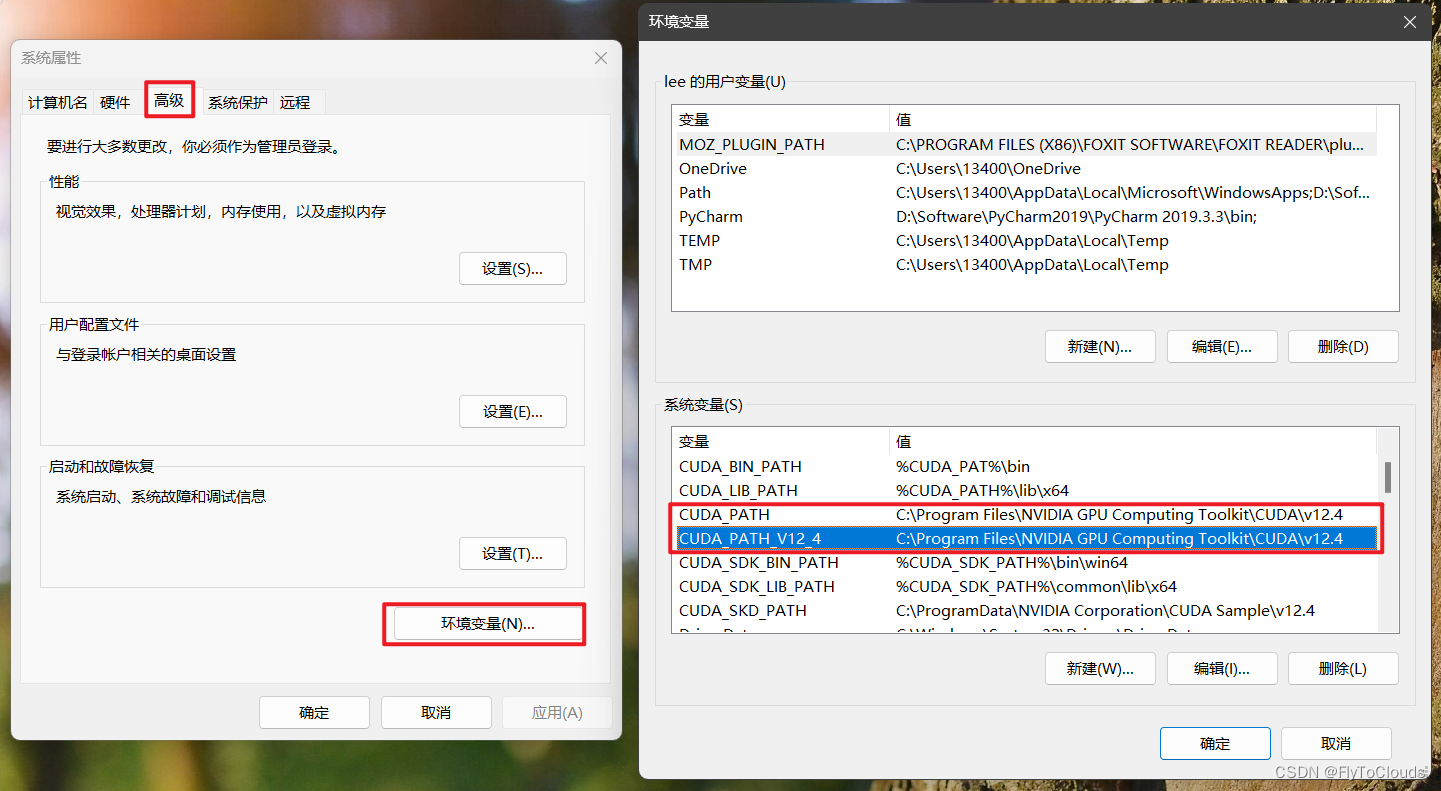 添加环境变量:
添加环境变量:







【本文地址】
今日新闻 |
推荐新闻 |