Xray批量化自动扫描 |
您所在的位置:网站首页 › 批量文件扫描处理方法 › Xray批量化自动扫描 |
Xray批量化自动扫描
|
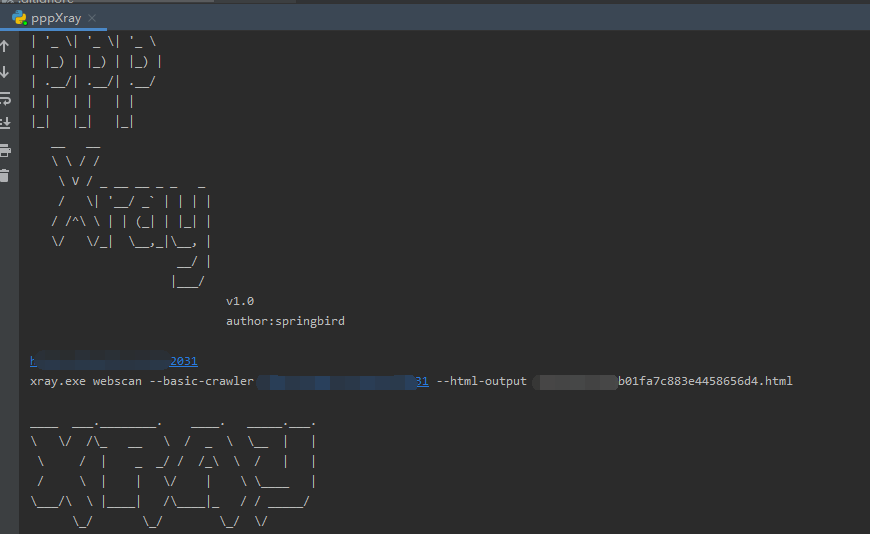
关于Xray高级版破解: https://www.cnblogs.com/Cl0ud/p/13884206.html 不过好像新版本的Xray修复了破解的BUG,亲测Xray1.3.3高级版仍然可以破解 因为Xray没有批量化的选项,在网上查了一下,fofa2Xray是封装好了的EXE文件,其他的好像需要配置代理之类的,反正挺麻烦,我只是想从txt里面按行读取URL进行扫描,所以昨晚上花半个小时自己写了一个小脚本实现Xray自动化批量扫描。 首先是一个大LOGO def logo(): logo=''' _ __ _ __ _ __ | '_ \| '_ \| '_ \ | |_) | |_) | |_) | | .__/| .__/| .__/ | | | | | | |_| |_| |_| __ __ \ \ / / \ V / _ __ __ _ _ _ / \| '__/ _` | | | | / /^\ \ | | (_| | |_| | \/ \/_| \__,_|\__, | __/ | |___/ v1.0 author:springbird ''' return logo将Xray高级版破解之后路径配置在环境变量里,这样我们这个代码就不需要固定位置放置 核心是 def xrayScan(targeturl,outputfilename="test"): scanCommand="xray.exe webscan --basic-crawler {} --html-output {}.html".format(targeturl,outputfilename) print(scanCommand) os.system(scanCommand) returnos.system执行命令进行扫描,这样就实现了单个URL的脚本扫描,接着是读取TXT实现批量 def pppGet(): f = open("target.txt") lines = f.readlines() pattern = re.compile(r'^http://') for line in lines: try: if not pattern.match(line.strip()): targeturl="http://"+line.strip() else: targeturl=line.strip() print(targeturl.strip()) outputfilename=hashlib.md5(targeturl.encode("utf-8")) xrayScan(targeturl.strip(), outputfilename.hexdigest()) # print(type(line)) except Exception as e: print(e) pass f.close() print("Xray Scan End~") return这里的代码就是从文件里面读取URL,依次放在Xray里面进行扫描,放置待扫描URL的txt的名字为target.txt 最终完整代码为: import os import hashlib import re def logo(): logo=''' _ __ _ __ _ __ | '_ \| '_ \| '_ \ | |_) | |_) | |_) | | .__/| .__/| .__/ | | | | | | |_| |_| |_| __ __ \ \ / / \ V / _ __ __ _ _ _ / \| '__/ _` | | | | / /^\ \ | | (_| | |_| | \/ \/_| \__,_|\__, | __/ | |___/ v1.0 author:springbird ''' return logo def xrayScan(targeturl,outputfilename="test"): scanCommand="xray.exe webscan --basic-crawler {} --html-output {}.html".format(targeturl,outputfilename) print(scanCommand) os.system(scanCommand) return # def test(): # pattern = re.compile(r'^http://') # m = pattern.match('http://www.baidu.com') # n = pattern.match('hta') # print(m) # print(n) # return def pppGet(): f = open("target.txt") lines = f.readlines() pattern = re.compile(r'^http://') for line in lines: try: if not pattern.match(line.strip()): targeturl="http://"+line.strip() else: targeturl=line.strip() print(targeturl.strip()) outputfilename=hashlib.md5(targeturl.encode("utf-8")) xrayScan(targeturl.strip(), outputfilename.hexdigest()) # print(type(line)) except Exception as e: print(e) pass f.close() print("Xray Scan End~") return def main(): print(logo()) pppGet() return if __name__ == '__main__': main()运行截图为:
其实这个批量的功能还是挺重要的,或许是Xray开发团队不想扫描器被滥用的原因才没有实现该功能,把代码放在了github上: https://github.com/Cl0udG0d/pppXray
|
【本文地址】