PDF进行批量OCR文字识别并转Word文本的最优解(完全免费) |
您所在的位置:网站首页 › 批量扫描的文件怎么批量保存 › PDF进行批量OCR文字识别并转Word文本的最优解(完全免费) |
PDF进行批量OCR文字识别并转Word文本的最优解(完全免费)
|
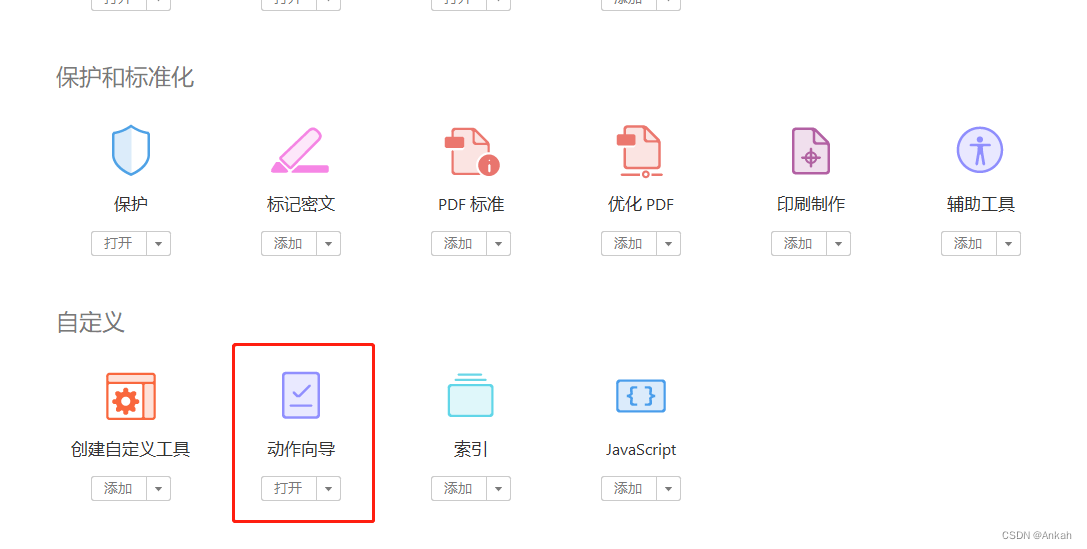
背景:公司要求将大量扫描件电子文档转化为可识别文字的word格式,以方便后续文档管理系统进行档案内容的快速检索。 解决过程:在网上搜寻pdf批量文字识别方案,放眼望去都是各种app的广告,而且大多都要收费。经过几天的研究,终于总结出这么一套免费但准确率高的完整解决方案,总体思路也很简单,就是利用 Adobe Acrobat Pro DC的orc文字识别工具配合其自动化步骤进行批量作业。假如你还在苦恼于几乎找不到真正免费的批量pdf文字识别软件,那么这篇文章绝对可以帮到你,话不多说,直接上教程! 第一步:安装 Acrobat Pro DC Adobe Acrobat Pro DC 是一款强大的PDF编辑工具,具有非常全面的PDF编辑功能,重点是完全免费!这个软件网上一搜一大把,如果有需要的话可以在下方评论留言获得。 第二步:打开动作向导 在上方 “工具” — “自定义” 中找到 “动作向导” ,进入编辑:
点击上方 “新建动作”:
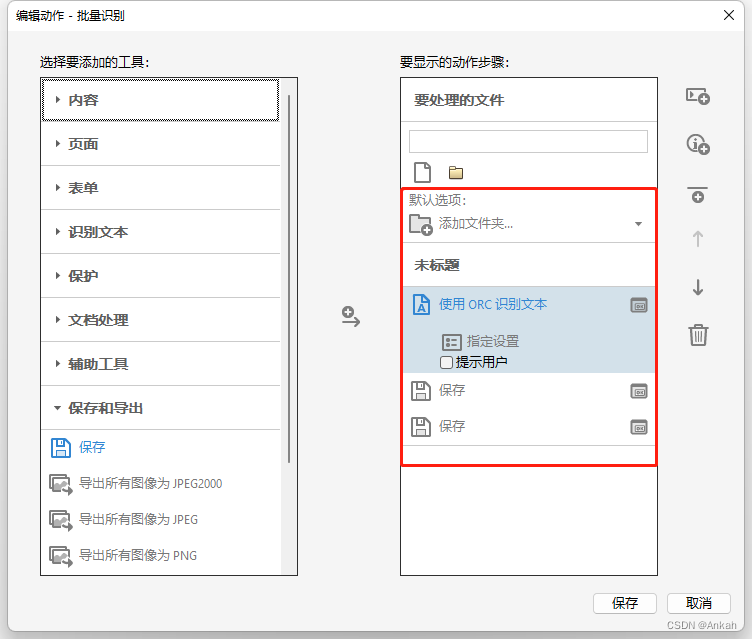
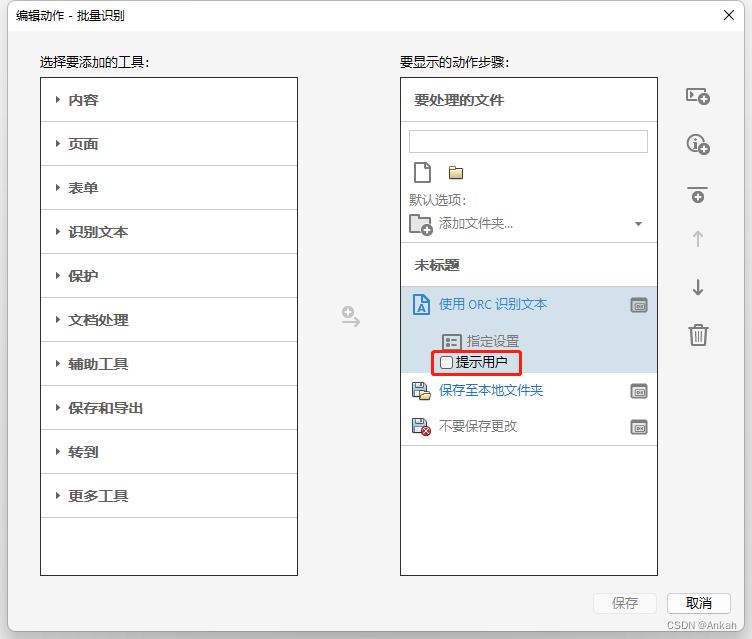
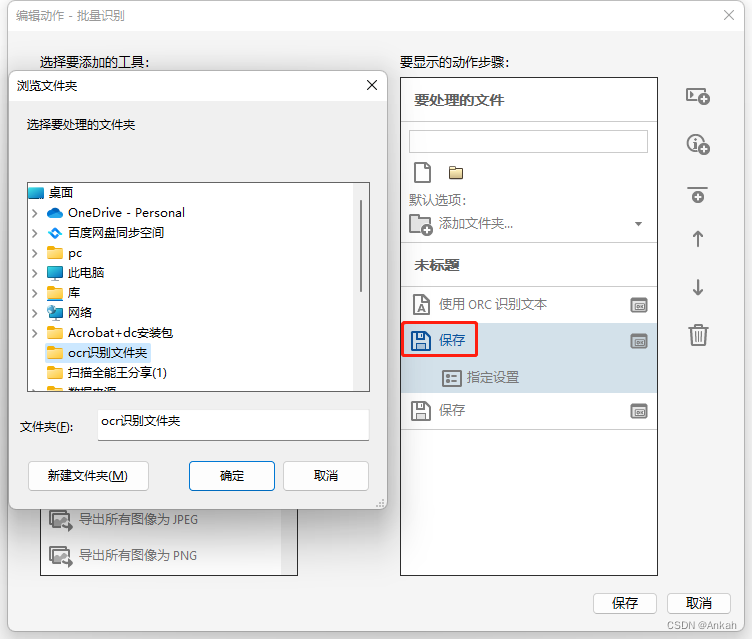
第三步:编辑自动化动作 从左侧栏中选择“使用OCR识别文本”“保存”“保存”三个工具添加到右侧,如下动作步骤: 需要注意的是,每个步骤都是可以编辑自定义的,接下来按照需求进行更改: 首先去掉 “使用OCR识别文本” 前面的勾,这样可以避免每次都询问用户
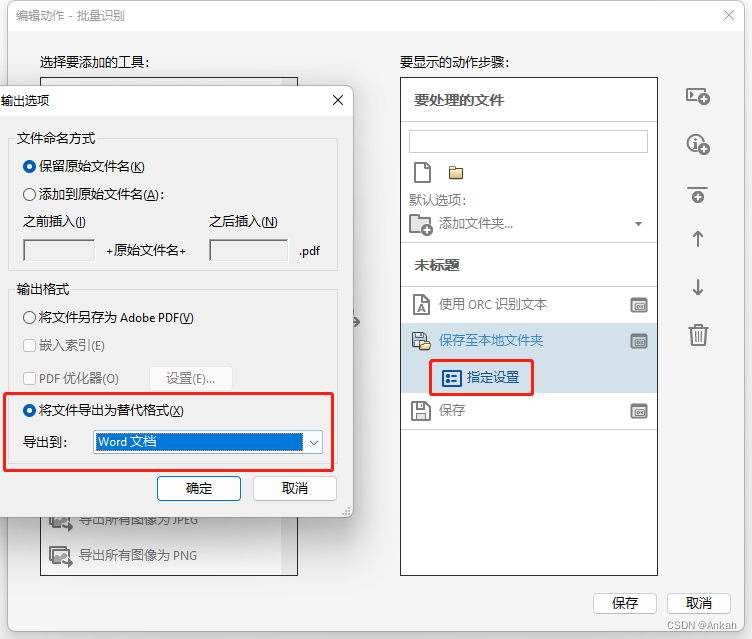
然后点击第一个“保存”,将其改为“保存至本地文件夹”,然后选择你想要批量导出的目录: 点击第一个“保存” 下方 “指定设置”,可以设置导出格式,这里选择“Word文档”
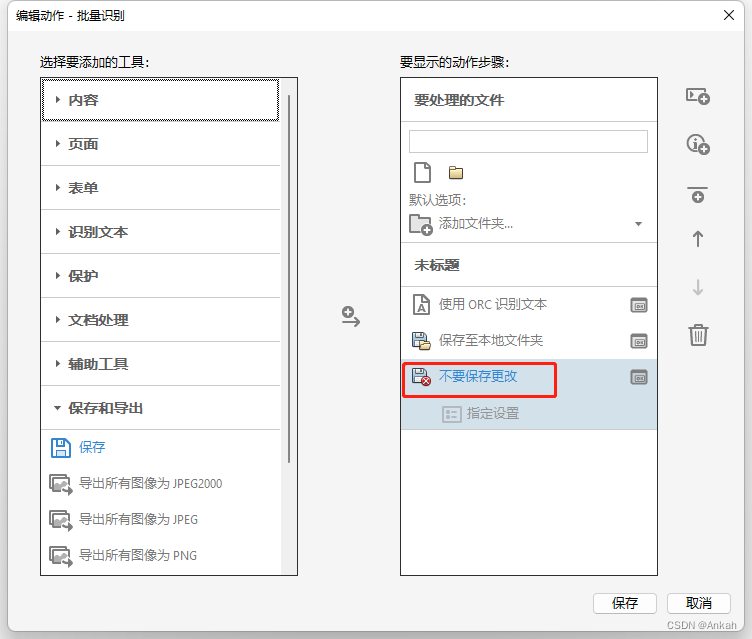
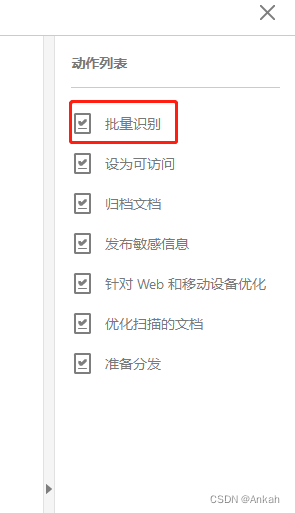
点击第二个“保存”,将其改为“不要保存更改”,这是为了防止每次执行完一个文件都要询问是否保存: 最后点击下方保存并自定义命名动作为“批量识别”,大功告成! 第四步:开始进行批量识别 设置完成后接下来就很简单了,在主页右侧动作列表中选择我们刚刚新建的自动化动作“批量识别”
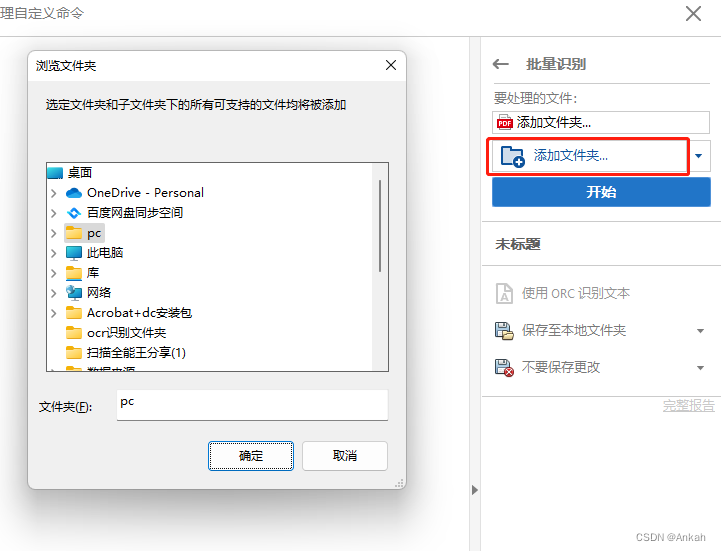
选择“添加文件夹”,选择你放有需要批量转化pdf的文件夹 点击下方的开始,等待转化完成,之后我们便可以在第三步中选择的保存文件夹中找到转化后的word文件了。 假如以后再需要进行类似的批量识别工作的时候都可以直接使用不需要再进行设置了,一劳永逸了属于是! |

【本文地址】
今日新闻 |
推荐新闻 |