常见聚类算法及使用 |
您所在的位置:网站首页 › 层次聚类有什么用 › 常见聚类算法及使用 |
常见聚类算法及使用
|
文章目录
前言层次聚类的实现聚类过程代码实现参考文献
前言
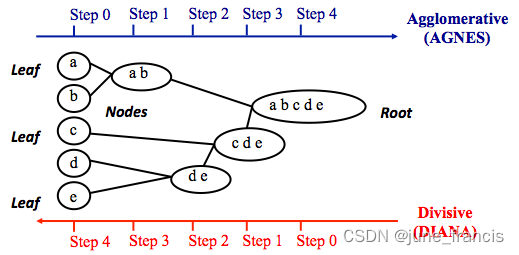
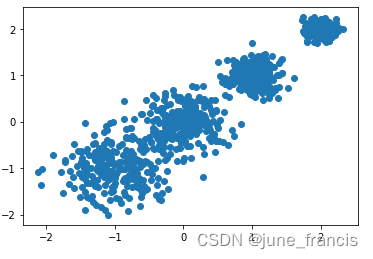
层次聚类顾名思义就是按照某个层次对样本集进行聚类操作,这里的层次实际上指的就是某种距离定义。 层次聚类最终的目的是消减类别的数量,所以在行为上类似于树状图由叶节点逐步向根节点靠近的过程,这种行为过程又被称为“自底向上”。 更通俗的,层次聚类是将初始化的多个类簇看做树节点,每一步迭代,都是将两两相近的类簇合并成一个新的大类簇,如此反复,直至最终只剩一个类簇(根节点)。 与层次聚类相反的是分裂聚类(divisive clustering),又名 DIANA(Divise Analysis),它的行为过程为“自顶向下”。 本文重点为大家介绍层次聚类。 我们先用之前构建的数据来完成一个简单的聚类: # 综合分类数据集 import numpy as np from sklearn.datasets import make_blobs from matplotlib import pyplot as plt # 创建数据集 # X为样本特征,Y为样本簇类别, 共1000个样本,每个样本2个特征,共4个簇, # 簇中心在[-1,-1], [0,0],[1,1], [2,2], 簇方差分别为[0.4, 0.2, 0.2, 0.2] X, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]], cluster_std=[0.4, 0.3, 0.2, 0.1], random_state=9) # 数据可视化 plt.scatter(X[:, 0], X[:, 1], marker='o') plt.show()
一般参数: n_clusters:一个整数,指定簇的数量。 connectivity:一个数组或者可调用对象或者为None,用于指定连接矩阵。它给出了每个样本的可连接样本。 affinity:一个字符串或者可调用对象,用于计算距离。可以为:‘euclidean’, ‘l1’, ‘l2’, ‘manhattan’, ‘cosine’, ‘precomputed’ 。 如果linkage=‘ward’,则 'affinity必须是 ‘euclidean’ 。 memory:用于缓存输出的结果,默认为不缓存。如果给定一个字符串,则表示缓存目录的路径。 n_components:将在scikit-learn v 0.18中移除 compute_full_tree:通常当已经训练了n_clusters之后,训练过程就停止。 但是如果compute_full_tree=True,则会继续训练从而生成一颗完整的树。 linkage:一个字符串,用于指定链接算法。 ‘ward’:采用方差恶化距离variance incress distance 。 ‘complete’:全链接complete-linkage算法,采用 d m a x d_{max} dmax。 ‘average’:均链接average-linkage算法,采用 d a v g d_{avg} davg。 ‘single’:单链接single-linkage算法,采用 d m i n d_{min} dmin 。 pooling_func:即将被废弃的接口。 属性: labels_:一个形状为[n_samples,] 的数组,给出了每个样本的簇标记。n_leaves_:一个整数,给出了分层树的叶结点数量。n_components_:一个整数,给除了连接图中的连通分量的估计值。children_:一个形状为[n_samples-1,2]数组,给出了每个非叶结点中的子节点数量。 for index, metric in enumerate(["cosine", "euclidean", "cityblock"]): model = AgglomerativeClustering( n_clusters=4, linkage="average", affinity=metric ) model.fit(X) print("%s Silhouette Coefficient: %0.3f" % (metric, metrics.silhouette_score(X, model.labels_, metric='sqeuclidean'))) plt.figure() plt.axes([0, 0, 1, 1]) for l, c in zip(np.arange(model.n_clusters), "rgbk"): row_ix = np.where(l == model.labels_) plt.scatter(X[row_ix, 0], X[row_ix, 1]) plt.axis("tight") plt.axis("off") plt.suptitle("AgglomerativeClustering(affinity=%s)" % metric, size=20) plt.show()展示结果如下: cosine Silhouette Coefficient: 0.370 euclidean Silhouette Coefficient: 0.816 cityblock Silhouette Coefficient: 0.820
接下来我们使用更为复杂的数据进行测试(以下示例来自于官方): # Author: Gael Varoquaux # License: BSD 3-Clause or CC-0 import matplotlib.pyplot as plt import numpy as np from sklearn.cluster import AgglomerativeClustering from sklearn.metrics import pairwise_distances np.random.seed(0) # Generate waveform data n_features = 2000 t = np.pi * np.linspace(0, 1, n_features) def sqr(x): return np.sign(np.cos(x)) X = list() y = list() for i, (phi, a) in enumerate([(0.5, 0.15), (0.5, 0.6), (0.3, 0.2)]): for _ in range(30): phase_noise = 0.01 * np.random.normal() amplitude_noise = 0.04 * np.random.normal() additional_noise = 1 - 2 * np.random.rand(n_features) # Make the noise sparse additional_noise[np.abs(additional_noise) |
 然后使用 sklearn.cluster.AgglomerativeClustering 完成聚类:
然后使用 sklearn.cluster.AgglomerativeClustering 完成聚类: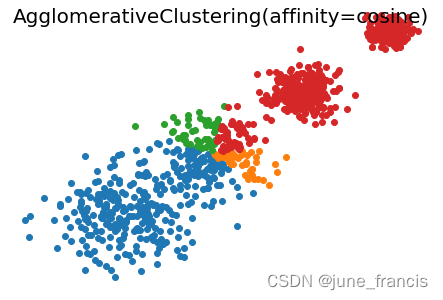
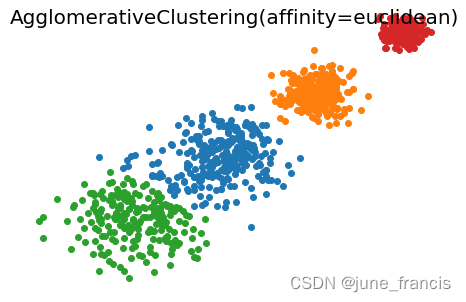
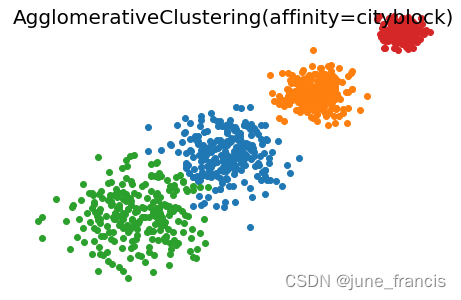 不难看出,当前场景使用 linkage='average' 和 affinity='euclidean' 的参数组合与 linkage='average' 和 affinity='cityblock' 时聚类效果更好。
不难看出,当前场景使用 linkage='average' 和 affinity='euclidean' 的参数组合与 linkage='average' 和 affinity='cityblock' 时聚类效果更好。【本文地址】