机器学习聚类 |
您所在的位置:网站首页 › 层次聚类算法基本原理 › 机器学习聚类 |
机器学习聚类
|
机器学习实验报告
〇、实验报告pdf可在该网址下载一、实验目的与要求二、实验内容与方法2.1 聚类算法学习与回顾2.1.1 聚类任务1)聚类任务的概念2)符号定义3)性能度量
2.1.2 K-means的算法模型1)优化问题2)迭代策略
2.1.3 K-means的算法流程2.1.4 K-means的算法分析1)复杂度:2)优点:3)缺点:
三、实验步骤与过程3.0 实验数据集与类标签对齐问题3.0.1 数据集3.0.2 类标签对齐问题和停止条件
3.1 二维或三维空间中的2-3类点(每个类有10个点)聚类实验3.1.1 实验说明
3.2 人脸图像聚类实验3.2.1 实验设计3.2.2 实验结果1. ORL数据集二类三类
2. AR数据集二类三类
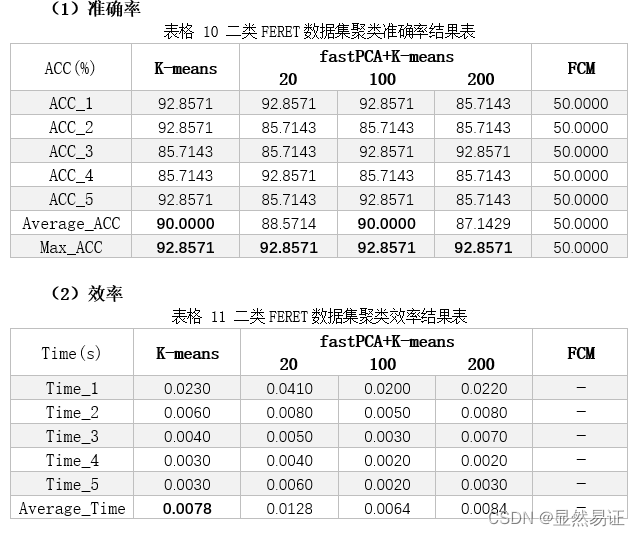
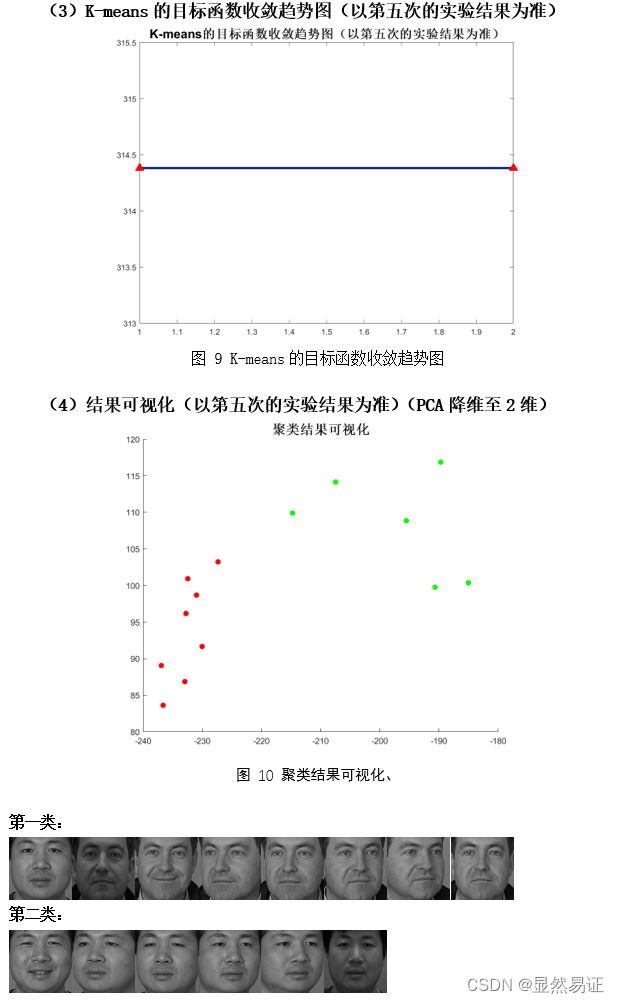
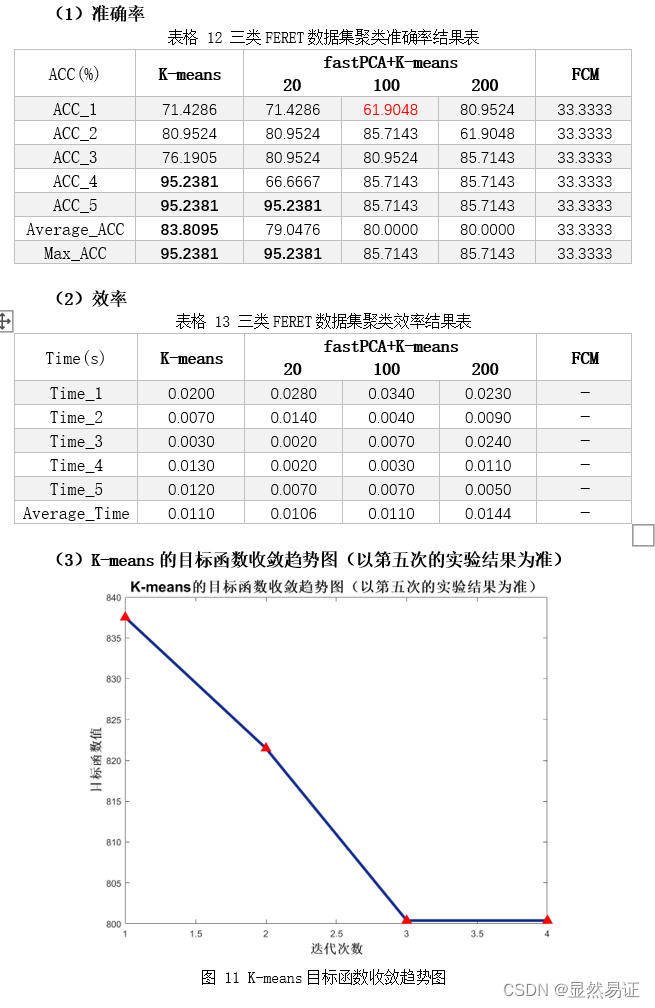
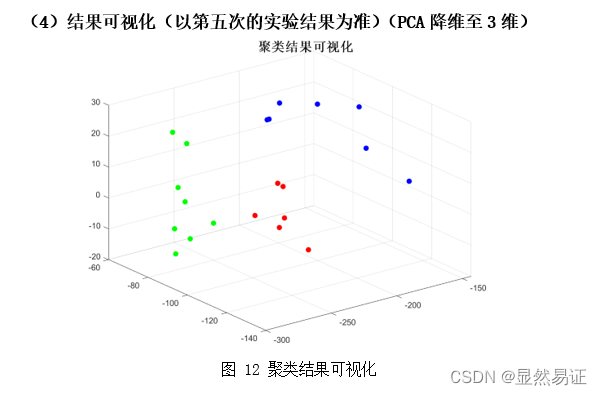
3. FERET数据集二类三类
3.2.3 实验分析
3.3 旋转物体图像聚类实验3.3.1 实验设计3.3.2 实验结果二类三类
3.3.3 实验分析
3.4 设计一个新的聚类算法
四、实验结论或体会4.1 实验结论4.2 实验体会
〇、实验报告pdf可在该网址下载
机器学习实验五:聚类 这个需要积分下载(因为实验报告后台查重,不建议直接白嫖)。 建议看博客,博客里面会有很多实验报告小说明会用【…】加粗注释。 一、实验目的与要求 简述K-Means聚类算法原理与算法过程。熟练掌握K-means聚类算法与结果的展示,并代码实现,做一个二维或三维空间中的2~3类点(每个类有10个点)聚类实验,把聚类结果用不同颜色与符号表示。实现人脸图像(取前23个人的人脸图像)聚类实验与旋转物体(在COIL20数据集中取前23个类的图像),把聚类结果用不同颜色与符号表示,并把对应的图像放在相应点的旁边,让人一眼看出结果对不对;同时,列表给出其在不同数据库在不同K时的聚类精度。参看前人论文,设计一个全新的聚类算法,把简要内容写在本实验报告中;把长文写好提交到 ”论文提交处“; 二、实验内容与方法 2.1 聚类算法学习与回顾 2.1.1 聚类任务根据周志华老师的《机器学习》一书中,来阐述聚类任务。 1)聚类任务的概念聚类试图将数据集中的样本划分为若干个通常时不相交的子集,每个子集称为一个“簇”,通过这样的划分,每个簇可能对应于一些潜在的概念。需说明的是,这些概念对聚类算法而言事先是未知的,聚类过程仅能自动形成簇结构,簇所对应的概念语义需由使用者来把握和命名。 聚类既能作为一个单独过程,用于找寻数据内在的分布结构,也可以作为分类等其他学习任务的前驱过程。例如,在一些商业应用中需对新用户的类型进行判别,但定义“用户类型”对商家来说却可能不太容易,此时,往往可先对用户数据进行聚类,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,用于判别新用户的类型。 2)符号定义
聚类性能度量亦称为聚类“有效性指标”。监督学习中的性能度量作用相似,对聚类结果,我们需通过某种性能度量来评估其好坏;另一方面,若明确了最终将要使用的性能度量,则可以直接将其作为聚类过程的优化目标,从而更好地得到符合要求的聚类结果。 聚类是将样本集D划分为若干互不相交的自己,即样本簇,那么,什么样的聚类结果比较好呢?直观上看,我们希望“物以类聚”,即同一簇的样本尽可能彼此相似,不同簇的样本尽可能不同。换言之,聚类结果的“簇内相似度”高,且“簇间相似度”低。 聚类性能度量大致有两类,一类是将聚类结果与某个“参考模型”进行比较,称为“外部指标”;另一类是直接考察聚类结果而不利用任何参考模型,称为“内部指标”。 2.1.2 K-means的算法模型 1)优化问题
K-means算法的复杂度为Ο(mnk),其中m是样本维数,n是样本个数,k是类别个数。 2)优点: 容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;处理大数据集的时候,该算法可以保证较好的伸缩性;当簇近似高斯分布的时候,效果非常不错;算法复杂度低。 3)缺点: K 值需要人为设定,不同 K 值得到的结果不一样;对初始的簇中心敏感,不同选取方式会得到不同结果;对异常值敏感;样本只能归为一类,不适合多分类任务;不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。 三、实验步骤与过程 3.0 实验数据集与类标签对齐问题 3.0.1 数据集(1) ORL56_46人脸数据集 该数据集共有40个人,每个人10张图片。每张图片像素大小为56×46。本次实验取该数据集下的前三个类,每个类有10个样本点。 (2) AR人脸数据集 该数据库由3个以上的数据库组成;126名受试者面部正面图像的200幅彩色图像。每个主题有26张不同的图片。对于每个受试者,这些图像被记录在两个不同的时段,间隔两周,每个时段由13张图像组成。所有图像均由同一台摄像机在严格控制的照明和视点条件下拍摄。数据库中的每个图像都是768×576像素大小,每个像素由24位RGB颜色值表示。本次实验取该数据集下的前三个类,每个类有26个样本点。 (3) FERET人脸数据集 该数据集一共200人,每人7张,已分类,灰度图,80x80像素。第1幅为标准无变化图像,第2,5幅为大幅度姿态变化图像,第3,4幅为小幅度姿态变化图像。第7幅为光照变化图像。本次实验取该数据集下的前三个类,每个类有7个样本点。 (4) COIL-20数据集 COIL-20 数据集是彩色图片集合,包含对 20 个物体从不同角度的拍摄,每隔 5 度拍摄一副图像,每个物体 72 张图像。每张图像大小进行了统一处理为 128x128。本次实验取该数据集下的前三个类,每个类有72个样本点。 3.0.2 类标签对齐问题和停止条件由于本次实验牵扯到类别的判断,这个需要考虑类标签对齐的情况。这里我使用了匈牙利算法来解决聚类问题识别率计算时出现的类标签不对齐的情况,具体函数可见ACC.m. 当目标函数值的变化不超过0.01时,迭代停止。 3.1 二维或三维空间中的2-3类点(每个类有10个点)聚类实验 3.1.1 实验说明本次实验将随机初始化一些点进行实验。每一个样本点有一个坐标和一个类标签。对于二类情况,生成20个点;针对三类情况,生成30个点。然后准确率按照聚类结果和原始类标签进行比对计算。 由于本实验的数据与ORL数据集非常类似(每个类有10个点),所以直接采用ORL数据集进行实验和可视化。实验结果见3.2.2.1. 3.2 人脸图像聚类实验 3.2.1 实验设计本次实验以ORL56_46、AR和FERET人脸数据集进行实验。为了尽量减少由于初始值造成的结果有较大差异,每组算法我会跑五次取其平均值作为其衡量标准。 3.2.2 实验结果 1. ORL数据集 二类
从以上三个数据集在2~3个类的聚类效果上来看,ORL的聚类效果是最好的,FERET在二类的情况较好,在三类的情况相对较差。而AR数据集在二类和三类的情况都相对较差。根据AR数据集的构成,我导出了二类情况下的AR数据集聚类结果,可以发现,K-means算法更倾向于将同一时间段的人脸照片聚集在一起,而不是按照人的类别进行聚类。相比之下,在AR数据集上进行三类的聚类效果就明显得到了改善。 因为K-means算法的聚类结果会受初始化严重影响,那么通过重复实验我们也可以得出这个结论,每次实验的准确率不是一成不变的,这也和目标函数收敛的迭代次数有关,初始化越好,迭代次数越合理,准确率越高。 3.3 旋转物体图像聚类实验 3.3.1 实验设计本次实验采用COIL-20数据集的前2~3个类别进行实验。为了尽量减少由于初始值造成的结果有较大差异,每组算法我会跑五次取其平均值作为其衡量标准。 3.3.2 实验结果 二类
可以发现,K-means算法对旋转数据集的二类聚类效果,三类效果一般,这是因为K-means比较适用于球形数据,旋转数据在拍摄过程中会因为角度问题导致图片类内的相似度较小,所以聚类效果不佳。根据K-means的假设:K均值假设每个变量的分布是球形的;所有的变量具有相同的方差;具有相同的先验概率,要求每个类拥有相同数量的观测。可以得出以上K-means算法的缺点,单纯使用K-means算法不仅耗时长,而且聚类效果差,此时如果结合PCA降维再聚类就可以明显发现:不仅效率得到了提升、而且二类问题上识别率最高可以达到100%,效果明显改善。从另一方面可以看出初始换对聚类很重要。如果初始化的点靠的比较近,K-means会趋向于聚成一个类,导致准确率只有50%。 【不献丑了,跳过跳过】 四、实验结论或体会 4.1 实验结论本次实验的实验结论如下: K-means算法ORL的聚类效果是最好的,FERET在二类的情况较好,在三类的情况相对较差。而AR数据集在二类和三类的情况都相对较差。根据AR数据集的构成,我导出了二类情况下的AR数据集聚类结果,可以发现,K-means算法更倾向于将同一时间段的人脸照片聚集在一起,而不是按照人的类别进行聚类。相比之下,在AR数据集上进行三类的聚类效果就明显得到了改善。因为K-means算法的聚类结果会受初始化严重影响,那么通过重复实验我们也可以得出这个结论,每次实验的准确率不是一成不变的,这也和目标函数收敛的迭代次数有关,初始化越好,迭代次数越合理,准确率越高。K-means算法对旋转数据集的二类聚类效果,三类效果一般,这是因为K-means比较适用于球形数据,旋转数据在拍摄过程中会因为角度问题导致图片类内的相似度较小,所以聚类效果不佳。根据K-means的假设:K均值假设每个变量的分布是球形的;所有的变量具有相同的方差;具有相同的先验概率,要求每个类拥有相同数量的观测。可以得出以上K-means算法的缺点,单纯使用K-means算法不仅耗时长,而且聚类效果差,此时如果结合PCA降维再聚类就可以明显发现:不仅效率得到了提升、而且二类问题上识别率最高可以达到100%,效果明显改善。从另一方面可以看出初始换对聚类很重要。如果初始化的点靠的比较近,K-means会趋向于聚成一个类,导致准确率只有50%。FCM在人脸聚类问题上效果并不是很好,往往FCM会因为隶属度的大小而趋向于聚成一个类,导致准确率低,进而导致准确率较低。FCM在UCI数据集上往往比K-means算法更有,一方面可能是因为维数大小不同,另一方面,猜想是因为人脸具有共同的特征,所以每个样本的隶属度会趋于一致。 4.2 实验体会本次实验主要内容是聚类,这类机器学习算法相对比较容易,也是我最熟悉的机器学习模块。本次实验将K-means,fastPCA+K-means(20维,100维,200维)和FCM在人脸聚类问题上进行准确率和效率的对比。本次实验也做的比较丰富,之前也和学长一起参与过聚类算法的研究,PCM、RCM、PRFCM等一些算法也可以尝试在人脸识别的问题上做做实验。对于K-means和FCM会趋向于收敛到一个类的问题,也有专门的论文去研究此类问题,但是这种弊端在人脸聚类的任务中会更加突出。 聚类在数学建模中是一种评价类的方法,非常常用也很有意思,我也对聚类问题非常感兴趣,后期可能会继续尝试一些有关于聚类算法的研究。最后,向提出和创新算法的科研工作者致敬!
|




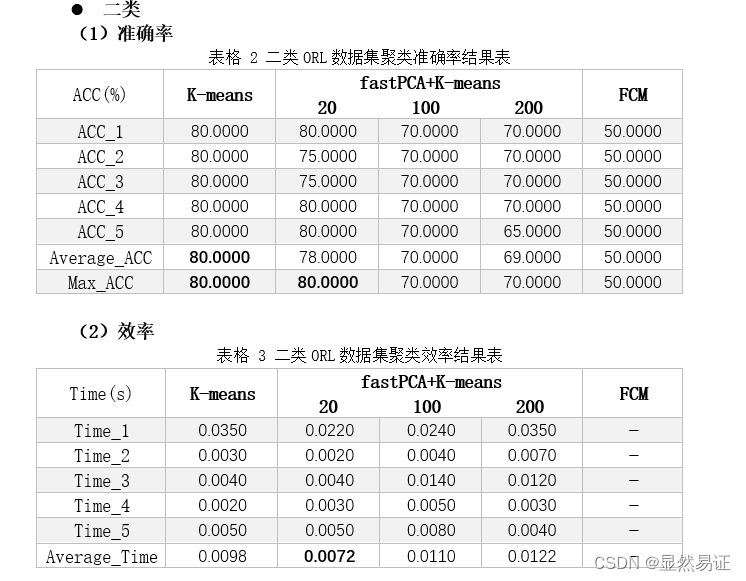
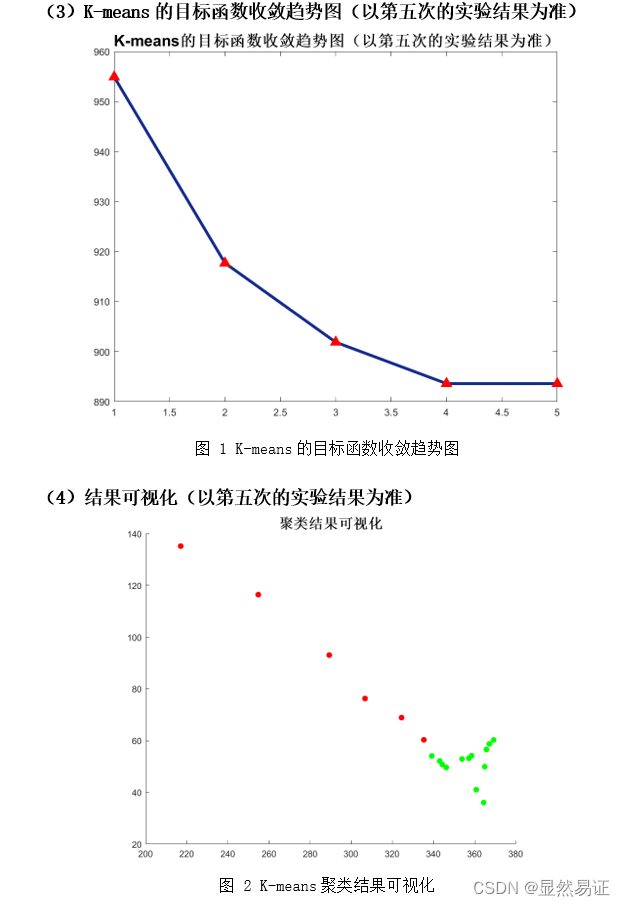

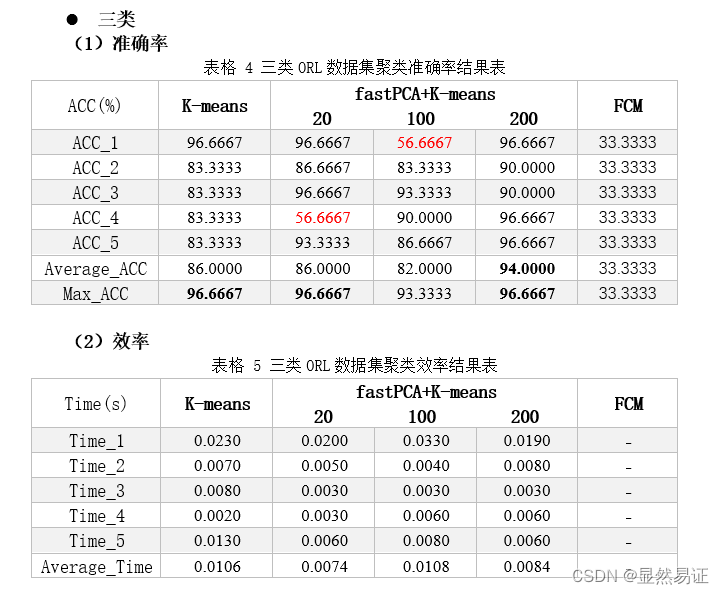
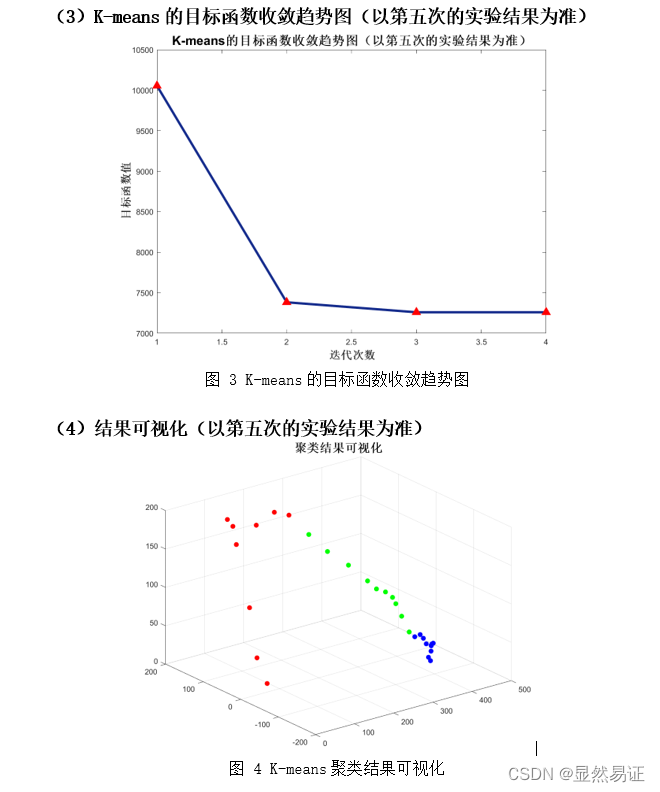
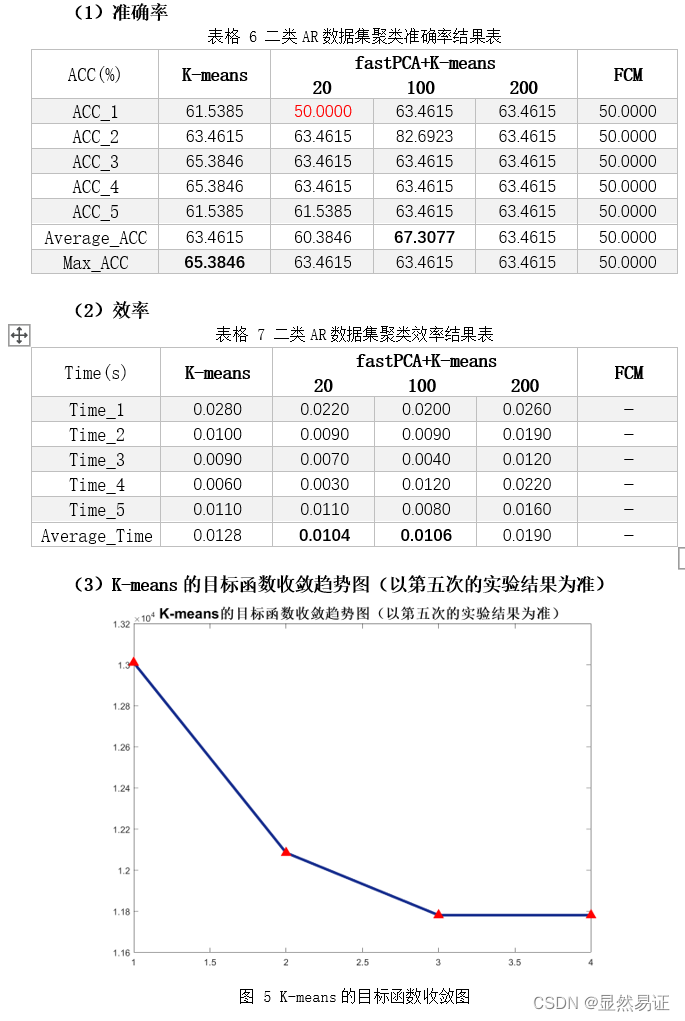
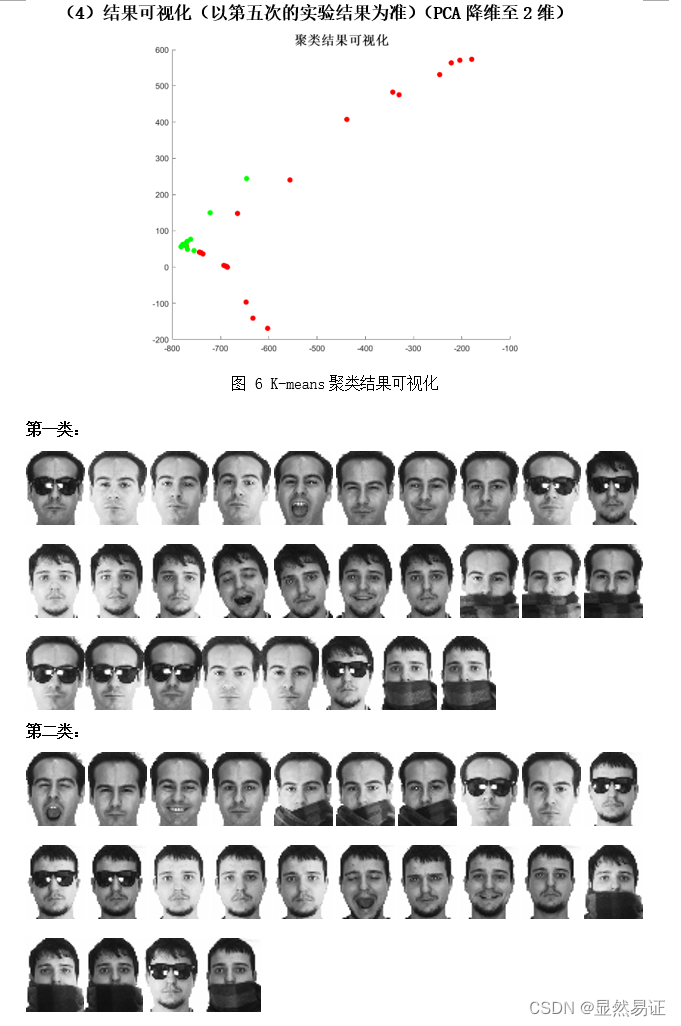
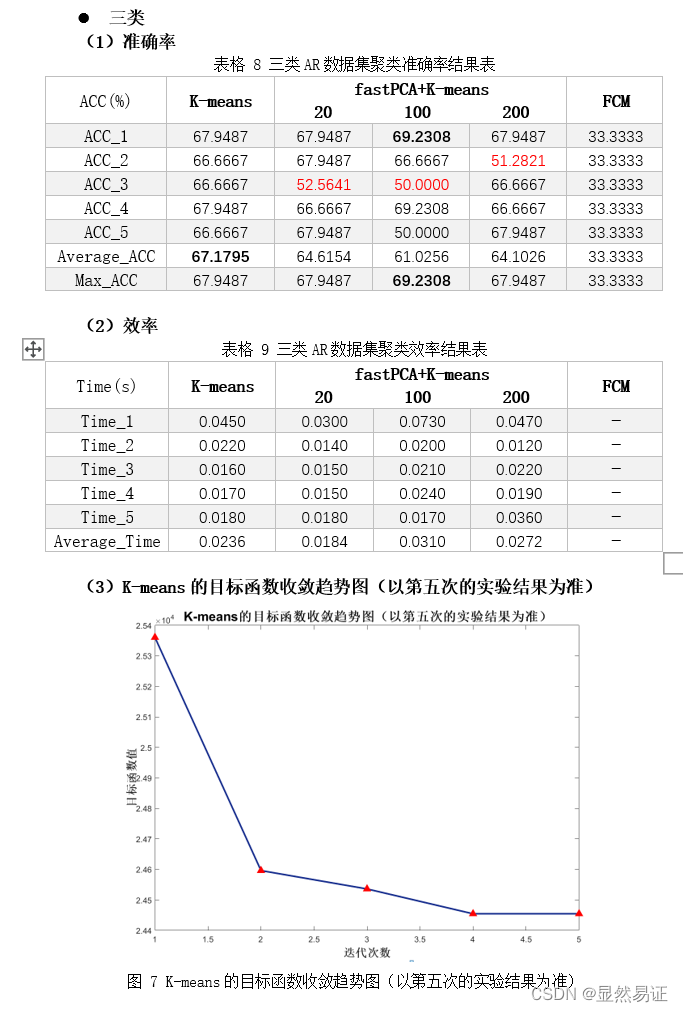
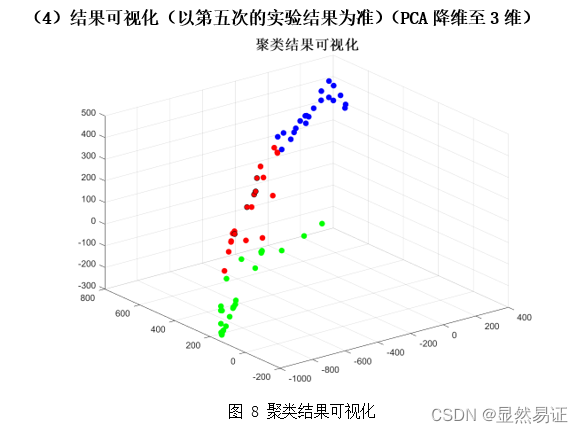
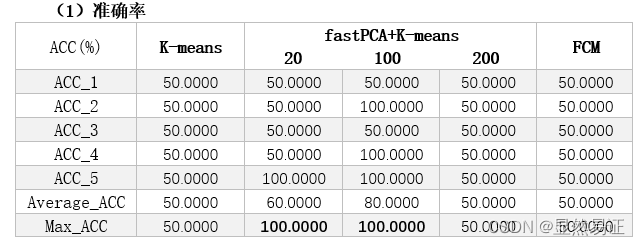
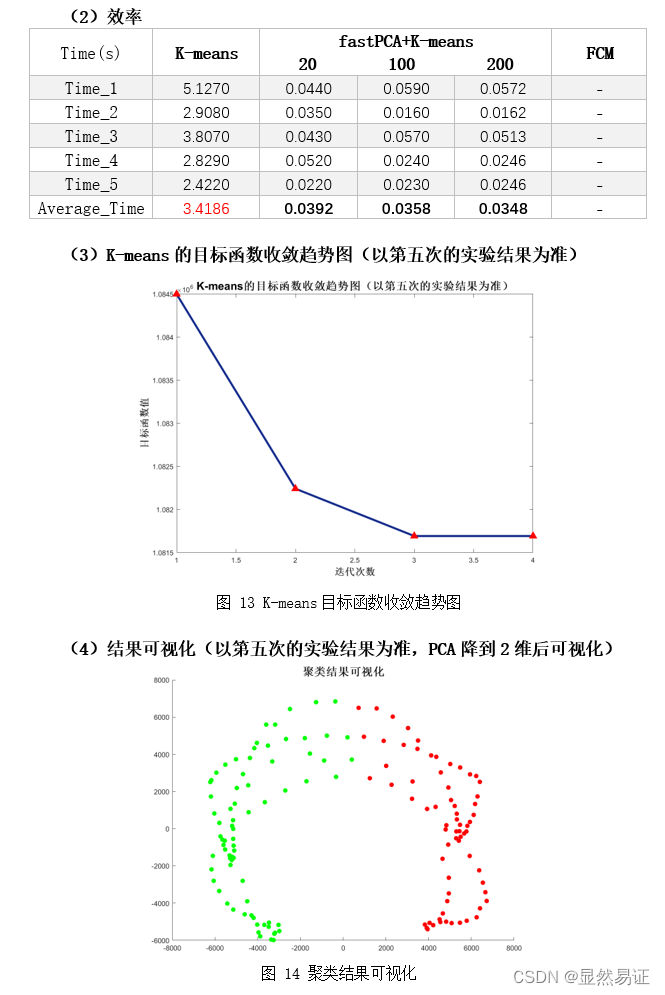
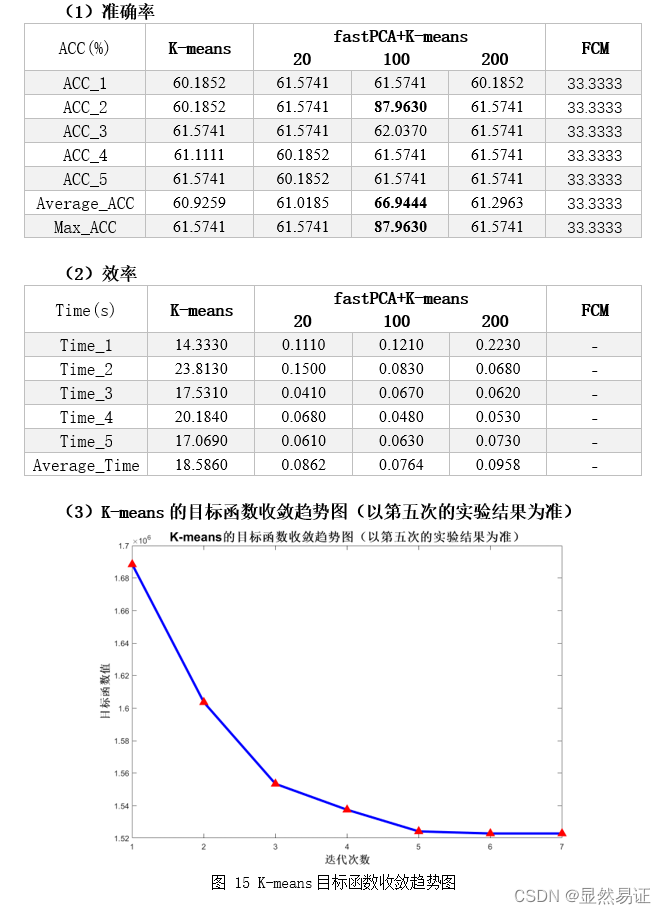
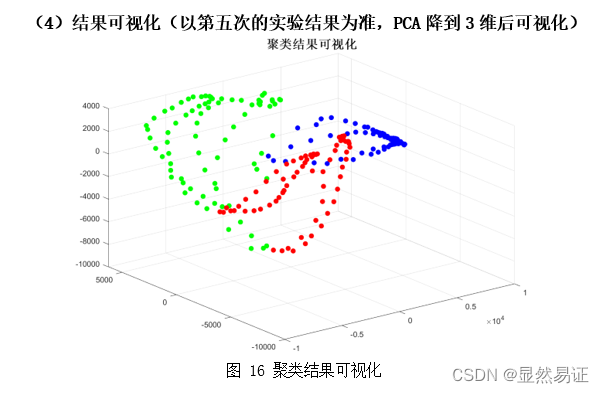
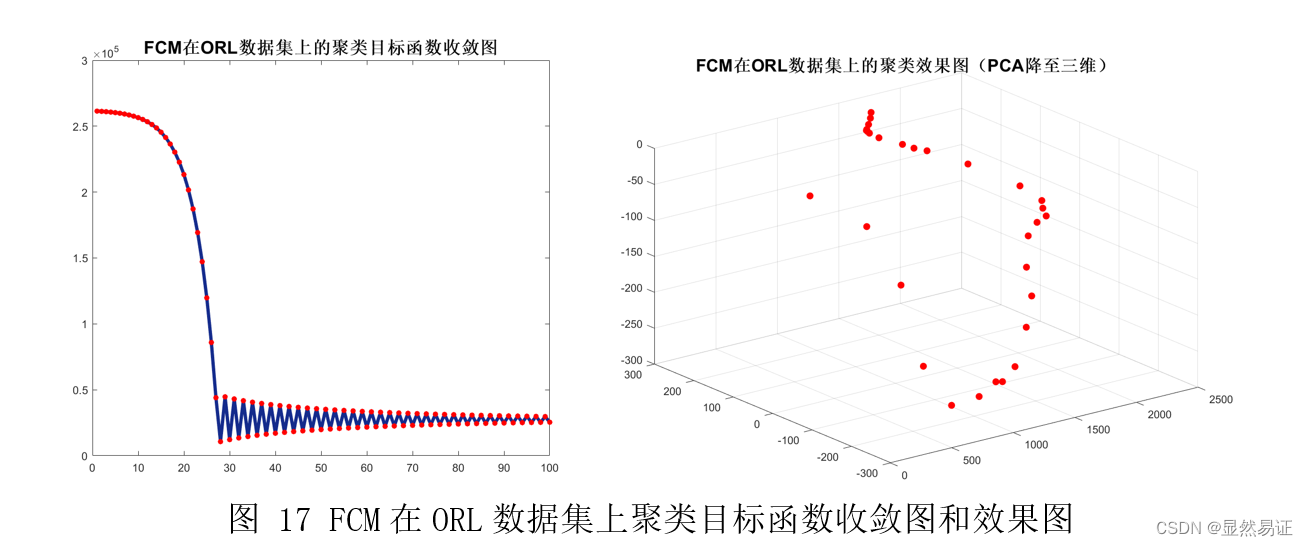 根据上面两幅图,我们发现FCM在人脸聚类问题上效果并不是很好,往往FCM会因为隶属度的大小而趋向于聚成一个类,导致准确率低,进而导致准确率较低。FCM在UCI数据集上往往比K-means算法更有,一方面可能是因为维数大小不同,另一方面,人脸具有共同的特征。
根据上面两幅图,我们发现FCM在人脸聚类问题上效果并不是很好,往往FCM会因为隶属度的大小而趋向于聚成一个类,导致准确率低,进而导致准确率较低。FCM在UCI数据集上往往比K-means算法更有,一方面可能是因为维数大小不同,另一方面,人脸具有共同的特征。
【本文地址】
今日新闻 |
推荐新闻 |