【深度学习】基于BERT模型的情感分析(附实战完整代码+数据集) |
您所在的位置:网站首页 › 对动物比对人的感情深是正常的吗知乎全文 › 【深度学习】基于BERT模型的情感分析(附实战完整代码+数据集) |
【深度学习】基于BERT模型的情感分析(附实战完整代码+数据集)
|
🌸个人主页:Yang-ai-cao
📕系列专栏:深度学习
🍍 博学而日参省乎己,知明而行无过矣
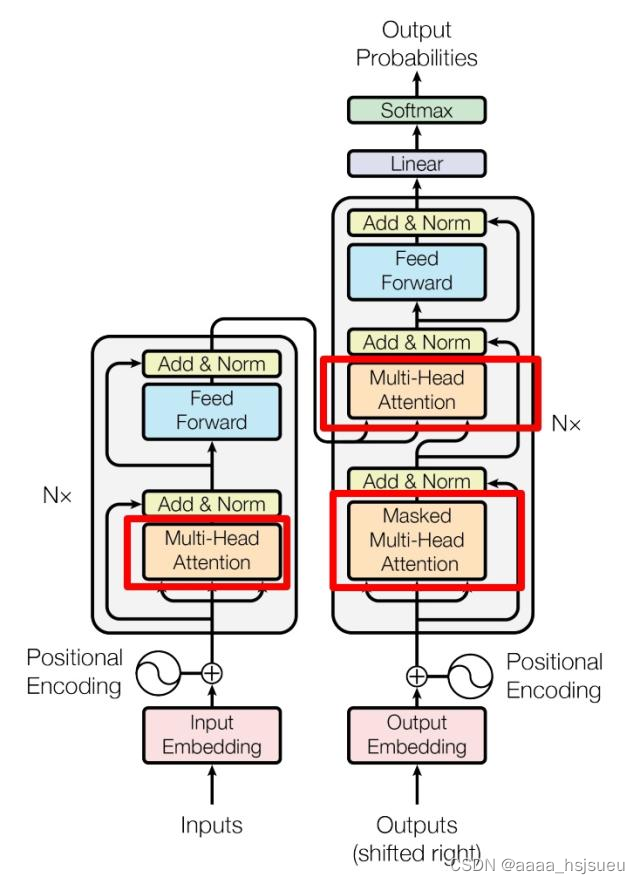
目录 目录 个人主页:Yang-ai-cao 系列专栏:深度学习 博学而日参省乎己,知明而行无过矣 1.BERT介绍 2.BERT结构 3.输入表示 4.BERT训练 4.1 MLM(Masked Language Model) 4.2 NSP(Next Sentence Prediction) 5.BERT微调 6.BERT、GPT、ELMo的比较 7.BERT模型实现情感分类(代码示例) 7.1 导入必要的库 7.2. 加载和处理数据 7.3 转换为 DataFrame 并分割数据集 7. 4 转换为 datasets 格式 7.5 加载 BERT 分词器和模型 7.6 预处理数据集 7.7 创建数据填充器 7.8 设置训练参数 7.9 创建 Trainer 实例 7.10 训练模型并保存 8 运行代码 完成以上代码任务后,我们开始运行: 9 保存模型 如何部署API与网页? 敬请关注!!!!!!!! 1.BERT介绍BERT的全称为Bidirectional Encoder Representation from Transformers,是一个预训练的语言 表征模型,它强调不再像以往一样采用传统的单向语言模型或者把两个单向语言模型进行浅层拼接的方法进行预训练。它旨在通过在所有层中对左右上下文进行联合调节,采用新的masked language model(MLM),用于语言理解的深度双向转换器的预训练,从未标记的文本中预训练深度双向表示。因此,只需一个额外的输出层即可对预训练的 BERT 模型进行微调,从而为各种任务(例如问答和语言推理)创建较为先进的模型,而无需对特定于任务的架构进行大量修改。 · BERT在 11 项自然语言处理任务上获得了最先进的新结果,包括将 GLUE 分数提高到 80.5% (绝对提高 7.7%),将 MultiNLI 准确率提高到 86.7%(绝对提高 4.6%),将 SQuAD v1.1 问答测试 F1 提高到 93.2(绝对提高 1.5 分),将 SQuAD v2.0 测试 F1 提高到 83.1(绝对提高5.1 分)。 · BERT的网络架构主要使用的是《Attention is all you need》中提出的多层Transformer结构,Transformer结构在NLP领域中已经得到了广泛应用,其最大的特点是抛弃了传统的RNN和CNN。通过Self-Attention机制将任意位置的两个单词的距离进行特定转换,有效的解决了NLP 中棘手的长期依赖问题。 2.BERT结构BERT利用MLM进行预训练并且采用深层的双向Transformer组件进行构建模型,总体结构是将多个Transformer Encoder一层一层地堆叠起来。在论文中,作者分别用12层和24层Transformer Encoder组装出两套BERT模型,两套模型的参数总计分别为110M和340M。(Transformer模型详解(图解最完整版) - 知乎 (zhihu.com))
图2.1 Transformer整体结构 隐藏Transformer详细结构,表示如下:
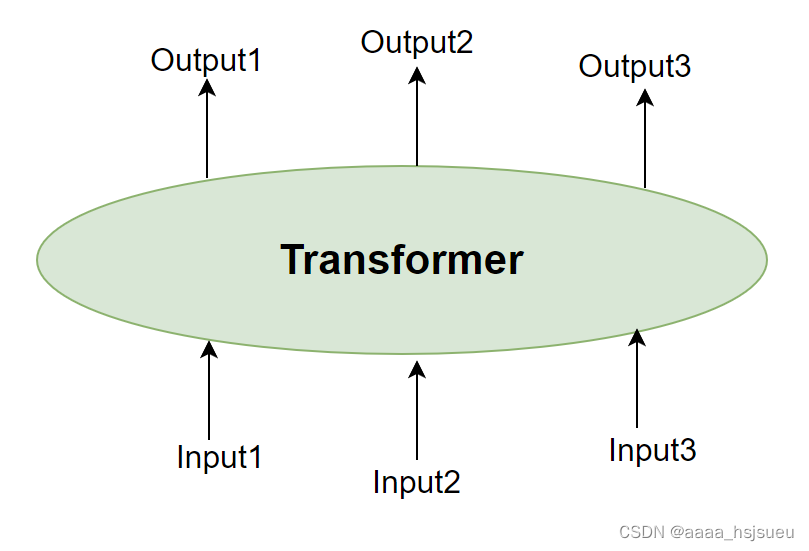
图2.2 Transformer黑箱图 Transformer结构进行堆叠,形成更深的神经网络(可理解为将Transformer encoder进行堆叠):
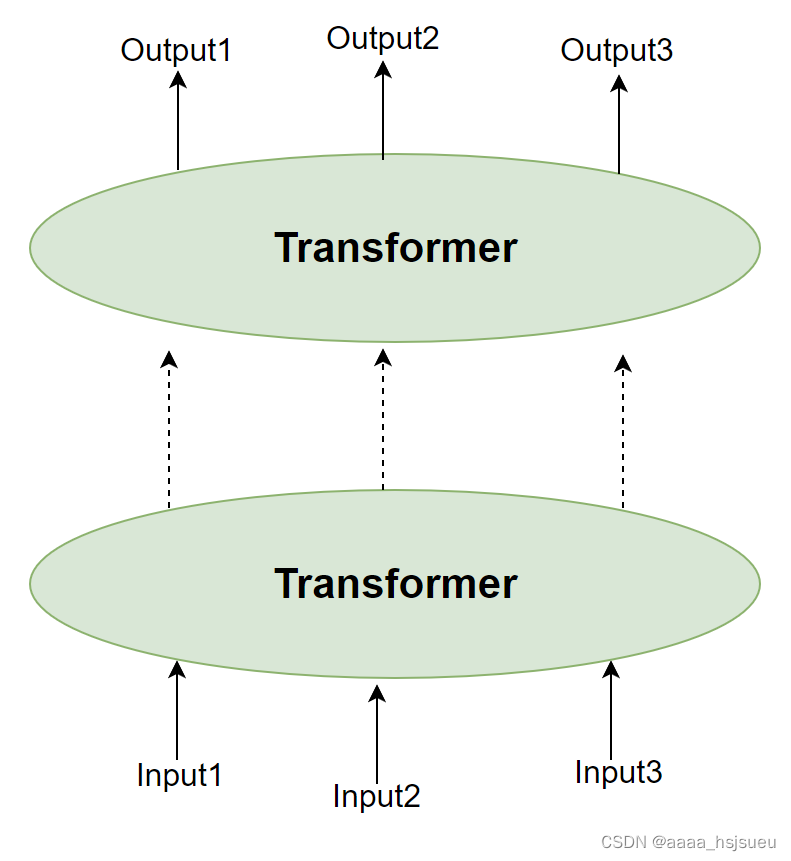
图2.3 多层堆叠Transformer 经过多层Transformer结构的堆叠后,形成BERT的主体结构(可视化:大雄007):
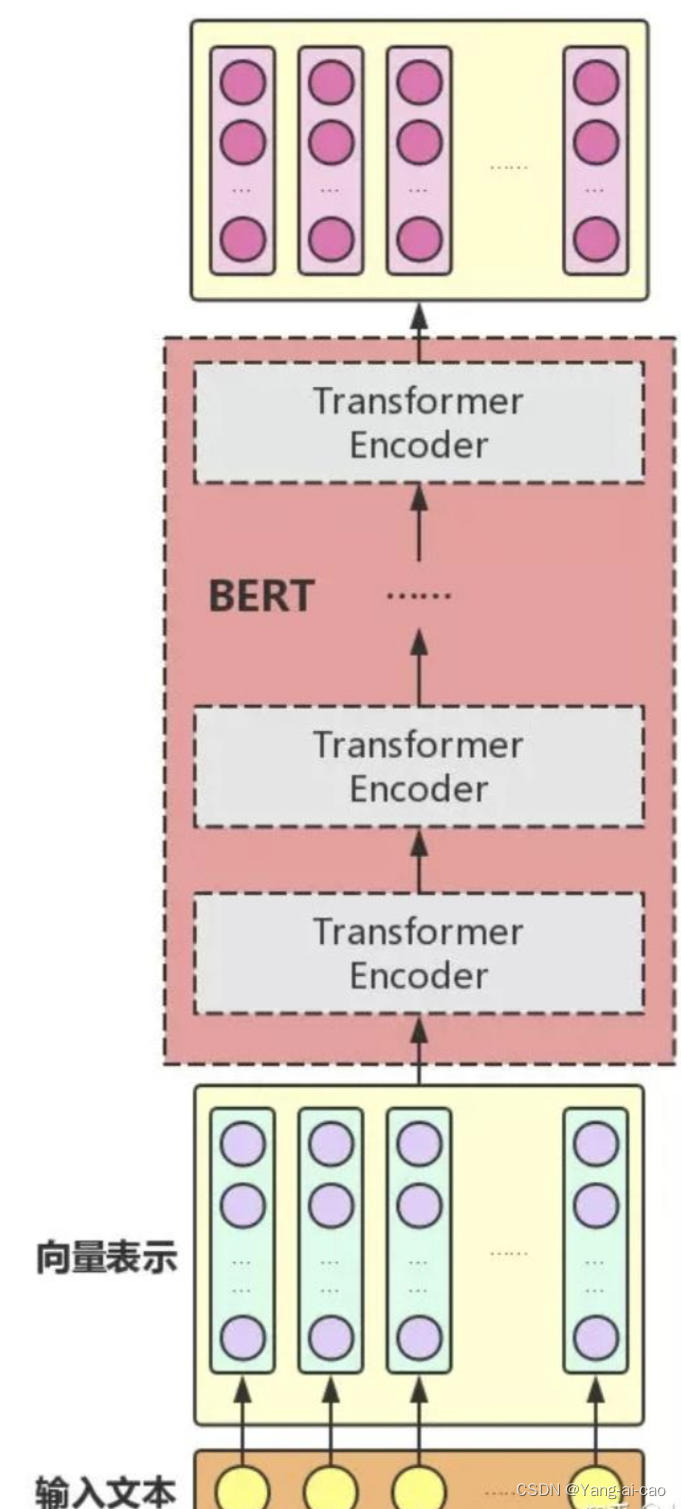
图2.4 Bert整体结构
图2.5 BERT的总体预训练和微调程序 3.输入表示
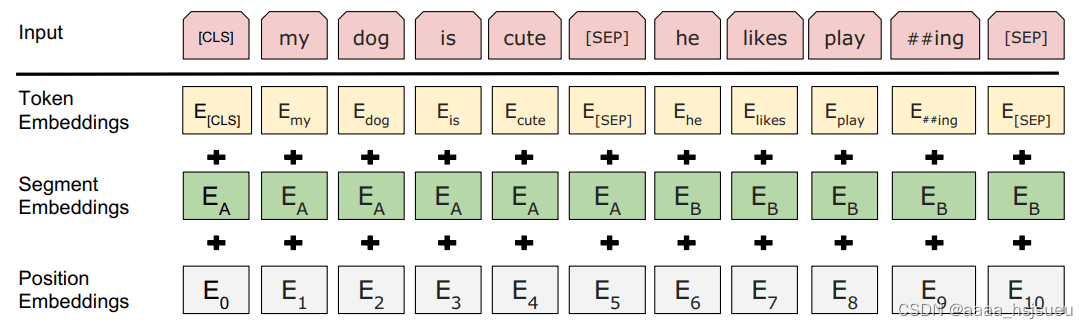
图3.1 token表征的组成 输入向量由三层组合: 3.1.Token Embeddings 即词向量。 · 要将各个词转换成固定维度的向量。中文目前尚未对输入文本进行分词,而是直接对单子构成为本的输入单位。特别的,英文词汇会做更细粒度的切分,比如上图中的playing 切割成 play 和 ##ing;将词切割成更细粒度的 Word Piece 是为了解决未登录词的常见方法。 · [CLS] 表示开始标志,同时[CLS]表示该特征用于分类模型,对非分类模型,该符号可以省去。[SEP]表示分句符号,用于断开输入语料中的多个句子。 · Bert 在处理英文文本时只需 30522 个词,Token Embeddings 层会将每个词转换成 768 维向量,例如:‘I like dog’ ,3个Token 会被转换成一个 (5, 768) 的矩阵或 (1, 5, 768) 的张量。 3.2. Segment Embeddings 段落向量。 · BERT 能够处理对输入句子对的分类任务,这类任务就像判断两个文本是否语义相似。句子对中的两个句子被简单的拼接在一起后送入到模型中,BERT通过segment embeddings去区分一个句子对中的两个句子,因为预训练不单单做LM,还得做以两个句子为输入的分类任务。 · Segement Embeddings 层有两种向量表示,前一个向量是把 0 赋值给第一个句子的各个 Token,后一个向量是把1赋值给各个 Token,问答系统等任务要预测下一句,因此输入是有关联的句子。而文本分类只有一个句子,那么 Segement embeddings 就全部是 0。 3.3. Position Embeddings 位置向量。 · |

【本文地址】
今日新闻 |
推荐新闻 |