爬虫小试 |
您所在的位置:网站首页 › 如何用爬虫抓取图片和文字 › 爬虫小试 |
爬虫小试
|
emmm,因为要刷作业的试题(QWQ题目实在是太多了),在机缘巧合之下竟发现老师上传的题目全部是某网站上的,于是乎哈哈哈,爬下来做题库方便查询(Ctrl+F),下面进入正题,爬 使用到的模块 requests Xpath(lxml) docx(python-docx) 首先给出目标网页的URL:http://www.manongjc.com/detail/7-tyzzyvdyjzszbif.html 然后,肯定是让咱瞧瞧这个网页的真面目(源码结构)是什么,操作很简单,我使用的是Google浏览器开发者工具,源码部分如下图所示
里 知道了需要的东西在哪,接下来就好办了,问题是怎么获取到它了 先使用requests请求获得网页的HTML文rs = requests.get(url=url, headers=headers) 进一步,对获取得到的rs进行处理解析,这里使用到Xpath的知识 root = etree.HTML(rs.content) texts = root.xpath('//div[@class="article-content"]/p/text()')我们在控制台看看texts有没有成功解析出来 不要紧,紧接着,我们对获取到的texts处理优化一下 for text in texts: str(text).replace('\xa0\xa0\xa0', '') print(text)瞅瞅看 最后肯定要有一个文本储存它,不然在控制台看多不方便呀,我们就先用自带的txt文件吧 f = open('javaWeb.txt', 'w', encoding='utf-8') for text in texts: str(text).replace('\xa0\xa0\xa0', '') f.write(text+'\n') print(text) f.close()goodjob,到此,我们需要的试题就爬下来了,炒鸡简单有木有 等等等,说好的使用到的模块里有docx呢,怎么没用到,博主骗人 哈哈哈,本来用txt是可以的了,后来因为有位小仙女说txt文件看起来不习惯,然后我就把爬下来的试题用word保存了,导入docx模块,把上述的代码更换为 document = Document() for text in texts: str(text).replace('\xa0\xa0\xa0', '') document.add_paragraph(text) print(text) document.save('javaweb.docx')这样就行了 最后,放上源码,方便大家借鉴 import requests from lxml import etree from docx import Document if __name__ == '__main__': headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'} url = 'http://www.manongjc.com/detail/7-tyzzyvdyjzszbif.html' rs = requests.get(url=url, headers=headers) root = etree.HTML(rs.content) texts = root.xpath('//div[@class="article-content"]/p/text()') document = Document() for text in texts: str(text).replace('\xa0\xa0\xa0', '') document.add_paragraph(text) print(text) document.save('javaweb.docx') |
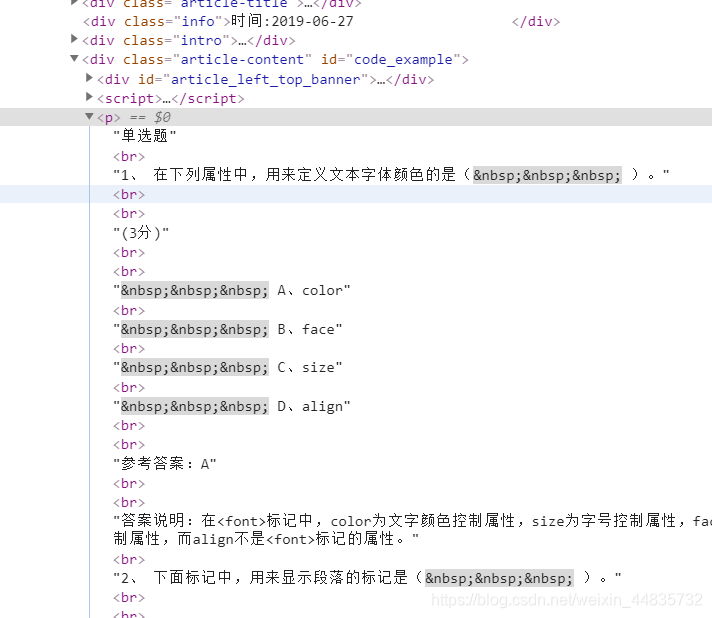 很显然,我们需要的试题都在
很显然,我们需要的试题都在 很不错,到这里,我们的目的已经实现了一大半了,可是有好多`\xa0\xa0\xa0’(这是什么东西,好影响阅读呀)
很不错,到这里,我们的目的已经实现了一大半了,可是有好多`\xa0\xa0\xa0’(这是什么东西,好影响阅读呀) OK,处理的不错
OK,处理的不错【本文地址】
今日新闻 |
推荐新闻 |