简化基因组DNA甲基化测序(RRBS)实验怎么做 |
您所在的位置:网站首页 › 基因组富集分析怎么做 › 简化基因组DNA甲基化测序(RRBS)实验怎么做 |
简化基因组DNA甲基化测序(RRBS)实验怎么做
|
简化基因组DNA甲基化测序(RRBS)实验怎么做? 大家好,这是专注表观组学十余年,领跑多组学科研服务的易基因。 上次我们分享了:全基因组DNA甲基化实验怎么做?手把手教你做全基因组DNA甲基化测序分析,深受同学们的欢迎。 本期,易基因小编给您讲讲简化基因组DNA甲基化实验怎么做,从技术原理、建库测序流程、信息分析流程等三方面详细介绍。 一、简化基因组DNA甲基化测序(RRBS)技术原理 简化基因组甲基化测序 (Reduced Representation Bisulfite Sequencing, RRBS) 是通过限制性酶切的方法富集基因组DNA 上富含 CCGG 位点的片段,经 Bisulfite 处理和高通量测序技术进行基因组 CpG 富集区域内的单碱基分辨率的甲基化测序[3]。相对 WGBS 而言 RRBS 技术作为高性价比的甲基化测序方案, 其测序量大幅减少,在大规模临床样本研究中具有广泛的应用价值。 简化基因组甲基化测序利用重亚硫酸氢盐能够将未甲基化的胞嘧啶(C)转化为胸腺嘧啶 (T)的特性,将基因组用重亚硫酸氢盐处理后测序,即可根据单个 C 位点上未转化为 C 未转化为 T 的 reads 数目与所有覆盖的 reads 数目的比例,计算得到甲基化率。该技术对于全面研究胚胎发育、衰老机制、疾病发生发展的表观遗传机制,以及筛选疾病相关的表观遗传学标记位点具有重要的应用价值。 简化基因组甲基化测序原理示意图如下: 二、简化基因组DNA甲基化测序(RRBS)技术流程
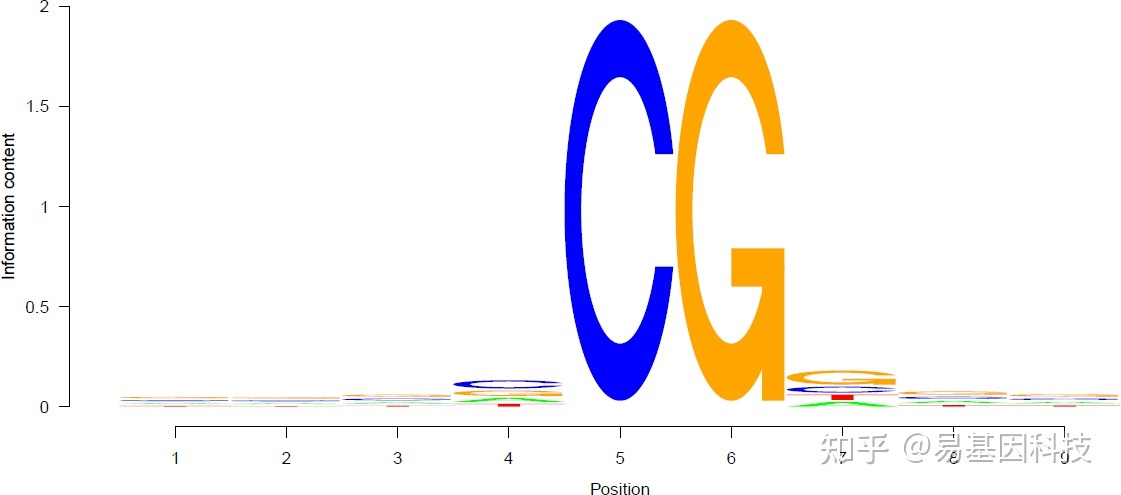
(一) DNA样品检测 对DNA样品的检测主要包括2种方法: (1)Qubit对DNA浓度进行精确定量; (2)琼脂糖凝胶电泳分析DNA降解程度以及是否有污染; (二) 文库构建 (1)基因组 DNA 提取:根据不同的样品类型采用不同的提取方案,获取高质量的基因组 DNA。 (2)DNA 质量检测:Qubit 检测 DNA 样品浓度,琼脂糖凝胶电泳检测 DNA 样品完整性。 (3)限制性酶切:通过酶切富集 CpG 片段。 (4)末端修复,加 A,甲基化接头连接:在 DNA 分子两端引入接头序列及 index 序列。 (5)选择 CpG 富集的 DNA 片段:电泳回收选择富含 CpG 的 250-500 bp 片段。 (6)Bisulfite 转化:回收的基因组 DNA,加入 lamda DNA(一种噬菌体 DNA,用于监测重亚硫酸盐测序的转化效率),随后通过 Bisulfite 处理将非甲基化碱基 C 转化成 U。 (7)PCR :PCR 扩增富集文库及纯化PCR产物获得最终文库。 (三) 文库质检 文库构建完成后,先使用Qubit2.0进行初步定量,稀释文库至1ng/μl,随后使用Agilent 2100对文库的insert size进行检测,insert size符合预期后,使用qPCR方法对文库的有效浓度进行准确定量(文库有效浓度> 2nM),以保证文库质量。 (四) 上机测序 文库检测合格后,把不同文库按照有效浓度及目标下机数据量的需求pooling后在illumina Nova平台测序,测序策略为PE150。 三、简化基因组DNA甲基化测序(RRBS)信息分析流程 将测序结果与参考基因组比对,比对上唯一位置的序列用于后续标准信息分析及个性化分 析。信息分析流程如下: 图2:RRBS信息分析流程示意图 (一)测序数据质控和统计 1、数据产出与质控 测序完成后,对数据进行去除接头序列和低质量过滤,随后将过滤后的数据与参考基因组比对。数据过滤标准为:包含adapter 序列,序列中N 碱基的比例超过序列总长度的5%,序列中质量值小于 5 的碱基比例超过序列总长度的 50%,如果一条序列符合以上三个条件中的任何一个,则去除这条序列。 2、C 碱基有效测序深度的累积分布和覆盖度 以下图为示例,反映了 CpG,CHG 和 CHH 碱基有效测序深度的累积分布(基于有效数据计算)。其中横轴表示碱基有效测序深度,纵轴表示一定测序深度下碱基的覆盖度(占基因组总位点的比率)。 图3:CpG,CHG 和 CHH 碱基累积深度和覆盖度 (二)样品整体甲基化水平 1、全基因组甲基化水平 每一个甲基化 C 碱基的甲基化水平均按如下公式进行计算:C 位点的甲基化水平 = 100 * 支持甲基化的 reads / (支持甲基化的 reads + 支持非甲基化的 reads)。全基因组平均甲基化水平反应了基因组甲基化图谱的总体特征。以下图为示例,反映了样本的整体甲基化率分布, X 轴表示不同的甲基化率范围,Y 轴表示不同甲基化率范围内 C 位点数目的百分比。可以看出低甲基化C 位点比例较高。后续分析均采用 5X 以上 C 位点。 图4:C位点在不同甲基化率范围的百分比 2、全基因组C碱基的平均甲基化水平 不同分布类型的甲基化C 位点(mC)在不同物种基因组中出现比例不同,因此,各类型甲基化C 位点( mCG、mCHG 和 mCHH ) 的数目,及其在全部 mC 的位点中所占的比例 ( 例:mCHG 所占比例= mCHG 数目/mC 的总数 ),在一定程度上反映了特定物种的全基因组DNA 甲基化修饰特征。 图5:全基因组C 位点平均甲基化水平 3、全基因组三种类型甲基化位点的比例分布 计算全基因组中 CG, CHG 和 CHH 三种类型的甲基化位点的数量和比例。 图6:CG, CHG 和 CHH 三种类型的甲基化位点的数量和比例 4、染色体水平的甲基化和C碱基密度分布 从染色体水平来描述甲基化 C 碱基的的分布情况(仅>50M 的序列)。绿色细线表示以 10kb 的窗口统计甲基化 C 碱基的密度在染色体上的分布情况,光滑曲线则表示不同类型甲基化C 碱基( CG、CHG 和 CHH )的密度分布。 以下图为示例: 图7:染色体上甲基化 C 密度分布示例 说明:X 轴表示某染色体上碱基的位置,左Y 轴表示特定染色体碱基位置上 10kb 窗口内不同类型甲基化C 占该类型所有C 的比例(分为 CG、CHG、CHH,H 代表A 或者T),右 Y 轴表示特定染色体碱基位置上 10kb 窗口内甲基化C 的碱基密度(甲基化 C 数目占总碱基数目的比例)。为了区别CHH 与 CHG 曲线,已将 CHH 甲基化水平×50 倍放大绘出。 5、甲基化 C 位点附近的9bp序列的序列特征分析 分析CG和非CG位点的甲基化的C附近碱基的分布情况,统计不同甲基化模式出现的概率。下图为示例: 图8:CG 位点的甲基化C附近序列特征示例 说明:X 轴表示甲基化 C 碱基(CG、CHG 和 CHH)上下游4bp的位置,Y轴表示特定位置上A、T、C、G 四种碱基的权重值,权重值越高表示其比例越高。 6、分析CpG island 及其周边区域的甲基化水平分布规律 以下图为示例,反映了样本在 CpG island,CpG island shore(CpG island上下游2kb区域)和 CpG island shelf(CpG island 上下游 2000pb 至 4000bp)区域的甲基化水平分布情况。可以看出 CpG island 区域的甲基化水平整体较低,而 CpG island shore 的甲基化水平分布较均匀,更远离CpG island的CpG island shelf甲基化水平最高。 图9:CpG island 及其周边区域的甲基化水平分布 (三)不同组别样本的甲基化差异 1、CpG 甲基化相关性分析(PCC) 下图示例反映了样本之间 CpG 甲基化率的相关性,圆面积越大,颜色越深相关性越高。 图10:CpG 甲基化相关性分析(PCC) 2、CpG 甲基化主成分分析(PCA) 主成分析(PCA)是一种常用的数据降维方法,其目标是寻找一组新的变量,使它们反映原始数据的主要特征。每个新变量是原有变量的线性组合,称为“主成分”。这组新变量中,只有少数几组变量能够反映原有变量的主要特征,通过这种方式,可以使原有数据的维度降低,更易于体现各样本的特征。下图为基于样本甲基化图谱的主成分析: 图11:不同时间点样本间CpG甲基化水平的PCA分析 3、CpG 甲基化聚类分析(Clustering) 根据全基因组甲基化图谱及羟甲基化图谱,对样本进行聚类,可从总体水平反应样本组内和组间差异。聚类采用层次聚类方法(Hierachial Custering),其基本算法如下: 把每个样本归为一类,计算每两个类之间的距离,即样本与样本之间的相似度; 按一定规则选取符合距离要求的类别,并作类间合并; 重新计算新生成的类与各个旧类之间的相似度; 重复 2 和 3 直到所有样本点都归为一类。 根据样本间欧几里得距离,利用R语言hclust函数对样本做聚类,聚类方法选择ward.D2,即最小方差法,其基本思想为:每次类间合并则总离差平方和都要增加,ward.D2方法选择使离差平方和增加最小的两类进行合并。 (四)差异甲基化区域(DMR)分析 1、差异甲基化区域(DMR)检测 DMR检测使用权威期刊发表的metilene 软件,该软件利用二元分隔算法(binary segmentation algorithm)结合双重统计学检验(MWU-test和2D KS-test),可快速实现成对样本或两组样品间的DMR 重头检测(de novo)。最后,通过多重检验校正,进而得到差异甲基化区域。使用CpG 位点来寻找差异甲基化区域。 DMR 检测规则: 每个CpG 位点测序深度>=5x; CpG 位点的甲基化差异>=0.2; 该区域的差异甲基化 CpG 位点个数>=5; 相邻差异甲基化CpG 位点的距离 |

 图1:RRBS工作流程
图1:RRBS工作流程








【本文地址】
今日新闻 |
推荐新闻 |