[机器学习] 二分类模型评估指标 |
您所在的位置:网站首页 › 召回率f1是什么意思呀英文 › [机器学习] 二分类模型评估指标 |
[机器学习] 二分类模型评估指标
|
一 为什么要评估模型?
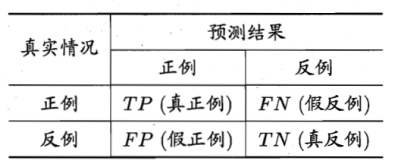
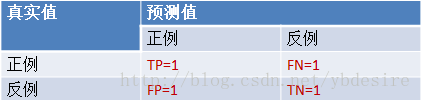
一句话,想找到最有效的模型.模型的应用是循环迭代的过程,只有通过持续调整和调优才能适应在线数据和业务目标. 选定模型时一开始都是假设数据的分布是一定的,然而数据的分布会随着时间的移动而改变,这种现象称为分布漂移(Distribution Drift)。验证指标可以对模型在不断新生的数据集上进行性能跟踪。当性能开始下降时,说明该模型已经无法拟合当前的数据了,因此需要对模型进行重新训练了。 模型能够拟合新的数据称为模型的泛化能力。 二 怎么检验和评估模型?机器学习过程分为原型设计阶段(Prototyping)与应用阶段(Deployed), 其中有原型设计阶段(Prototyping)的离线评估与应用阶段(Deployed)的在线评估(online evaluation).Prototyping阶段是使用历史数据训练一个适合解决目标任务的一个或多个机器学习模型,并对模型进行验证(Validation)与离线评估(Offline evaluation),然后通过评估指标选择一个较好的模型。我们上面的例子就是Prototyping.Deployed阶段是当模型达到设定的指标值时便将模型上线,投入生产,使用新生成的在线数据来对该模型进行在线评估(Online evaluation),在线测试不同于离线测试,有着不同的测试方法以及评价指标。最常见的便是A/B testing,它是一种统计假设检验方法。离线评估和在线评估采用不同的评估指标,在对模型进行离线评估时是采用偏经验误差的方法,在在线评估时会采用业务指标,如设备使用效率(OEE), 用户点击率等. 通过检验和评估可能选择单一模型,也能使用多个模型混合.那到底怎么选呢? 三 评估指标 (Evaluation Matrics)是什么?评估指标是把"尺子",用来评判模型优劣水平的算法,不同的机器学习模型有着不同的"尺子",同时同一种机器学习模型也可以用不同的尺子来评估,只是每个尺子的的着重点不同而已。对于分类(classification)、回归(regression)、排序(ranking)、聚类(clustering)、推荐(recommendation),很多指标可以对其进行评价,如精确率-召回率(precision-recall),可以用在分类、推荐、排序等中.以下是各类"尺子"的定义,用到时才看,仅供参考. 错误率,精度,误差的基本概念: 错误率(error rate)= a个样本分类错误/m个样本 精度(accuracy)= 1 -错误率 误差(error):学习器实际预测输出与样本的真是输出之间的差异。 训练误差(training error):即经验误差。学习器在训练集上的误差。 泛化误差(generalization error):学习器在新样本上的误差。 分类器评估指标对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为: 真正例(True Positive,TP):真实类别为正例,预测类别为正例。假正例(False Positive,FP):真实类别为负例,预测类别为正例。假负例(False Negative,FN):真实类别为正例,预测类别为负例。真负例(True Negative,TN):真实类别为负例,预测类别为负例。记忆诀窍是 :这 4 个定义由两个字母组成: 第 1 个字母表示算法预测正确或者错误,即 True、False 描述的是这个分类器是否判断正确。 第 2 个字母表示算法预测的结果,即 Positive、Negative 是这个分类器的分类结果。 P = TP + FN :所有 "实际为正例" 的样本数 N = FP + TN :所有 "实际 为负例" 的样本数 P~ = TP + FP :所有 "预测为正例" 的样本数 N~ = TN + FN :所有 "预测为负例" 的样本数 3.1 混淆矩阵 、介绍这些概念之前先来介绍一个概念:混淆矩阵(confusion matrix)。对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果。对于常见的二元分类,它的混淆矩阵是 2x2 的。
假设要对 15 个人预测是否患病,使用 1 表示患病,使用 0 表示正常。预测结果如下:
将上面的预测结果转为混淆矩阵,如下: 上图展示了一个二元分类的混淆矩阵,从该混淆矩阵可以得到以下信息: 样本数据总共有 5 + 2 + 4 + 4 = 15 个 真实值为 1 并且预测值也为 1 的样本有 5 个,真实值为 1 预测值为 0 的样本有 2 个,真实值为 0 预测值为 1 的样本有 4 个,真实值为 0 预测值也为 0 的样本有 4 个。 二元分类问题可以获得 True Positive(TP,真阳性)、False Positive(FP,假阳性)、 False Negative(FN,假阴性) 和 True Negative(TN,真阴性)。这四个值分别对应二元分类问题的混淆矩阵的四个位置。 小技巧:上面的这四个概念经常会被搞混淆(难道混淆矩阵的名称就是这么来的?),这里有个小方法帮你记住它。在医学上,一般认为阳性是患病,阴性是正常。所以只要出现“阳性”关键字就表示结果为患病,此外,阳性也分为真阳性和假阳性,从名称就可以看出:真阳性表示确确实实的阳性,也就是说实际为阳性(患病),预测也为阳性(患病);假阳性表示不真实的阳性,也就是说实际为阴性(正常),预测为阳性(患病)。真阴性和假阴性也可以按照上面的方式来简单理解。 很明显,这里的 TP=5,FP=2,FN=4,TN=4。 3.2 准确率 Accuracy
按照我们上文的定义:第 1 个字母表示算法预测正确或者错误,第 2 个字母表示算法预测的结果。 所以分母是全部四种数据;分子中第一个字母是 T 表示 "算法预测正确了"。 准确率有一个缺点,就是数据的样本不均衡,这个指标是不能评价模型的性能优劣的。 假如一个测试集有正样本999个,负样本1个。我们设计的模型是个无脑模型,即把所有的样本都预测为正样本,那么模型的Accuracy为99.9%,看评价指标,模型的效果很好,但实际上模型没有任何预测能力。 3.3 精准率 Precision
精确率(Precision): 就是预测正确的正例数据占预测为正例数据的比例。 按照我们上文的定义:第 1 个字母表示算法预测正确或者错误,第 2 个字母表示算法预测的结果。 所以分母中, TP表示 : 算法预测正确 & 预测的是正例,FP表示 : 算法预测错误 & 预测的是正例(实际是负例) 3.4 准确率 VS 精准率 让我们看看其英文原意。 Accuracy在词典中的定义是:the quality or state of being correct or precise Precision在词典中的定义是:the quality, condition, or fact of being exact and accurate Accuracy首先是correct(正确),而precision首先是exact(精确,或者说确切)。首先准确,然后才谈得上精确。一个结果必须要同时符合准确与精密这两个条件,才可算是精准。 这两个词也 有点类似 偏差(bias)与方差(variance) 偏差(bias)反映了模型在样本上的期望输出与真实标记之间的差距,即模型本身的精准度,反映的是模型本身的拟合能力。这就很像 Precision。 方差(variance)反映了模型在不同训练数据集下学得的函数的输出与期望输出之间的误差,即模型的稳定性,反应的是模型的波动情况。这有点像 Accuracy。 比如大概可以类比成射箭,准确率要看你射中靶心的概率;精准率要看你射中的是靶心区域的哪个位置。 3.5 召回率 Recall
召回率(Recall) 通俗地讲,就是预测为正例的数据占实际为正例数据的比例 按照我们上文的定义:第 1 个字母表示算法预测正确或者错误,第 2 个字母表示算法预测的结果。 所以分母中 TP+FN ,表示 “预测正确且预测为正样本“ + “预测错误且预测为负样本(实际是真实正例)“。即 所有 "实际为正例" 的样本数 分子是:预测正确 且 被预测为正样本。
召回率分类阈值较低。尽量检测数据,不遗漏数据,所谓的宁肯错杀一千,不肯放过一个。 我们看看英文解释,Recall : to remember sth; to make sb think of sth; to order sb to return; to ask for sth to be returned, often because there is sth wrong with it。 因为Recall有记忆的意思,所以可以试着把 Recall 理解为“记忆率”。就是记忆一个事件需要多少细节,这个细节就是当我们问检索系统某一件事的所有细节时(输入检索query),检索系统能“Recall 回忆”起那些事的多少细节,通俗来讲就是“回忆的能力”。能回忆起来的细节数 除以 系统知道这件事的所有细节,就是“记忆率”,也就是recall——召回率。 召回率的应用场景是:需要尽可能地把所需的类别检测出来,而不在乎结果是否准确。 比如对于地震的预测,我们希望每次地震都能被预测出来,这个时候可以牺牲precision。假如一共发生了10次地震,我们情愿发出1000次警报,这样能把这10次地震都涵盖进去(此时recall是100%,precision是1%),也不要发出100次警报,其中有8次地震给预测到了,但漏了2次(此时recall是80%,precision是8%)。 3.6 精准率 VS 召回率
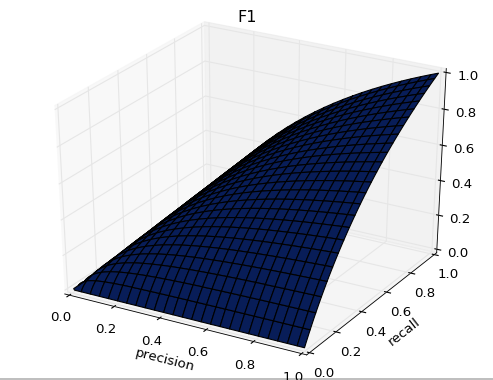
召回率是覆盖面的度量,度量有多个真实正例被预测为正例。精度是精确性的度量,表示被预测为正例的示例中实际为正例的比例。 在不同的应用场景下,我们的关注点不同,例如: 在预测股票的时候,我们更关心**精准率**,即我们预测升的那些股票里,真的升了有多少,因为那些我们预测升的股票都是我们投钱的。 而在预测病患的场景下,我们更关注**召回率**,即真的患病的那些人里我们预测错了情况应该越少越好,因为真的患病如果没有检测出来,结果其实是很严重的,之前那个无脑的算法,召回率就是 0。 在信息检索中,准确率和召回率是互相影响的,虽然两者都高是一种期望的理想情况,然而实际中常常是如果阈值较高,那么精准率会高,但是会漏掉很多数据;如果阈值较低,召回率高,但是预测的会很不准确。所以在实际中常常需要根据具体情况做出取舍,例如: 对一般搜索的情况是在保证召回率的情况下提升准确率, 而如果是疾病监测、反垃圾邮件等,则是在保证准确率的条件下,提升召回率。 有时候,需要兼顾两者,那么就可以用F1值(F score):
正如下图所示,F1的值同时受到P、R的影响,单纯地追求P、R的提升并没有太大作用。在实际业务工程中,结合正负样本比,的确是一件非常有挑战的事。 precision一定情况下反映了模型控制假阳 FP 个数的能力,Recall 值反映了正样本的检出率,F1 值综合了两方面。 其实 F1 score 是精准率和召回率的调和平均数,调和平均数的性质就是,只有当精准率和召回率二者都非常高的时候,它们的调和平均才会高。如果其中之一很低,调和平均就会被拉得接近于那个很低的数。 为什么?因为调和平均值上面是一个乘积,所以其更接近较小值,这样查准率或查全率中哪个值较小,调和平均值就更接近这个值,这样的测量指标更严格。 3.6.1 为什么准确率和召回率是互相影响 首先说大致原理 recall和precision是相互矛盾的。如果想要更高的recall,那么就要让模型的预测能覆盖到更多的样本,但是这样模型就更有可能犯错,也就是说precision会比较低。如果模型很保守,只能检测出它很确定的样本,那么其precision会很高,但是recall会相对低。 recall(TPR)的分母是样本中正类的个数,因此样本一旦确定,其分母即为定值,也就是说recall的变化随分子增加而单调递增;precision的分母是样本中预测为正类的个数,其会随着分类阈值的变化而变化,因此Precision的变化受TP和FP的综合影响,不单调,变化情况不可预测。 4. ROC与AUC 根据维基百科的描述,AUC(Area under the Curve of ROC)是ROC曲线下方的面积,是判断二分类预测模型优劣的标准。ROC(receiver operating characteristic curve)接收者操作特征曲线。 是由二战中的电子工程师和雷达工程师发明用来侦测战场上敌军载具(飞机、船舰)的指标,属于信号检测理论。ROC曲线的横坐标是伪阳性率(也叫假正类率,False Positive Rate),纵坐标是真阳性率(真正类率,True Positive Rate),相应的还有真阴性率(真负类率,True Negative Rate)和伪阴性率(假负类率,False Negative Rate), AUC用于衡量“二分类问题”机器学习算法性能(泛化能力)。 我们知道,我们常用ACC准确率来判断分类器分类结果的好坏,既然有了ACC为什么还需要ROC呢,很重要的一个因素是实际的样本数据集中经常会出现数据偏斜的情况,要么负类样本数大于正类样本数,要么正类样本数大于负类样本数。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而相对于AUC是个数值而言,对应AUC更大的分类器效果更好,数值更好判断一些。 4.1. 概念解释 True Positive, False Positive, True Negative, False Negative 它们是根据真实类别与预测类别的组合来区分的. 假设有一批test样本,这些样本只有两种类别:正例和反例。机器学习算法预测类别(左半部分预测类别为正例,右半部分预测类别为反例),而样本中真实的正例类别在上半部分,下半部分为真实的反例。样本中的真实正例类别总数即TP+FN。True Positive Rate,TPR = TP/(TP+FN)。 同理,样本中的真实反例类别总数为FP+TN。False Positive Rate,FPR=FP/(TN+FP)。
预测 合计 1 0 实际
1 (P) True Positive(TP) False Negative(FN) Actual Positive(TP+FN) 0 (N) False Positive(FP) True Negative(TN) Actual Negative(FP+TN) 合计 Predicted Positive(TP+FP) Predicted Negative(FN+TN) TP+FP+FN+TN 截断点 机器学习算法对test样本进行预测后,可以输出各test样本对某个类别的相似度概率。 比如t1是P类别的概率为0.3,一般我们认为概率低于0.5,t1就属于类别N。这里的0.5,就是”截断点”。 总结一下,对于计算ROC,最重要的三个概念就是TPR, FPR, 截断点。 截断点取不同的值,TPR和FPR的计算结果也不同。将截断点不同取值下对应的TPR和FPR结果画于二维坐标系中得到的曲线 x轴与y轴的值域都是[0, 1],我们可以得到一组(x, y)的点,相连便作出了ROC曲线,示例图如下: 纵坐标是true positive rate(TPR) = TP / (TP+FN=P) (分母是横行的合计)直观解释:实际是1中,猜对多少横坐标是false positive rate(FPR) = FP / (FP+TN=N) 直观解释:实际是0中,错猜多少
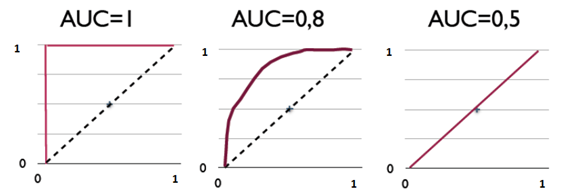
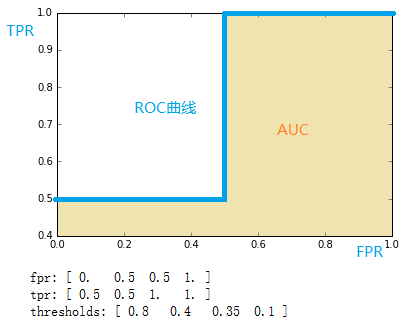
图中的虚线相当于随机预测的结果。不难看出,随着FPR的上升,ROC曲线从原点(0, 0)出发,最终都会落到(1, 1)点。ROC便是其右下方的曲线面积。下图展现了三种AUC的值: AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。 AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。 AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在AUC < 0.5的情况 AUC对于每一个做机器学习的人来说一定不陌生,它是衡量二分类模型优劣的一种评价指标,表示正例排在负例前面的概率。其他评价指标有精确度、准确率、召回率,而AUC比这三者更为常用。因为一般在分类模型中,预测结果都是以概率的形式表现,如果要计算准确率,通常都会手动设置一个阈值来将对应的概率转化成类别,这个阈值也就很大程度上影响了模型准确率的计算。 我们不妨举一个极端的例子:一个二类分类问题一共10个样本,其中9个样本为正例,1个样本为负例,在全部判正的情况下准确率将高达90%,而这并不是我们希望的结果,尤其是在这个负例样本得分还是最高的情况下,模型的性能本应极差,从准确率上看却适得其反。而AUC能很好描述模型整体性能的高低。这种情况下,模型的AUC值将等于0(当然,通过取反可以解决小于50%的情况,不过这是另一回事了) ROC 计算例子 from sklearn import metrics import numpy as np y = np.array([1, 1, 2, 2]) scores = np.array([0.1, 0.4, 0.35, 0.8]) fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2) print fpr print tpr print thresholds通过计算,得到的结果(FPR,TPR, 截断点)为 [ 0. 0.5 0.5 1. ] [ 0.5 0.5 1. 1. ] [ 0.8 0.4 0.35 0.1 ]
将结果中的FPR与TPR画到二维坐标中,得到的ROC曲线如下(蓝色线条表示),ROC曲线的面积用AUC表示(淡黄色阴影部分)。 详细计算过程 上例给出的数据如下: y = np.array([1, 1, 2, 2]) scores = np.array([0.1, 0.4, 0.35, 0.8])用这个数据,计算TPR,FPR的过程是怎么样的呢? 1. 分析数据y是一个一维数组(样本的真实分类)。数组值表示类别(一共有两类,1和2)。我们假设y中的1表示反例,2表示正例。即将y重写为: y_true = [0, 0, 1, 1]
score即各个样本属于正例的概率。 2. 针对score,将数据排序 样本预测属于P的概率(score)真实类别y[0]0.1Ny[2]0.35Py[1]0.4Ny[3]0.8P 3. 将截断点依次取为score值 将截断点依次取值为0.1,0.35,0.4,0.8时,计算TPR和FPR的结果。 3.1 截断点为0.1 说明只要score>=0.1,它的预测类别就是正例。 此时,因为4个样本的score都大于等于0.1,所以,所有样本的预测类别都为P。 scores = [0.1, 0.4, 0.35, 0.8] y_true = [0, 0, 1, 1] y_pred = [1, 1, 1, 1]TPR = TP/(TP+FN) = 1 FPR = FP/(TN+FP) = 1 3.2 截断点为0.35 说明只要score>=0.35,它的预测类别就是P。 此时,因为4个样本的score有3个大于等于0.35。所以,所有样本的预测类有3个为P(2个预测正确,1一个预测错误);1个样本被预测为N(预测正确)。 scores = [0.1, 0.4, 0.35, 0.8] y_true = [0, 0, 1, 1] y_pred = [0, 1, 1, 1]
TPR = TP/(TP+FN) = 1 FPR = FP/(TN+FP) = 0.5 3.3 截断点为0.4 说明只要score>=0.4,它的预测类别就是P。 此时,因为4个样本的score有2个大于等于0.4。所以,所有样本的预测类有2个为P(1个预测正确,1一个预测错误);2个样本被预测为N(1个预测正确,1一个预测错误)。 scores = [0.1, 0.4, 0.35, 0.8] y_true = [0, 0, 1, 1] y_pred = [0, 1, 0, 1]TPR = TP/(TP+FN) = 0.5 FPR = FP/(TN+FP) = 0.5 3.4 截断点为0.8 说明只要score>=0.8,它的预测类别就是P。所以,所有样本的预测类有1个为P(1个预测正确);3个样本被预测为N(2个预测正确,1一个预测错误)。 scores = [0.1, 0.4, 0.35, 0.8] y_true = [0, 0, 1, 1] y_pred = [0, 0, 0, 1]
TPR = TP/(TP+FN) = 0.5 FPR = FP/(TN+FP) = 0 用下面描述表示TPR和FPR的计算过程,更容易记住 TPR:真实的正例中,被预测正确的比例FPR:真实的反例中,被预测正确的比例最理想的分类器,就是对样本分类完全正确,即FP=0,FN=0。所以理想分类器FPR=0,TPR=1。
第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。Wow,这是一个完美的分类器,它将所有的样本都正确分类。 第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。 第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。 第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
|



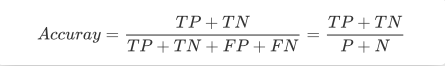
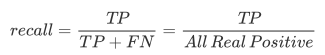








【本文地址】
今日新闻 |
推荐新闻 |