如何计算深度学习模型的精度、召回率、F1等指标 |
您所在的位置:网站首页 › 召回率为1怎么解决 › 如何计算深度学习模型的精度、召回率、F1等指标 |
如何计算深度学习模型的精度、召回率、F1等指标
|
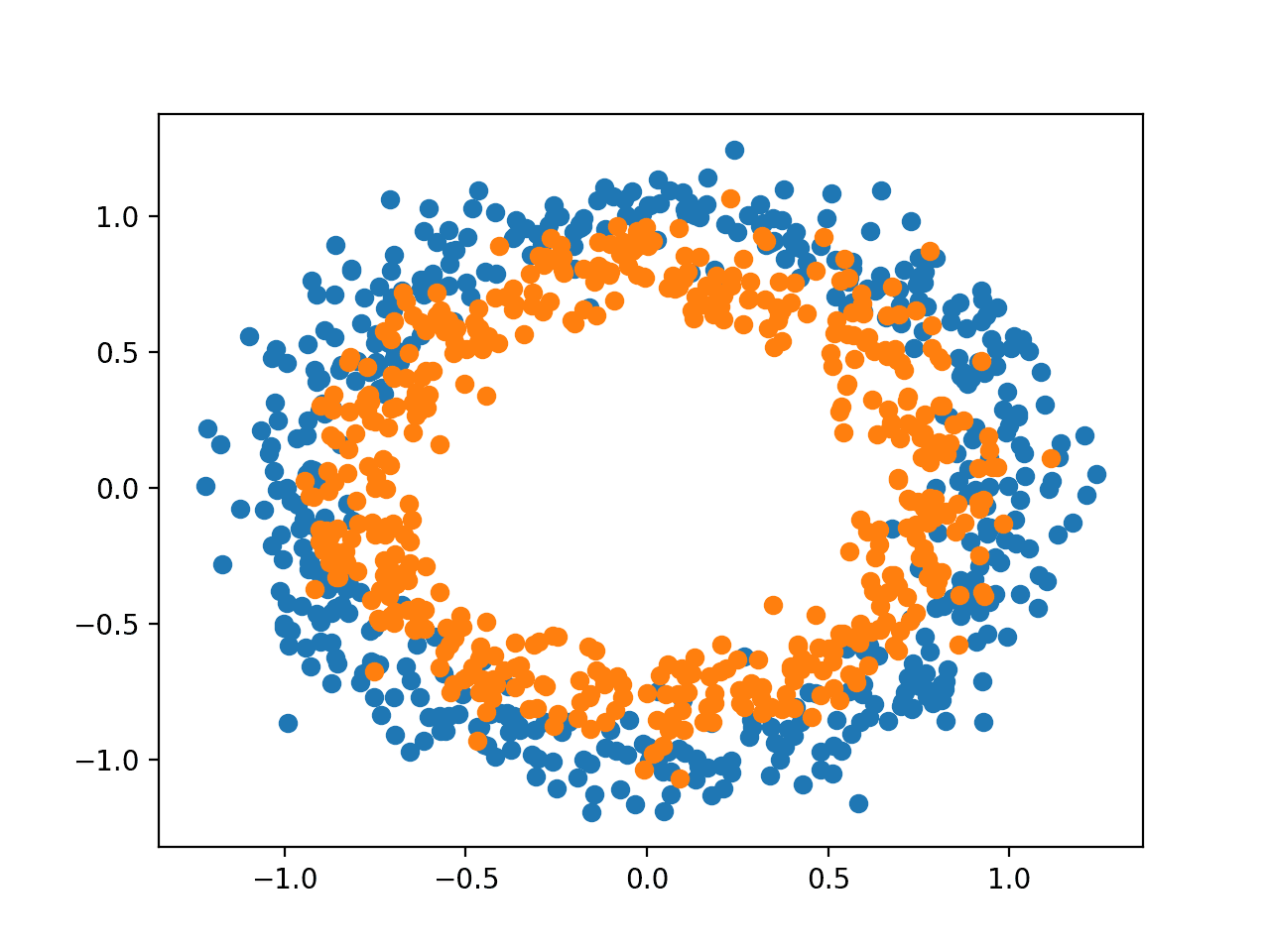
一旦你适合一个深度学习神经网络模型,你必须在测试数据集上评估其性能。 这一点很关键,因为报告的性能既可以让你在候选模型之间进行选择,又可以向利益相关者传达模型在解决问题方面的能力。 Keras深度学习API模型在你可以用来报告模型性能的指标方面非常有限。 我经常被问到一些问题,比如。 我如何计算我的模型的精度和召回率? 还有。 如何计算我的模型的F1分数或混淆矩阵? 在本教程中,你将发现如何计算指标来评估你的深度学习神经网络模型,并有一个逐步的例子。 完成本教程后,你将知道。 如何使用scikit-learn度量API来评估一个深度学习模型。 如何用scikit-learn API要求的最终模型进行类别和概率的预测。 如何用scikit-learn API为一个模型计算精度、召回率、F1分数、ROC AUC等。 教程概述本教程分为三个部分,它们是: 二元分类问题 多层感知器模型 如何计算模型指标 二元分类问题我们将使用一个标准的二元分类问题作为本教程的基础,称为 "两个圆圈"问题。 它之所以被称为 "两圈 "问题,是因为该问题是由一些点组成的,这些点在绘制时显示出两个同心圆,每个类别一个。因此,这是一个二元分类问题的例子。这个问题有两个输入,可以解释为图形上的x和y坐标。每个点都属于内圈或外圈。 scikit-learn库中的make_circles()函数允许你从两个圆圈问题中生成样本。参数 "n_samples"允许你指定要生成的样本数量,平均分配给两个类。noise"参数允许你指定在每个点的输入或坐标中加入多少随机统计噪声,使分类任务更具挑战性。random_state"参数指定了伪随机数生成器的种子,确保每次运行代码时生成相同的样本。 下面的例子产生了1000个样本,统计噪声为0.1,种子为1。 # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1)一旦生成,我们可以创建一个数据集的图,以了解分类任务的挑战性。 下面的例子生成了样本并绘制了它们,根据类别给每个点着色,其中属于0类的点(外圈)被染成蓝色,属于1类的点(内圈)被染成橙色。 # Example of generating samples from the two circle problem from sklearn.datasets import make_circles from matplotlib import pyplot from numpy import where # generate 2d classification dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # scatter plot, dots colored by class value for i in range(2): samples_ix = where(y == i) pyplot.scatter(X[samples_ix, 0], X[samples_ix, 1]) pyplot.show()运行这个例子可以生成数据集,并将点绘制在图表上,清楚地显示出属于0类和1类的点的两个同心圆。
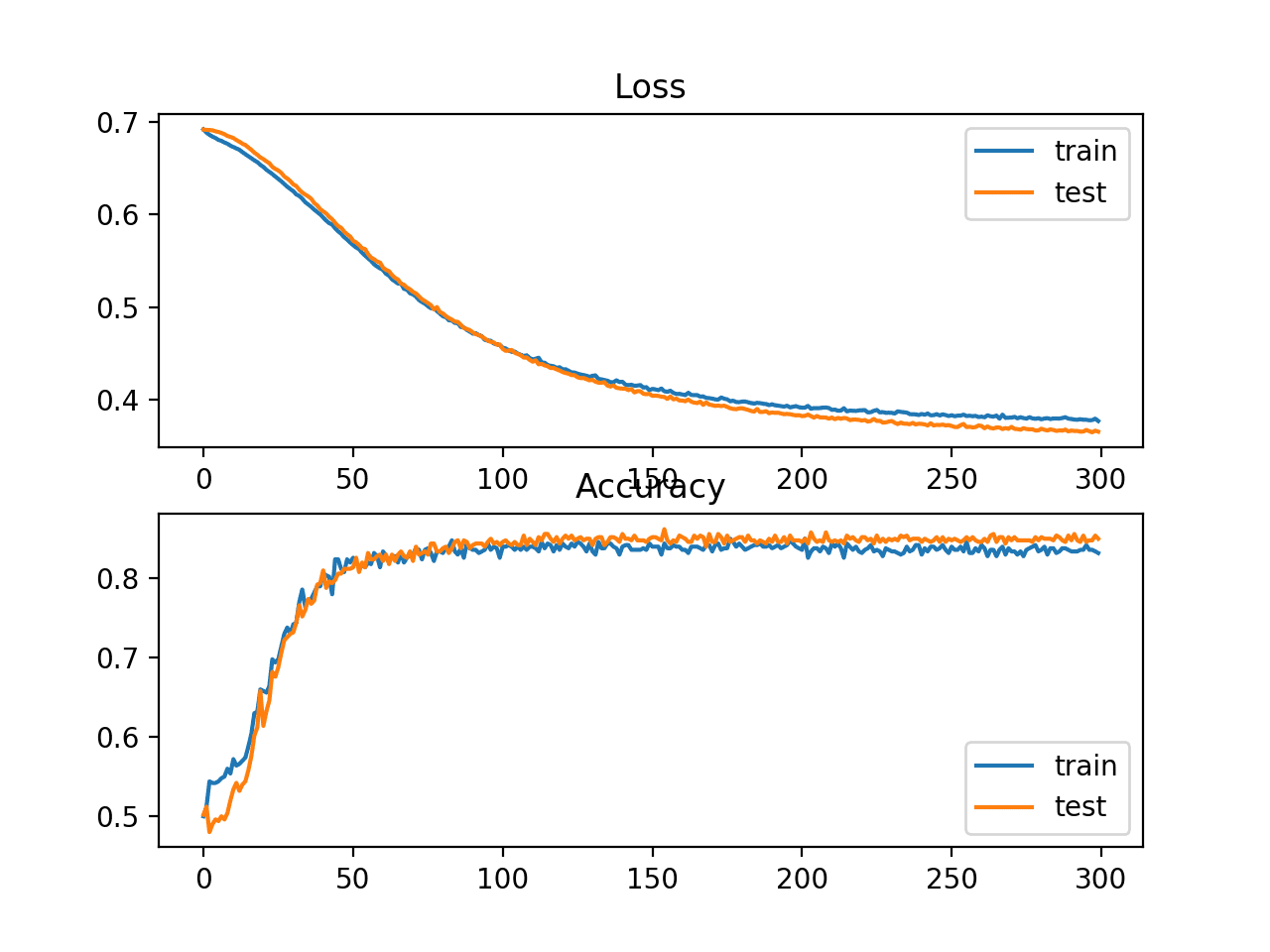
两个圆圈问题的样本散点图 多层感知器模型我们将开发一个多层感知器(MLP)模型来解决二元分类问题。 这个模型没有针对这个问题进行优化,但它是有技巧的(比随机的好)。 在数据集的样本生成后,我们将把它们分成两个相等的部分:一个用于训练模型,一个用于评估训练后的模型。 # split into train and test n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:]接下来,我们可以定义我们的MLP模型。该模型很简单,期望从数据集中获得2个输入变量,一个有100个节点的单一隐藏层和一个ReLU激活函数,然后是一个有一个节点和一个sigmoid激活函数的输出层。 该模型将预测一个介于0和1之间的值,该值将被解释为输入的例子是属于0类还是1类。 # define model model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid'))该模型将使用二元交叉熵损失函数进行拟合,我们将使用高效的亚当版本的随机梯度下降法。该模型还将监测分类准确度指标。 # compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])我们将用默认的32个样本的批量大小来拟合模型300个训练历时,并在每个训练历时结束时在测试数据集上评估模型的性能。 # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0)在训练结束时,我们将在训练和测试数据集上再次评估最终模型,并报告分类精度。 # evaluate the model _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0)最后,在训练过程中记录的模型在训练和测试集上的表现将用线图来表示,损失和分类准确率各占一个。 # plot loss during training pyplot.subplot(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # plot accuracy during training pyplot.subplot(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show()将所有这些元素联系在一起,下面列出了训练和评估两个圆圈问题的MLP的完整代码清单。 # multilayer perceptron model for the two circles problem from sklearn.datasets import make_circles from keras.models import Sequential from keras.layers import Dense from matplotlib import pyplot # generate dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # split into train and test n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] # define model model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # fit model history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=300, verbose=0) # evaluate the model _, train_acc = model.evaluate(trainX, trainy, verbose=0) _, test_acc = model.evaluate(testX, testy, verbose=0) print('Train: %.3f, Test: %.3f' % (train_acc, test_acc)) # plot loss during training pyplot.subplot(211) pyplot.title('Loss') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() # plot accuracy during training pyplot.subplot(212) pyplot.title('Accuracy') pyplot.plot(history.history['accuracy'], label='train') pyplot.plot(history.history['val_accuracy'], label='test') pyplot.legend() pyplot.show()在CPU上运行这个例子可以很快适应这个模型(不需要GPU)。 注意:鉴于算法或评估程序的随机性,或数字精度的差异,你的结果可能会有所不同。考虑多运行几次该例子,并比较平均结果。 对模型进行评估,报告在训练集和测试集上的分类精度分别为83%和85%左右。 Train: 0.838, Test: 0.850一个图显示了两张线图:一张是训练集和测试集的损失学习曲线,一张是训练集和测试集的分类。 这些图表明,该模型对问题有很好的拟合。
线图显示训练期间MLP在两个圆问题上的损失和准确率的学习曲线。 如何计算模型指标也许你需要使用Keras度量API不支持的额外度量来评估你的深度学习神经网络模型。 Keras的指标API是有限的,你可能想计算精度、召回率、F1等指标。 计算新指标的一种方法是自己在Keras API中实现它们,并让Keras在模型训练和模型评估期间为你计算它们。 关于这种方法的帮助,请看教程。 如何在Python中使用Keras的深度学习指标这在技术上是有难度的。 一个更简单的选择是使用你的最终模型对测试数据集进行预测,然后使用scikit-learn度量API计算你想要的任何度量。 除了分类准确率之外,二元分类问题上的神经网络模型通常需要的三个指标是。 精度 召回率 F1得分在本节中,我们将计算这三个指标,以及使用scikit-learn指标API计算分类精度,我们还将计算三个不太常见但可能有用的额外指标。它们是 Cohen's Kappa ROC AUC 混淆矩阵。这并不是scikit-learn支持的分类模型指标的完整列表;尽管如此,计算这些指标将告诉你如何使用scikit-learn API计算你可能需要的任何指标。 本节的例子将计算MLP模型的指标,但计算指标的相同代码也可以用于其他模型,如RNN和CNN。 我们可以使用前几节中的相同代码来准备数据集,以及定义和拟合模型。为了使这个例子更简单,我们将把这些步骤的代码放到简单的函数中。 首先,我们可以定义一个名为get_data()的函数,它将生成数据集并将其分成训练集和测试集。 # generate and prepare the dataset def get_data(): # generate dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # split into train and test n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] return trainX, trainy, testX, testy接下来,我们将定义一个名为get_model()的函数,该函数将定义MLP模型并在训练数据集上拟合。 # define and fit the model def get_model(trainX, trainy): # define model model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # fit model model.fit(trainX, trainy, epochs=300, verbose=0) return model然后我们可以调用get_data()函数来准备数据集,调用get_model()函数来拟合并返回模型。 # generate data trainX, trainy, testX, testy = get_data() # fit model model = get_model(trainX, trainy)现在我们有了一个在训练数据集上拟合的模型,我们可以使用scikit-learn度量API的度量来评估它。 首先,我们必须使用该模型来进行预测。大多数的度量函数都需要比较真实的类值(如testy)和预测的类值(yhat_classes)。我们可以使用模型上的predict_classes()函数,直接用我们的模型来预测类值。 一些指标,如ROC AUC,需要预测类的概率(yhat_probs)。这些可以通过调用模型上的predict()函数来获取。 我们可以用该模型进行类别和概率预测。 # predict probabilities for test set yhat_probs = model.predict(testX, verbose=0) # predict crisp classes for test set yhat_classes = model.predict_classes(testX, verbose=0)预测结果将以二维数组形式返回,测试数据集中的每个例子有一行,预测结果有一列。 scikit-learn的度量API希望有一个实际值和预测值的一维数组进行比较,因此,我们必须将二维预测数组还原为一维数组。 # reduce to 1d array yhat_probs = yhat_probs[:, 0] yhat_classes = yhat_classes[:, 0]我们现在已经准备好为我们的深度学习神经网络模型计算指标了。我们可以开始计算分类准确率、精确度、召回率和F1分数。 # accuracy: (tp + tn) / (p + n) accuracy = accuracy_score(testy, yhat_classes) print('Accuracy: %f' % accuracy) # precision tp / (tp + fp) precision = precision_score(testy, yhat_classes) print('Precision: %f' % precision) # recall: tp / (tp + fn) recall = recall_score(testy, yhat_classes) print('Recall: %f' % recall) # f1: 2 tp / (2 tp + fp + fn) f1 = f1_score(testy, yhat_classes) print('F1 score: %f' % f1)注意,计算一个指标就像选择我们感兴趣的指标一样简单,然后调用函数,传入真实的类值(testy)和预测的类值(yhat_classes)。 我们还可以计算一些额外的度量,如Cohen's kappa、ROC AUC和混淆矩阵。 请注意,ROC AUC需要预测的类别概率(yhat_probs)作为参数,而不是预测的类别(yhat_classes)。 # kappa kappa = cohen_kappa_score(testy, yhat_classes) print('Cohens kappa: %f' % kappa) # ROC AUC auc = roc_auc_score(testy, yhat_probs) print('ROC AUC: %f' % auc) # confusion matrix matrix = confusion_matrix(testy, yhat_classes) print(matrix)现在我们知道了如何使用scikit-learn API来计算深度学习神经网络的指标,我们可以将所有这些元素结合起来,形成一个完整的例子,列在下面。 # demonstration of calculating metrics for a neural network model using sklearn from sklearn.datasets import make_circles from sklearn.metrics import accuracy_score from sklearn.metrics import precision_score from sklearn.metrics import recall_score from sklearn.metrics import f1_score from sklearn.metrics import cohen_kappa_score from sklearn.metrics import roc_auc_score from sklearn.metrics import confusion_matrix from keras.models import Sequential from keras.layers import Dense # generate and prepare the dataset def get_data(): # generate dataset X, y = make_circles(n_samples=1000, noise=0.1, random_state=1) # split into train and test n_test = 500 trainX, testX = X[:n_test, :], X[n_test:, :] trainy, testy = y[:n_test], y[n_test:] return trainX, trainy, testX, testy # define and fit the model def get_model(trainX, trainy): # define model model = Sequential() model.add(Dense(100, input_shape=(2,), activation='relu')) model.add(Dense(1, activation='sigmoid')) # compile model model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # fit model model.fit(trainX, trainy, epochs=300, verbose=0) return model # generate data trainX, trainy, testX, testy = get_data() # fit model model = get_model(trainX, trainy) # predict probabilities for test set yhat_probs = model.predict(testX, verbose=0) # predict crisp classes for test set yhat_classes = model.predict_classes(testX, verbose=0) # reduce to 1d array yhat_probs = yhat_probs[:, 0] yhat_classes = yhat_classes[:, 0] # accuracy: (tp + tn) / (p + n) accuracy = accuracy_score(testy, yhat_classes) print('Accuracy: %f' % accuracy) # precision tp / (tp + fp) precision = precision_score(testy, yhat_classes) print('Precision: %f' % precision) # recall: tp / (tp + fn) recall = recall_score(testy, yhat_classes) print('Recall: %f' % recall) # f1: 2 tp / (2 tp + fp + fn) f1 = f1_score(testy, yhat_classes) print('F1 score: %f' % f1) # kappa kappa = cohen_kappa_score(testy, yhat_classes) print('Cohens kappa: %f' % kappa) # ROC AUC auc = roc_auc_score(testy, yhat_probs) print('ROC AUC: %f' % auc) # confusion matrix matrix = confusion_matrix(testy, yhat_classes) print(matrix)注意:鉴于算法或评估程序的随机性,或者数字精度的差异,你的结果可能会有所不同。考虑运行该例子几次并比较平均结果。 运行该例子准备数据集,拟合模型,然后计算和报告在测试数据集上评估的模型的指标。 Accuracy: 0.842000 Precision: 0.836576 Recall: 0.853175 F1 score: 0.844794 Cohens kappa: 0.683929 ROC AUC: 0.923739 [[206 42] [ 37 215]]如果你在解释某个指标时需要帮助,也许可以从scikit-learn API文档中的 "分类指标指南 "开始。 总结在本教程中,你发现了如何通过一个逐步的例子来计算评估你的深度学习神经网络模型的指标。 具体来说,你学到了。 如何使用scikit-learn指标API来评估一个深度学习模型。 如何用scikit-learn API要求的最终模型进行类别和概率的预测。 如何用scikit-learn API为一个模型计算精度、召回率、F1-score、ROC、AUC等等。 |
【本文地址】