stata上课笔记|生成新变量 |
您所在的位置:网站首页 › 变量怎么说 › stata上课笔记|生成新变量 |
stata上课笔记|生成新变量
|
Stata课上老师说,总的来说,整个数据处理过程大致分为两部分,第一部分指的一般是生成我们所需要的变量,把原始从数据库上下载的数据转化为后面能够进行回归的一系列处理过程,第二部分就是正式回归分析。这篇文章就是主要对第一部分处理的汇总,第二部分可能需要等下学期上课再更新了。 注意事项:如果下面的代码复制粘贴有问题,建议自己重新手打一遍试试 目录 看help怎么看!!! 了解stata内部语言特征 看help下面的例子 生成新变量 新变量的命名 常见变量的生成 批量生成ln处理变量 生成滞后项或者是提前项 判别式变量,即虚拟变量regexm() 排列式数据rank() 异常原始数据的处理 字符串的异常 strtrim() regexr() ustrregexra() subinstr() Split strmatch() 时间变量 mdy() date() 循环语句 Foreach、Forvalue循环 Foreach 合并文件 数据结构的转换 Reshape 字符型和数值型数据的相互转换 Destring Tostring Real() 数据的描述 Inspect Summarize Tab Tabstat 看help怎么看!!! 了解stata内部语言特征黑体是固定项 斜体是可变项 []指的是可不要的 看help下面的例子有些help下面会有例子,那么对照着前面的功能介绍和下面的具体应用就可以很好地套用了 生成新变量 新变量的命名 生成新变量中需要注意缺失值的存在变量的命名,可以由任意字母或者数字或_组成,但是第一个字符只能是字母变量的命名,需要根据后续的编程来设置,需要更加系统性、标识性,例如批量处理成为ln的话,就可以命名为ln_x这样的,方便后续调用的缩写 缩写变量名 只要能够唯一识别,就可以简写,例如包含op的变量就只有opinion,那么可以直接用sum op代替sum opinion,当不满足唯一性的时候就会出现ambiguous abbreviation的报错列出任意满足名字特征的变量,加上sum t*,那么所有t开头的变量就都会被描述性统计了 常见变量的生成 批量生成ln处理变量原先存在极大的极端值,导致整个数据具有很不平衡的分布。 取对数以后标准差明显下降,中位数与平均值的差异也变小了,整个数据更加呈现一个正态分布。极端值对后续数据进行统计分析的扭曲和影响变小 foreach i in audfee ta{ gen ln_`i'=ln(`i'/10000) } 生成滞后项或者是提前项但是必须先设置面板数据,即告诉stata哪个是年份和滞后谁的变量 tsset code year然后可以用l或者f分别表示滞后和提前,后面加个数字就表示滞后几期 capture drop audfee_change gen laudfee=l.audfee gen faudfee=f.audfee gen l2audfee=l2.audfee gen f2audfee=f2.audfee不过大部分是构造差分变量,即与上一期的差额 可以采用下面的 gen audfee_change =audfee-l.audfee也可以直接用stata自带的计算差分公式,这里用d2指的是两次差分的差 gen audfee_change =d.audfee 判别式变量,即虚拟变量regexm()不仅仅是match 用regexm更容易对长字符串变量进行判别,而不需要采用排除法将整个字符串进行复制粘贴,即对比采用gen mod=(opinion!="标准无保留意见")的方式 gen mod=regexm(opinion,"标准无保留意见")但是还需要考虑缺失值的问题,即 gen mod = !regexm(opinion,"标准") if opinion!=""当有多个判别式时 gen BigFour=regexm(audfirm,"安永")|regexm(audfirm,"毕马威")|regexm(audfirm,"普华")|regexm(audfirm,"德勤") if audfirm !=""这时,可以简化步骤,将条件判断的|,即或者符号直接放入判别的字符串中 gen BigFour=regexm(audfirm,"安永|毕马威|普华|德勤") if audfirm !=""这里注意如果判别字符串中本身就含有的|&等符号,那么就可以在这些符号前加入\告诉stata后面这个符号不是系统符号 gen BigFour=regexm(audfirm,"安永\|毕马威|普华|德勤") if audfirm !=""上式判别的就是含有“安永|毕马威”或者“普华”或者“德勤”的审计公司了 排列式数据一般有两种方法,一种是采用egen中的rank,还一种是采用sort的方法,不过还需要采用_n和bysort的方法 rank() h egen其中有很多的函数用法,例如后续用到rowmiss也是来源于此,其中有rank() rank(exp) [, field|track|unique]其中,field表示最大的数值排在第一个,track表示最小的数值的排在第一个,即_n=1,unique表示没有并列第几,stata对于排名相同的两个观测随机进行进一步的排列。一般来说rank也会搭配bysort进行使用,例如对全行业的企业进行排名,或者看各年市场份额 bys year:egen rank=rank(sahre1),fieldsort sort主要的问题在于其不能倒序排列,sort按照从小到大排序,但是一般来说我们都是需要前几名的样本,这时可以采用 gsort 下面两个例子体现了两种sort的不同用法,同时也可以用于和上述的rank()进行一个类比 sort year share1 bys year:gen rank=N_n+1 gsort year -share1 bys year:gen rank=_n将某一变量按照数值分类 最简单的哑变量生成 gen BigShare=(Share1>=20)考虑缺失值时 gen BigShare=(Share1>=20) if Share1!=.注意不能使用 gen BigShare=(Share1>=20 & Share1!=.)按照多个数值界限分类recode 当然也可以用最笨的方法,一个个replace和if 可以采用recode recode varlist (rule) [(rule) ...] [, generate(newvar)] recode year (1/2005= 1) (2006/2007= 2) (2008/. = 3), gen(period)当设置的时候临界值相同,会先满足前一个的条件,即当var==x1的时候,是属于1的 recode var (1/x1= 1) (x1/x2= 2) (x2/. = 3), gen(newvar)按照分位数分类xtile xtile g1= roa,nq(10)注意nq(2)的分类边界是中位数不是平均数 在此引入return的用法 **#sum之后系统能够自动储存,help r() sum ln_ta return list
在sum之后加上d就能得到更多的数据特征 sum ln_ta ,d return list
在此基础上 **#当需要最终一个变量,并且生成的过程中需要不断生成新的变量进行替换的时候,可以直接重新生成新的变量 cap drop gta gen gta=. forvalue i=2002/2012{ xtile temp=ta if year==`i' ,nq(10) replace gta=temp if temp!=. drop temp }用temp暂元储存,之后删除就好 进一步的生成分年度分行业的,可以先把行业字符串变量变成数值型变量。即group 可以对类别变量直接分类 egen IND=group(ind) forvalue i=2002/2012{ forvalue j =1/22{ xtile temp=ta if year==`i' & IND ==`j',nq(2) replace gta=temp if temp!=. drop temp } } 异常原始数据的处理 字符串的异常拿到原始数据,很有可能字符串会是非标准化式的,那么这个时候就需要对非标准化的字符串进行处理 strtrim()其中strtrim()去除前后所有的空格,stritrim()去除中间的空格,strlrim()去除开头所有的空格,strrtrim()去除结尾所有的空格 replace audfirm =strtrim(audfirm) regexr()regexr(s1,re,s2)实际上是regexm的衍生既有对字符串包含关系的01判别,还可以进行replace,先判别re是否在该变量的字符串中,再将re替换为s2 replace audfirm =regexr(audfirm,"上海上海","上海")re中用.*表示所有的字符串 replace audfirm1 =regexr(audfirm1,"\(*\)","") tab audfirm1 replace audfirm1 =regexr(audfirm1,"\(.*\)","") tab audfirm1 ustrregexra()但是当字符串中间存在空格时,采用stritrim()中间会保留一个空格(英文写作的习惯)或者regexr()只能去掉第一个 replace audfirm =stritrim(audfirm) replace audfirm =regexr(audfirm," ","")ustrregexra可以替代所有 replace audfirm =ustrregexra(audfirm," ","") subinstr()subinstr(s1,s2,s3,n)则是可以包括所有的功能,n可以自己选择替换多少个,而不知道替换多少,想全部替换的时候就用. replace audfirm =subinstr(audfirm," ","",.)当然,除了去除空格, ustrregexra()和subinstr()也可以行使其原本的功能,即替代 但注意或者符号在ustrregexra()可以直接用,subinstr可能需要写相同代码多次,但是其可以修改次数是它的优点 replace audfirm1 =ustrregexra(audfirm1,"有限责任|合伙","") replace audfirm1 =subinstr(audfirm1,"有限责任","",.) replace audfirm1 =subinstr(audfirm1,"合伙","",.)除此之外二者还有一定区别 regex()系列的命令是需要用\识别 但是subinstr不需要\识别系统符号 tab audfirm1 if regexm(audfirm1,"\(") Splitsplit能够将一段名称按照某段字符拆分为多个部分 ,下面的代码就是把会计事务所的名称按照“会计”前和“会计”后分成两部分,并且生成新的变量audfirm1和audfirm2,audfirm1就变成了会计师事务所的前面的名称,不用再费心去处理是会计事务所还是会计师事务所等后缀 split audfirm, parse("会计") drop audfirm2 strmatch()strmath和regexm类似,但是strmath是一种pattern的识别,即它不是看变量中是否包含某个字符,而是是否符合某一类特征,需要通配符的存在 tab audfirm1 if strmatch(audfirm1,"*(*") tab audfirm1 if regexm(audfirm1,"(") 时间变量stata中的时间变量以1960.1.1为开头计算过了多少天,是一个数值 mdy()mdy()将数值型转化为stata中特定的时间变量,表示的是stata中生成的时间变量 如下生成当前年份到上市期间的年份 gen Listage=(mdy(12,31,year)-listing_date)/365 date()date()将字符串转化为stata中特定的时间变量 gen Accper="Dec31"+string(year) gen Listage=(date(Accper,"MDY")-listing_date)/365如果当原始数据中的日期变量未说明年份的前两个数字,则需要在第三个option进行说明 gen Listage=(date(Accper,"MDY",2050)-listing_date)/365date()和mdy() 的区别主要是语法不一样,其他的基本一致 循环语句 Foreach、Forvalue循环 Foreach
in 和 of在本质上没有特别大的区别,只是如果当do文档中本来就存在global 或local储存的一个列表时,采用 of 就是最快速的方法。除此之外,下面的两个例子中,第一个试运行不出来的,因为in没法识别列表,但是of可以识别出后面的指令是属于已有变量中的列表名,当然如果第一个把recv到fixasst之间的变量一个一个列出来是可以运行的 cap drop ln* foreach var in ta recv-fixasst { gen ln_`var' = ln(`var'/10000) } cap drop ln* foreach var of varlist ta recv-fixasst { gen ln_`var' = ln(`var'/10000) }还一种情况就是 foreach后加上in和数字,这种情况一般就使用forvalues,看下面三种情况 第一种情况和第三种是一样的,但是第二种会直接display0.005出来,可以看出foreach后面加数字的话用in是不太方便的,这和上面一样,foreach in对后续变量的识别并不精准,并且不能够识别stata中常用的简化列示变量的方法,必须将变量一个个列示出来 foreach x of numlist 1/200{ display `x' } foreach x in 1/200{ display `x' } forvalues x =1/200{ display `x' }进一步考虑第一种和第三种是否存在差别,经过试验,forvalues的语句基本都能用在 foreach x of numlist后面 foreach x of numlist 1(2)50{ display `x' } forvalues x =1(2)50{ display `x' }进一步地,以forvalues为例,探讨一下数字的表达方式,下面三种表达方式是相同的,⚠️#d和#t的区别
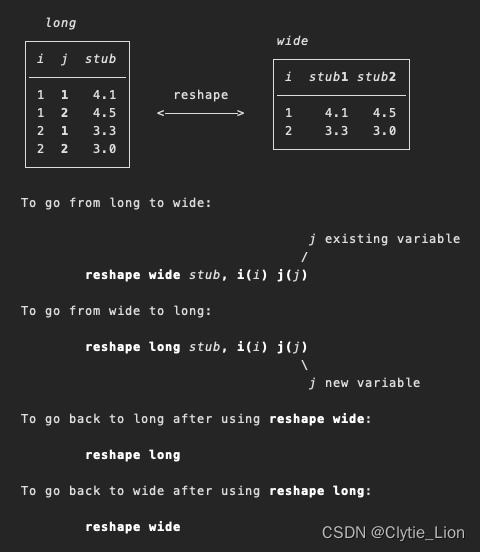
除了批量处理变量之外,循环还有一个重要作用就是合并文件上 例如原始数据表有三个,一个一个合并的话,需要重新一共生成五个表 import exc $dir1/csmar/FS_Comins.xls,first clear save FS_Comins,replace import exc $dir1/csmar/FS_Comins1.xls,first clear save FS_Comins1,replace import exc $dir1/csmar/FS_Comins2.xls,first clear save FS_Comins2,replace import exc $dir1/csmar/FS_Comins3.xls,first clear save FS_Comins3,replace use FS_Comins,clear append using FS_Comins1 append using FS_Comins2 append using FS_Comins3 save allFS_Comins,replace当使用forvalues就可以 import exc $dir1/csmar/FS_Comins.xls,first clear save FS_Comins,replace forv i = 1/3{ import exc $dir1/csmar/FS_Comins`i'.xls,first clear save FS_Comins`i',replace use FS_Comins,clear append using FS_Comins`i' save FS_Comins,replace } save allFS_Comins,replace进一步的,采用temp以及preserve暂存新生成的那些文件(在将原始数据转成dta文件的过程中尽量都采用main 和temp两种文件名,这样不会生成冗余的文件也会比较清晰地弄清楚主文件数据是哪些) import exc $dir1/csmar/FS_Comins.xls,first clear forv i = 1/3{ preserve import exc $dir1/csmar/FS_Comins`i'.xls,first clear save temp,replace restore append using temp } save temp,replace同理,用foreach也是同样的思路 import exc $dir1/csmar/FS_Comins.xls,first clear foreach i in FS_Comins1 FS_Comins2 FS_Comins3{ preserve import exc $dir1/csmar/`i'.xls,first clear save temp,replace restore append using temp } save temp,replace上述循环的套用用在merge上也是一样,运用循环可以先试着写单独第一个运行的代码,再看循环要怎么改 数据结构的转换 Reshape主要是用于处理wind上下载的数据往往是在变量后面带年份,而没有年份变量的时候采用的 改变数据长宽结构,h reshape后显示命令
其中i就是初始用于识别哪个保持不变的唯一变量,j就是想要拆分或者是合并的那个变量,如果是合并,那么合并进新变量名后j将会消失,如果是拆分的话,那么拆分后将会新生成j变量 long 和wide的区别就是,你希望转变成wide型数据就用wide 例如一开始的数据为
之后就变成如下的数据,即新生成了变量year,之前recv和ta后面的年份变量就消失了 如果不在命令里的变量 ,默认进入i里面,所以必须要保证其他的变量是否也是唯一识别的变量。这也是常见不能够转换的原因。对于同一个year这类后标变量只能用一次,如果是有两个,例如行业分类要拆,年份也要拆后,则可以两两组合,但是这个时候唯一变量识别就需要在code同时加入第一个拆分的变量,例如: reshape long ta recv tl sales opincome ni cashflow fixasst, i(code) j(year) reshape long ind, i(code year) j(INDBase)上面的第一行代码,首先我将ta2002等变量转成了ta,第二行进一步将ind1和ind2拆成一个ind,那么这个时候如果我只用code的话就不再是唯一识别的一条观测了,所以在i()中加入第一行加入的year。 wide也是同样的注意点,对上述操作的反向操作如下 reshape wide ta recv tl sales opincome ni cashflow fixasst, i(code INDBase) j(year) reshape wide ind, i(code) j(INDBase)还有一种情况,是这两个要拆的或者加后缀的是针对于同一个变量,上一个例子指的是ind1、ind2变成ind和INDBase以及ta2002、ta2003······变成ta、year的组合,这里指的是ta变成ta2002A、ta2002B、ta2003A、ta2003B······A、B分别指的是合并报表和母公司报表的分类。(后面加string表示可以用字符串形式) 那么这种情况的拆分和合并除了上述的两种方法之外,在合并的时候还可以采用先采用加法讲两种后缀分开的方式 gen year=substr(Accper,1,4) gen month=substr(Accper,6,2) gen yearmonth=year+month drop month year reshape wide B001100000, i(Stkcd Accper ) j(Typrep) string reshape wide B001100000A B001100000B, i(Stkcd ) j(yearmonth) string后面两行可以进一步简化 gen Typrepyearmonth=Typrep+year+month drop month year Typrep Accper reshape wide B001100000, i(Stkcd Accper ) j(Typrep) string反向拆分就是 reshape long B001100000, i(Stkcd) j( Typrepyearmonth ) string进而再对新生成的Typrepyearmonth进行substr提取就可以了 字符型和数值型数据的相互转换 Destring将字符串形式转变成数值型
generate和replace很好理解,即想要转化某个变量的性质,是想生成新变量还是直接把原变量替代
在option中还有一个常用的就是ignore,在ignore括号中加入一串字符,可以在code这个变量中去除任意只要被这个字符串中包含的单个字符,例如虽然ignore中只有.SHZ但是code后缀中SZ或者是.SH均会被去除 在下面的例子中,首先,前两行我们将股票代码加入字符串型 replace code="900948.SH" if code=="900948" replace code="900949SZ" if code=="900949" destring code ,replace ig(".SHZ" ) Tostring则是和Destring类似,将数值型转变成字符串
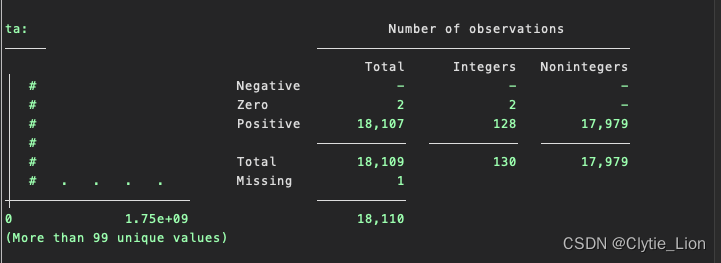
有一个需要注意的是是上面destring决定转变的变量格式是直接在option里添加,但是Tostring中则是有一个特定的format()函数 Real()将字符串转化为数字,如果字符串不是数字会变成缺失值 display real("5.2")+1 6.2将数字转化为字符串 display strofreal(123456789,"%11.0g") "123456789" 数据的描述 Inspect描述某个变量的正负分布 inspect ta
一般是对连续变量的描述性统计,与下面的tab进行区别 sum ta ni sum ta ni,detail
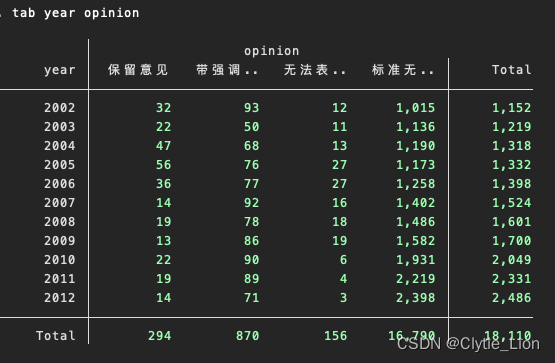
一般是对有限取值的变量进行分布统计 最多选择两个变量看联合分布 ,注意两个变量的时候,是第二个变量按照第一个变量的分布,例如下例就是意见按照年份的分布 tab year tab year opinion
可对多个变量的多个数据特征进行分组检验,下行代码ta tl sales ni cashflow是想要看的变量,opinion是分组变量,stat()中的是想要观察的数据特征,nototal是不显示最后不分组的全样本数据,long是指显示数据特征的名字 tabstat ta tl sales ni cashflow, by(opinion) stat(mean sd min max) nototal long
更为常见的统计表示方法是再加上c(s) 这里if注意不能写成2003 |












【本文地址】