R语言 |
您所在的位置:网站首页 › 中国语言的分类不包括 › R语言 |
R语言
|
R语言——数据类型详解
R语言支持的数据类型
数值型整数型逻辑型字符型复数型原生型
R语言的数据对象类型包括
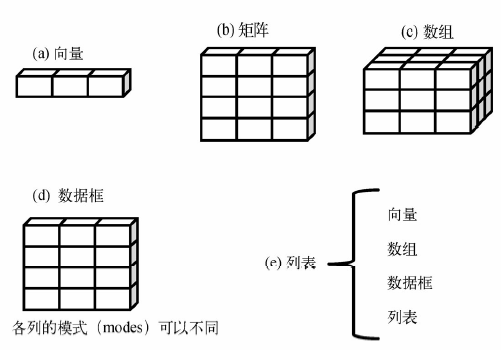
向量:一个向量只能有一种数据类型矩阵:一个矩阵只能有一种数据类型数组:一个数组只能有一种数据类型数据框:不同的列允许不同的数据类型因子:一个因子只能有一种数据类型列表:允许不同的数据类型
对于需要处理的数据可以根据各数据结构的特征选择适合的数据结构: 对于单个数,可以直接赋值给某一变量对于一组一维单类型数据,若为数值型数据可以选择向量,分类型数据可以选择因子二维、三维及以上的单类型数据选择矩阵和数组当有多种类型的数据需要保存到同一对象内时可以选择数据框 数据对象的属性R语言中数据的范围很广,函数,向量,维数,图像等都可以被称为对象。下面所说的对象均为用来存储数据的对象,不包含函数,图像等。 对象有四种属性:名称、维度、类型和长度。 长度长度为对象中所含的元素个数。 其中,向量、矩阵、数组、因子的长度即为其所含有的数据个数。 而数据框和列表略有不同。数据框可以认为是由n个数据类型不同的列向量组成的,因此每一列都是数据框的一个元素,其长度为列的个数;列表是由不同的对象聚集而成的,其包含的每一个对象都是它的一个元素,长度对包含的对象的个数。使用length()可以查看对象的长度。 例如: > a length(a) [1] 1 > b length(b) [1] 4 > c length(c) [1] 12 > d length(d) [1] 12 > e length(e) [1] 4 > f length(f) [1] 3 > g length(g) [1] 3 类型类型即为各数据结构类型,向量的类型即为其所含数据的类型。使用class()查看对象的类型。 如: > class(a) [1] "numeric" > class(b) [1] "character" > class(c) [1] "matrix" > class(d) [1] "array" > class(e) [1] "factor" > class(f) [1] "data.frame" > class(g) [1] "list" 维度 维度属性为对象各维度的长度,对象维度为1时,其维数属性的值为空,列表可以认为是元素特殊的向量,因此也是1维的。使用dim()可以查看。 如: > dim(a) NULL > dim(b) NULL > dim(c) [1] 3 4 > dim(d) [1] 3 2 2 > dim(e) NULL > dim(f) [1] 4 3 > dim(g) NULL 名称 名称,names()可以查看对象的名称,还可以对names赋值以改变名称。 1.向量向量可以由单个或多个值组成,多值的向量只能由相同类型的值组成,有一维和多维向量。 向量用于存储数值型、字符型、逻辑型数据 特别注意,R中的下标(索引)不从0开始,而是从1开始 a a [1] 1 2 3 4 5 b b [1] "banana" "tomato" "orange" "1" #注意 1 已经被强制性变成字符类数据 c=c(TRUE,FALSE,TRUE) > c [1] TRUE FALSE TRUE(逻辑向量类型) > rep(2:5,times=4) #rep()函数,对一个对象重复指定的次数 [1] 2 3 4 5 2 3 4 5 2 3 4 5 2 3 4 5 year = seq(from=1995,to=2020,by=5) #seq()函数,通过指定开头、结尾、步长来创建一个向量 > year [1] 1995 2000 2005 2010 2015 2020 >d=1:10 #指定开头、结尾,创建一个步长为1的向量 [1] 1 2 3 4 5 6 7 8 9 10 向量的简单操作 is.na()与!is.na()is.na()判断是否为缺失值,返回一个逻辑性向量 > m [1] 1 1 2 2 1 2 3 NA > is.na(m) [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE > m[is.na(m)]=0 > m [1] 1 1 2 2 1 2 3 0 paste()将自变量连接成一个字符串。 一般的使用形式是paste (…, sep = " ", collapse = NULL), … 表示想要连接的不同自变量,sep表示不同自变量之间添加的符号,collapse打开之后表示将整个自变量变成一个单一的变量 > x [1] "block" "block" "block" "plot" "plot" "plot" > y [1] 1 2 3 1 2 3 > paste(x,y,sep=',') [1] "block,1" "plot,1" "plot,2" "block,2" "plot,1" "plot,2" "plot,3" > paste(x,y,sep='') [1] "block1" "plot1" "plot2" "block2" "plot1" "plot2" "plot3" #将向量的不同元素进行组合,sep为空。 > z=paste(x,y,sep='',collapse =',')#将整个变成了一个变量,其中每个元素由 , 间隔。 > z [1] "block1,plot1,plot2,block2,plot1,plot2,plot3" rep()对对象进行重复 >rep(c("xx","dsads"),5) [1] "xx" "dsads" "xx" "dsads" "xx" "dsads" "xx" "dsads" "xx" "dsads" >rep_len(12,5) [1] 12 12 12 12 12 > rep(1:4,each=2) #对向量里面的每个元素重复2次 [1] 1 1 2 2 3 3 4 4 截取 利用索引进行截取 > a[1] #取得向量a里面的第一个元素 [1] 1 > a[1:3] [1] 1 2 3 > a a [1] 1 2 3 4 5 6 7 8 9 10 > a[-c(1,2,3)] #负号表示不取这个位置的元素,可以用来删除数据 [1] 4 5 6 7 8 9 10 利用逻辑截取 > o=a>3 > o [1] FALSE FALSE FALSE TRUE TRUE > a[o] [1] 4 5 > a[a>2] #也是利用逻辑截取 [1] 3 4 5 利用名字截取 > a a aa bb cc 1 2 3 > letters[1:5] #letters 是R自带的存储了字母的一个向量 [1] "a" "b" "c" "d" "e" > names(a) a d e f 1 2 3 4 5 > a["d"] d 1 向量的计算 > length(a)#向量长度 [1] 5 > mean(a)#向量的平均值 [1] 3 > median(a)#向量的中位数 [1] 3 > sd(a)#标准差的计算 [1] 1.581139 >var(a) #方差的计算 > a[1:3]-a[2:4]#注意,它是对两个向量的元素进行一一对应的计算 [1] -1 -1 -1 > (a[1:5]-10)*2 [1] -18 -16 -14 -12 -10 >aba-b [1] 0 0 0 0 0 -5 -5 -5 -5 -5 #因为a和b的长度不同,它们两个在进行计算的时候,会把比较短的a的元素重复利用 #另外,符号%/%表示整数除法,%%表示求余数 #R软件还可以作函数运算,例如基本初等函数log(), exp(), cos(), tan(), sqrt()等。当自变量为向量时,返回值也为向量,长度和自变量长度一致,每个分量取相应的函数值 简单判断 > all(a>1) #判断是否向量所有元素都大于1 [1] FALSE > any(a>1) #判断向量是否有一个元素大于1 [1] TRUE 2.因子(Factor)在统计学中,按照变量值是否连续把变量分为连续变量与离散变量两种。分类变量是说明事物类别的一个名称,其取值是分类数据。变量值是定性的,表现为互不相容的类别或属性。因子就是一类分类离散变量。 因子是带有水平(level)的向量。 因子的建立(factor)factor()函数一般形式为: Factor(x,levels=sort(unique(x),na.last=TRUE),labels,exclude=NA,ordered=FALSE) #其中,x是向量;levels是水平,可以自行制定各离散取值,默认取x的不同水平值; # labels用来指定各水平的标签,默认用各离散取值的对应字符串; # exclude参数用来指定要转化为缺失值(NA)的元素值集合,如果指定了levels,则当因子的第i个元素等于水平中的第j个元素时,元素值取”j”,如果它的值没有出现在levels中,则对应因子元素取NA; # ordered取值为真(TRUE)时,表示因子水平是有次序的(按编码次序),否则(默认值)是无次序的。 #可以用is.factor()检验对象是否是因子,用as.factor()把一个向量转化成一个因子 > numbers numbers numbers [1] aa bb cc aa aa bb Levels: aa bb cc 因子的简单操作 unique()函数可以用来筛选因子的level > x [1] "a1" "a2" "a3" "a4" "a1" "a2" "a1" > unique(x) #取得x中不重复的值 [1] "a1" "a2" "a3" "a4" 有序的因子level > numbers numbers [1] aa bb cc aa aa bb Levels: aa levels(numbers)#返回不同因子对应的值 [1] "aa" "bb" "cc" table()函数Table()函数对应的就是统计学中的列联表,是一种记录频数的方法。对于因子向量,可用函数table()来统计各类数据的频率。Table()的结果是一个带元素名的向量,元素名为因子水平,元素值为该水平的出现频率。 > plot.data #其中plot1和plot2都是因子类型 plot1 plot2 1 长白落叶松 水曲柳 2 红松 水曲柳 3 红松 水曲柳 4 白桦 黄菠萝 5 长白落叶松 水曲柳 > table(plot.data) plot2 plot1 黄菠萝 水曲柳 长白落叶松 0 2 红松 0 2 云杉 0 0 白桦 1 0 黄菠萝 0 0 水曲柳 0 0 tapply() 函数tapply()是对向量中的数据进行分组处理,而非对整体数据进行处理。函数一般形式为: tapply(X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE) #其中,X是一个对象,通常是一个向量; # INDEX是与X有同样长度的因子,表示按INDEX中的值分组,把相同值对应下标的X (array)中的元素形成一个集合,应用到需要计算的函数FUN。 #如果FUN返回的是一个值,tapply返回向量(vector);若FUN返回多个值,tapply返回列表(list)。vector或list的长度和INDEX的长度相等。 # simplify是逻辑变量,取为TRUE(默认)时tapply返回vector,FALSE时返回list。 #当FUN为NULL的时候,返回一个长度和X中元素个数相等的vector,指示分组的结果,vector中相等的元素所对应的下标属于同一组。 > plot.data SP p D 1 长白落叶松 plot1 20.5 2 红松 plot1 10.3 3 红松 plot1 16.7 4 白桦 plot1 25.4 5 长白落叶松 plot1 22.6 6 水曲柳 plot2 17.4 7 水曲柳 plot2 15.3 8 水曲柳 plot2 20.6 9 黄菠萝 plot2 23.5 10 水曲柳 plot2 12.9 > tapply(plot.data$D,plot.data$SP,mean) #计算每个树种的平均直径 白桦 红松 黄菠萝 水曲柳 长白落叶松 25.40 13.50 23.50 16.55 21.55 #这是一个非常有用的函数,可以很轻松的对一些数据进行简单的统计分析 gl() 函数gl()函数可以方便地产生因子,函数一般形式为: gl(n,k,length=n*k,labels=1:n,ordered=FALSE) #其中,n为水平数; #k为单个水平数的重复次数;length为产生的因子长度,默认为n*k; #labels是一个n维向量,表示因子水平数; #ordered 是逻辑变量,表示是否为有序因子,默认值为FALSE。 > gl(4,2) #产生水平数为1:4,每个水平数重复2次 [1] 1 1 2 2 3 3 4 4 Levels: 1 2 3 4 3.矩阵(Matrix)矩阵是一个二维数组,只是每个元素都拥有相同的数据类型(数值型、字符型或逻辑型)。注意与数据框的差别,数据框不同列的数据类型可以不同。 矩阵的建立(matrix)函数matrix ()是构造矩阵(二维数组)的函数,其构造形式为: matrix(data=NA,nrow=1,ncol=1,byrow=FALSE,dimnames=NULL) #其中,data是一个向量数据; #nrow是矩阵的行数; #ncol是矩阵的列数; #nrow与ncol的乘积需等于data向量的长度 #当byrow=TRUE时,生成矩阵的数据按行放置,默认值byrow=FALSE,数据按列放置; #dimnames是数组维的名字,默认值为空。可以输入包含行名,列名的一个list对数值行名、列名进行命名 > col_name=c("A","B","C")#编辑列名 > row_name=c("M","N")#行名 > y=matrix(1:6,nrow=2,ncol=3,byrow=TRUE,dimnames = list(row_name,col_name)) #nrow行数,ncol列数,byrow按行排列,dimnames对行和列进行命名 > y A B C M 1 2 3 N 4 5 6 > y1=t(y) #对y进行转置,好像列名和行名也发生了变化 > y1 [,1] [,2] [1,] 1 4 [2,] 2 5 [3,] 3 6 矩阵索引 #使用行、列下标来索引。 > a[3,2] [1] 8 #使用行和列名称来索引。 > a["r3","c2"] [1] 8 #使用一维下标来索引。 > a[1,]#以向量形式返回矩阵a第一行的所有元素 c1 c2 1 6 > a[,1]#以向量形式返回矩阵a第一列的所有元素 r1 r2 r3 r4 r5 1 2 3 4 5 矩阵编辑 矩阵合并 rbind()函数:通过行合并函数将多个已有向量合并成矩阵,同样还有cbind()。它们对行数或者列数是有要求的。rbind():两个向量/矩阵的列数需一致,cbind():两个向量/矩阵的行数需一致。 > x1 x2 rbind(x1,x2) [,1] [,2] [,3] [,4] [,5] x1 1 2 3 4 5 x2 6 7 8 9 10 删除矩阵内元素 删除矩阵内某行和某列的方式类似于向量,实质是对向量/矩阵重新赋值 > a rowSums(y) #行的和。colSums():列的和 [1] 6 15 > mean(y1[,2]) #对某一列进行平均值的计算 [1] 5 矩阵的加减法 > A B A+B [,1] [,2] [,3] [1,] 5 10 15 [2,] 9 14 19 [3,] 13 18 23 [4,] 17 22 27 矩阵各元素的乘法(A*B) > A*B [,1] [,2] [,3] [1,] 4 25 54 [2,] 14 48 90 [3,] 30 77 132 [4,] 52 112 180 矩阵的乘法(A%*%B),注意与矩阵各元素的乘法之间的差别 > A C A%*%C [,1] [,2] [,3] [,4] [1,] 157 112 67 22 [2,] 190 136 82 28 [3,] 223 160 97 34 [4,] 256 184 112 40 转置运算 > t(A) #利用t(A)函数对矩阵A进行转置 [,1] [,2] [,3] [,4] [1,] 1 2 3 4 [2,] 5 6 7 8 [3,] 9 10 11 12 求方阵的行列式,注意是方阵(即行与列的数量一样) > A [,1] [,2] [1,] 1 3 [2,] 2 4 > det(A)#利用det(A)函数求方阵A的行列式的值。 [1] -2 向量的内积: 对于n维向量x,可以看成n1阶矩阵或1n阶矩阵。若x与y是相同维数的向量,则x%%y表示x与y作内积 函数crossprod()是内积运算函数(表示交叉乘积),crossprod(x,y)计算向量x与y的内积,即”t(x)%%y”。crossprod(x)表示x与x的内积 类似地,函数tcrossprod(x,y)表示”x%*%t(y)”,即x与y的外积。 > x y x%*%y [,1] [1,] 60 向量的外积 设x,y是n维向量,则x%o%y表示x与y作外积 函数outer()是外积运算函数,outer(x,y)计算向量x与y的外积,它等价于x%o%y。 > x y x%o%y [,1] [,2] [,3] [,4] [1,] 2 4 6 8 [2,] 4 8 12 16 [3,] 6 12 18 24 [4,] 8 16 24 32 求矩阵的逆矩阵 求矩阵A的逆,命令形式为solve(A) > A [,1] [,2] [1,] 1 3 [2,] 2 4 > solve(A) [,1] [,2] [1,] -2 1.5 [2,] 1 -0.5 求矩阵的特征值和特征向量 求矩阵A的特征值和特征向量,命令形式为eigen(A) > A a a eigen() decomposition $`values` [1] 5.3722813 -0.3722813 $vectors [,1] [,2] [1,] -0.5657675 -0.9093767 [2,] -0.8245648 0.4159736 矩阵的奇异值分解 函数svd(A)是对矩阵A作奇异值分解,即A=UDVT ,其中U,V是正交阵,D为对角阵,也就是矩阵A的奇异值。svd(A)的返回值也是列表,svd(A)[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bq85Xs7f-1637756667584)(https://math.jianshu.com/math?formula=d%E8%A1%A8%E7%A4%BA%E7%9F%A9%E9%98%B5A%E7%9A%84%E5%A5%87%E5%BC%82%E5%80%BC%EF%BC%8C%E5%8D%B3%E7%9F%A9%E9%98%B5D%E7%9A%84%E5%AF%B9%E8%A7%92%E7%BA%BF%E4%B8%8A%E7%9A%84%E5%85%83%E7%B4%A0%E3%80%82svd(A)])u对应的是正交阵U,svd(A)$v对应的是正交阵V。 > A svd(A) $`d` [1] 5.4649857 0.3659662 $u [,1] [,2] [1,] -0.5760484 -0.8174156 [2,] -0.8174156 0.5760484 $v [,1] [,2] [1,] -0.4045536 0.9145143 [2,] -0.9145143 -0.4045536 apply()函数 apply()函数可以读取多维数组中某个维度的所有数据并应用其它函数进行数据处理。apply(x,MARGIN,FUN),x多维数组array,MARGIN预处理的维数(MARGIN=2代表对象为列,=1的话则为行),FUN多维数组中某一维度元素的处理函数(FUN=sd表示计算标准差,=sum的话表示计算和,只要有定义了的函数,便可以拿过来用) > apply(y,MARGIN=2,FUN=sd) [1] 2.12132 2.12132 2.12132 4.数组(array)数组与矩阵类似,但是维度可以大于2。数组有一个特征属性叫做维数向量(dim属性),维数向量是一个元素取正整数值的向量,其长度是数组的维数,比如维数向量有两个元素时数组为二维数组(矩阵)。维数向量的每一个元素指定了该下标的上界,下标的下界总为1。 数组的建立(array)R软件可以用array()函数直接构造数组,其构造形式为: Array(data=NA, dim=length(data),dimnames=NULL) #其中,data是一个向量数据; #dim是数组各维的长度,默认值为原向量的长度;dimnames是数组维的名字,默认值为空。 > dim1=c("A1","A2") > dim2=c("B1","B2","B3") > dim3=c("C1","C2") > z=array(1:12,c(2,3,2),dimnames = list(dim1,dim2,dim3)) #创立一个三维的数组,dimnames对名字进行命名 > z , , C1 B1 B2 B3 A1 1 3 5 A2 2 4 6 , , C2 B1 B2 B3 A1 7 9 11 A2 8 10 12 5.数据框(Data frame)数据框与矩阵类似,为二维,其数据框中各列的数据类型可以不同,但是长度必须一样。数据框在生物数据中用得比较多,是非常重要的一类数据类型。 数据框与矩阵不同的是数据框不同的列可以是不同的数据类型,并且数据框假定每列是一个变量,每行是一个观测值。 作为数据框变量的向量、因子或矩阵必须具有相同的长度(行数)。数据框可以用data.frame()函数生成,其用法与list()函数相同。 data.frame(col1,col2,col3…)其中列向量col1,col2等可以是任何类型的向量 > patientID age diabetes status=c("poor","improved","poor","excellent") > status=factor(status,order=TRUE,levels=c("poor","improved","excellent")) > patientData patientData patientID age diabetes status 1 1 22 t1 poor 2 2 13 t2 improved 3 3 42 t3 poor 4 4 21 t4 excellent #实例标识符可以通过数据框操作函数中的rowname选项指定 数据框的简单操作 > head(mtcars)#显示文件的前几行。tail()显示文件的后几行 mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 > colnames(mtcars) #显示文件的列名。rownames()显示文件的行名 [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb" > nrow(mtcars)#显示文件的行数。#ncol()显示文件的列数 [1] 32 > dim(mtcars)#显示文件的行数和列数 [1] 32 11 > str(patientData)#显示每一行数据类型,str()函数可以提供R中某个对象的信息 'data.frame': 4 obs. of 4 variables: $ patientID: num 1 2 3 4 $ age : num 22 13 42 21 $ diabetes : Factor w/ 4 levels "t1","t2","t3",..: 1 2 3 4 $ status : Ord.factor w/ 3 levels "poor" patientName patientChracter patientData2 patientData2 patientName patientChracter 1 jane tall 2 amy short 3 jimy very tall 4 cool prety tall > cbind(patientData,patientData2)#将两个数据框按列合在一起。rbind按行。merge patientID age diabetes status patientName patientChracter 1 1 22 t1 poor jane tall 2 2 13 t2 improved amy short 3 3 42 t3 poor jimy very tall 4 4 21 t4 excellent cool prety tall cor(mtcars)#数据相关系数的计算 数据框数据的筛选 索引筛选 > patientData[1:2,]#提取前两行。 patientID age diabetes status 1 1 22 t1 poor 2 2 13 t2 improved > patientData[,2:3]#提取后两列 age diabetes 1 22 t1 2 13 t2 3 42 t3 4 21 t4 > patientData[c(1,2),c(1,3)]#提取4个数据 patientID diabetes 1 1 t1 2 2 t2 名称筛选 > patientData[,c("diabetes","status")]#按列名来提取数据 diabetes status 1 t1 poor 2 t2 improved 3 t3 poor 4 t4 excellent > patientData$diabetes# $ 符号的使用:提取"diabetes"列,因子类型输出 [1] t1 t2 t3 t4 Levels: t1 t2 t3 t4 > patientData[,c("diabetes"),drop=FALSE]#提取diabetes列,仍是数据框输出 diabetes 1 t1 2 t2 3 t3 4 t4 逻辑筛选 > interestCol interestCol#逻辑向量输出(TRUE/FALSE) [1] FALSE FALSE TRUE FALSE > patientData[,interestCol]#筛选出"diabetes"两列 [1] t1 t2 t3 t4 Levels: t1 t2 t3 t4 > patientData[patientData$age>20,]#筛选出"age"大于20的行 patientID age diabetes status 1 1 22 t1 poor 3 3 42 t3 poor 4 4 21 t4 excellent subset筛选 > subset(patientData,age>20 & patientID>2) patientID age diabetes status 3 3 42 t3 poor 4 4 21 t4 excellent 排序 order > orderIndex orderIndex [1] 4 3 2 1 > patientData[orderIndex,]#按第一列大小排好序 patientID age diabetes status 4 4 21 t4 excellent 3 3 42 t3 poor 2 2 13 t2 improved 1 1 22 t1 poor 6.列表(List)列表可以储存不同类型的数据,是一些对象的有序集合。它的元素也由序号(下标)区分,但是各元素的类型可以是任意对象,不同元素不必是同一类型。元素本身允许是其他复杂数据类型。比如一个列表的元素也允许是一个列表。 R软件中利用函数list()构造列表,一般语法为: Lst a a $`a` [1] 11111 $b [1] 1 2 3 4 5 $c [,1] [,2] [,3] [1,] 1 3 5 [2,] 2 4 6 > d=c(1,4,2,2) > e=matrix(1:12,nrow=2,ncol=6) > f=patientData > mylist mylist [[1]] [1] 1 4 2 2 [[2]] [,1] [,2] [,3] [,4] [,5] [,6] [1,] 1 3 5 7 9 11 [2,] 2 4 6 8 10 12 [[3]] patientID age diabetes status 1 1 22 t1 poor 2 2 13 t2 improved 3 3 42 t3 poor 4 4 21 t4 excellent 列表数据的提取 > names(mylist) names(mylist) [1] "m" "n" "q" #要注意不同的访问方法产生的数据类型可能不一样 > names(mylist) [1] "m" "n" "q" > mylist["m"]#访问list元素方法,得到$m $m [1] 1 4 2 2 > mylist$m#访问list元素方法,得到$m $m > mylist[1]#得到$m $m [1] 1 4 2 2 > mylist[[1]]#得到原本的数据类型,即d(向量)的数据类型 [1] 1 4 2 2 > mylist[["m"]]#得到原本的数据类型 [1] 1 4 2 2 unlist()函数:将list函数拉直成一个向量 > data.list [[1]] [1] 1 1 1 1 1 1 1 2 2 2 2 2 2 2 [[2]] [1] "单木1" "单木2" "单木3" "单木4" "单木5" "单木6" "单木7" "单木1" "单木2" "单木3" "单木4" "单木5" "单木6" "单木7" [[3]] [1] "长白落叶松" "红松" "红松" "白桦" "长白落叶松" "白桦" "红松" "水曲柳" "水曲柳" [10] "水曲柳" "黄菠萝" "水曲柳" "黄菠萝" "水曲柳" [[4]] [1] "26.4" "18.4" "22.3" "27.1" "27.5" "15.2" "20.3" "18.5" "16.3" "21.4" "21.7" "14.3" "17.9" "20.8" $H2 [1] 1.885714 1.314286 1.592857 1.935714 1.964286 1.085714 1.450000 1.321429 1.164286 1.528571 1.550000 1.021429 1.278571 [14] 1.485714 > unlist(data.list)#会将list整个拉直成为一个向量》 "1" "1" "1" "1" "1" "1" "1" "2" "2" "2" "2" "2" "2" "2" "单木1" "单木2" "单木3" "单木4" "单木5" "单木6" "单木7" "单木1" "单木2" "单木3" "单木4" "单木5" "单木6" "单木7" "长白落叶松" "红松" "红松" "白桦" "长白落叶松" "白桦" "红松" "水曲柳" "水曲柳" "水曲柳" "黄菠萝" "水曲柳" "黄菠萝" "水曲柳" "26.4" "18.4" "22.3" "27.1" "27.5" "15.2" "20.3" "18.5" "16.3" "21.4" "21.7" "14.3" H21 H22 H23 H24 "17.9" "20.8" "1.88571428571429" "1.31428571428571" "1.59285714285714" "1.93571428571429" H25 H26 H27 H28 H29 H210 "1.96428571428571" "1.08571428571429" "1.45" "1.32142857142857" "1.16428571428571" "1.52857142857143" H211 H212 H213 H214 "1.55" "1.02142857142857" "1.27857142857143" "1.48571428571429"作者:芒果芭乐 链接:https://www.jianshu.com/p/47a15297a5f2 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 2.3" “27.1” “27.5” “15.2” "20.3" "18.5" "16.3" "21.4" "21.7" "14.3" H21 H22 H23 H24 "17.9" "20.8" "1.88571428571429" "1.31428571428571" "1.59285714285714" "1.93571428571429" H25 H26 H27 H28 H29 H210“1.96428571428571” “1.08571428571429” “1.45” “1.32142857142857” “1.16428571428571” “1.52857142857143” H211 H212 H213 H214 “1.55” “1.02142857142857” “1.27857142857143” “1.48571428571429” `` |


【本文地址】
今日新闻 |
推荐新闻 |