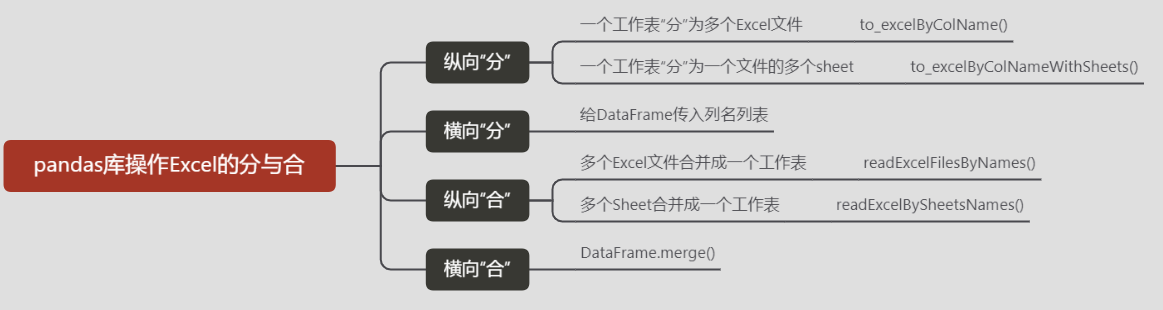
【Python自动化Excel】pandas处理Excel的拆分、合并 |
您所在的位置:网站首页 › 一个表格数据拆分成两个表格 › 【Python自动化Excel】pandas处理Excel的拆分、合并 |
【Python自动化Excel】pandas处理Excel的拆分、合并
|
话说Excel数据表,分久必合、合久必分。Excel数据表的“分”与“合”是日常办公中常见的操作。手动操作并不困难,但数据量大了之后,重复性操作往往会令人崩溃。利用Python的Pandas库,便可以自动实现Excel数据表的“分分合合”。下面结合实例来分享本人整理的实用代码片段。(如有更好的方式,欢迎批评指正)
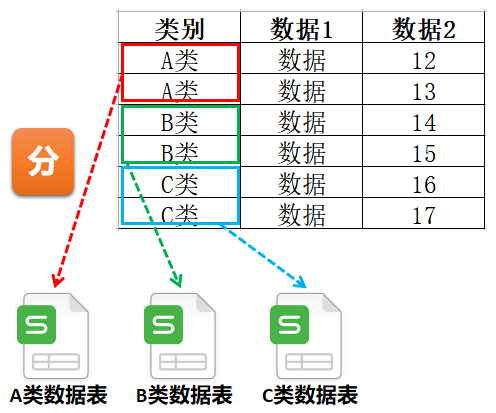
从数据平台(如问卷平台)中导出的数据往往是清单型的,每一行都是一条记录,数据量大的时候,表格往往是很“长”的。有时需要按照某列的不同数值,将一个总表“分”成单独的一些Excel文件。
例如:将20个班级1000名学生的总表,按班级分成20个Excel文件。 调用to_excelByColName函数,效果如下: to_excelByColName(sourceDf = sourceDf,colName="班级",outPath=".\分班数据表",excelName="生成数据表.xlsx")
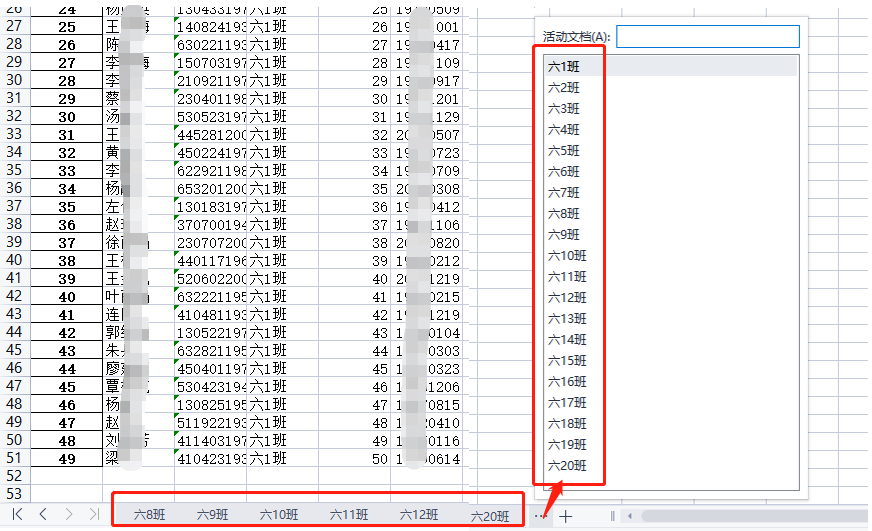
例如:将20个班级1000名学生的总表,按班级分成1个Excel文件的20个sheet表。 调用to_excelByColNameWithSheets函数,效果如下: to_excelByColNameWithSheets(sourceDf = sourceDf,colName="班级",outPath=".\分班数据表\生成数据表.xlsx")
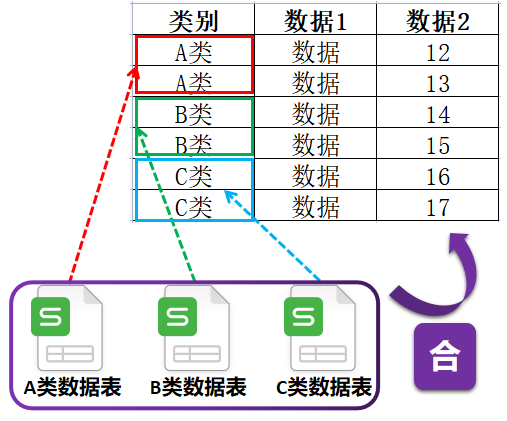
在处理数据的时候,有时需要添加多个辅助列,这样也会让数据表越来越“宽”。而最终我们只需要某些关键列即可,那么这就涉及到横向数据分割,或者说提取某些列保持成一个单独的数据表。横向的分割只需要给DataFrame传入列名列表即可。 例如:只需要数据表中的姓名和班级字段,可以这样写。 df1 = sourceDf[["姓名","班级"]] df1.to_excel("只含有姓名和班级的数据表.xlsx") 合:纵向“合”对于结构相同的数据,在数据处理时可以将其在纵向上拼接,方便一起处理。
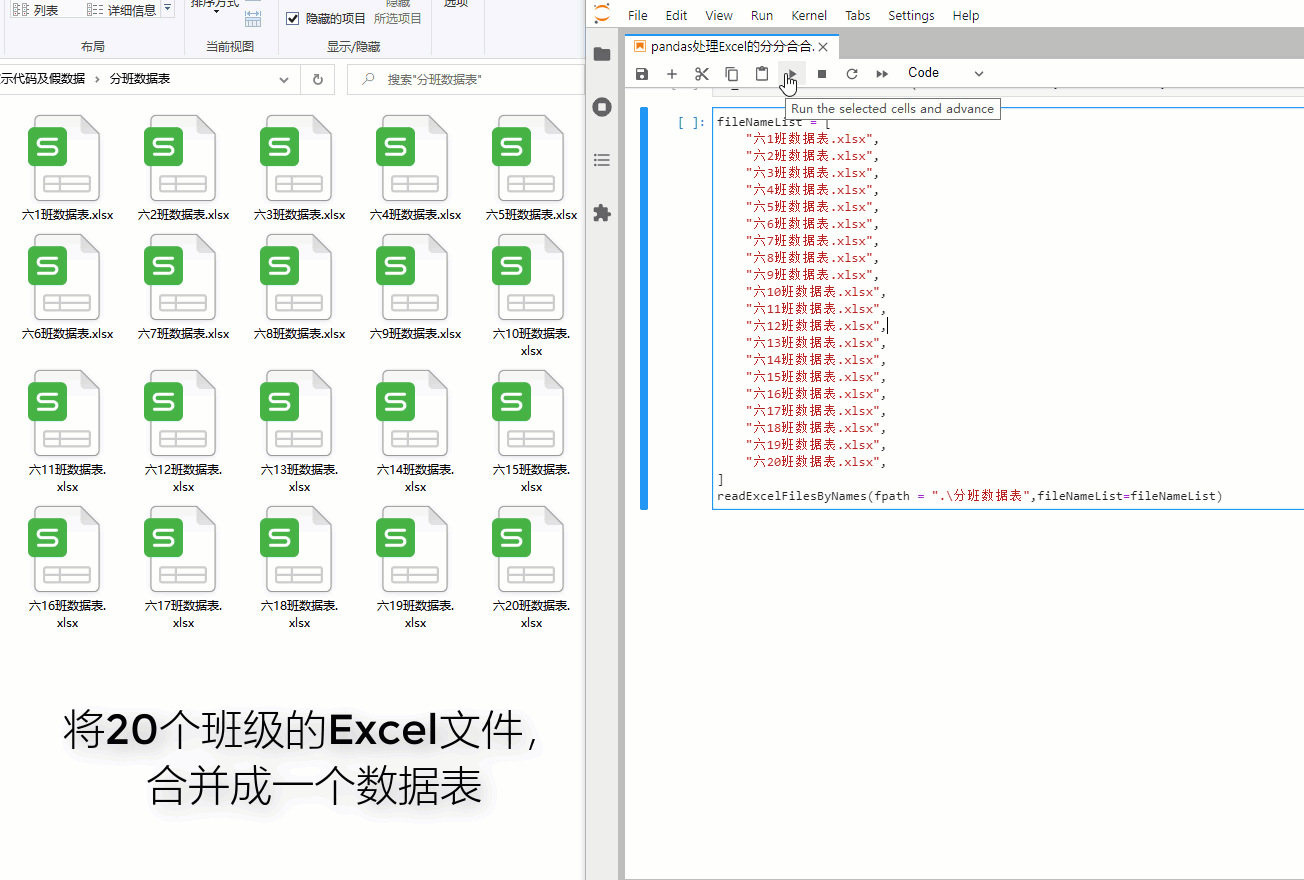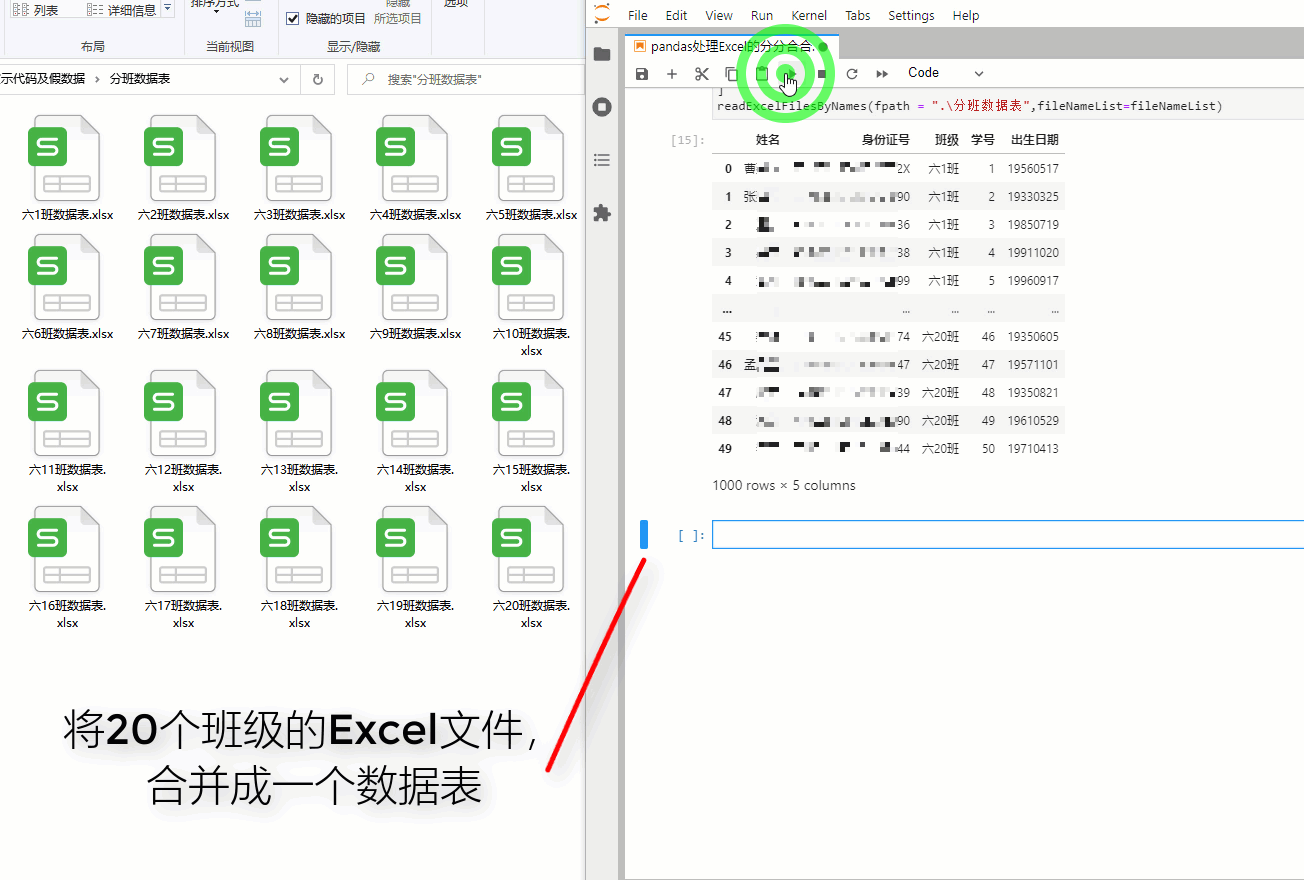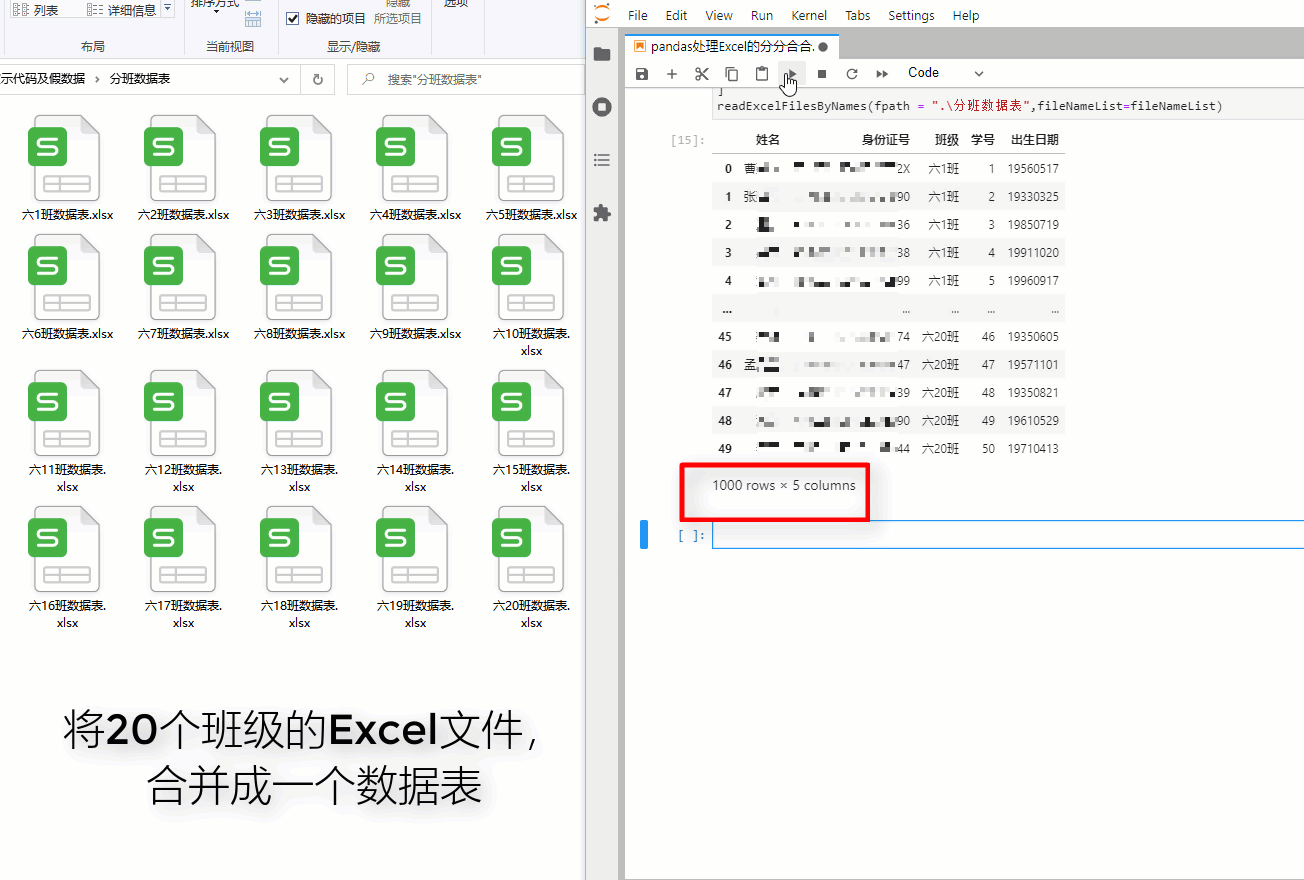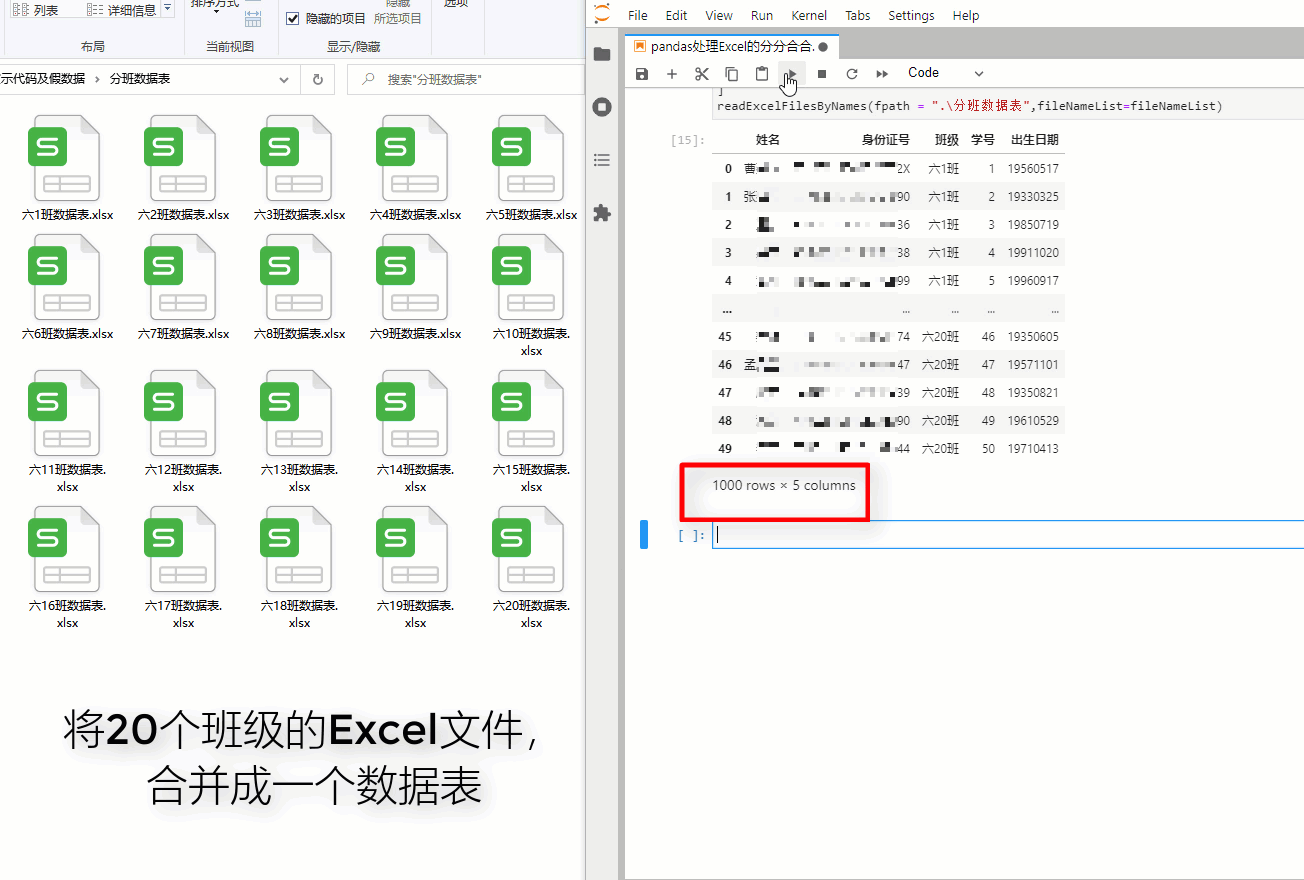
例如:将20个班级的Excel文件,合并成一个数据表 调用readExcelFilesByNames函数,效果如下: fileNameList = [ "六1班数据表.xlsx", "六2班数据表.xlsx", "六3班数据表.xlsx", "六4班数据表.xlsx", "六5班数据表.xlsx", "六6班数据表.xlsx", "六7班数据表.xlsx", "六8班数据表.xlsx", "六9班数据表.xlsx", "六10班数据表.xlsx", "六11班数据表.xlsx", "六12班数据表.xlsx", "六13班数据表.xlsx", "六14班数据表.xlsx", "六15班数据表.xlsx", "六16班数据表.xlsx", "六17班数据表.xlsx", "六18班数据表.xlsx", "六19班数据表.xlsx", "六20班数据表.xlsx", ] readExcelFilesByNames(fpath = ".\分班数据表",fileNameList=fileNameList)
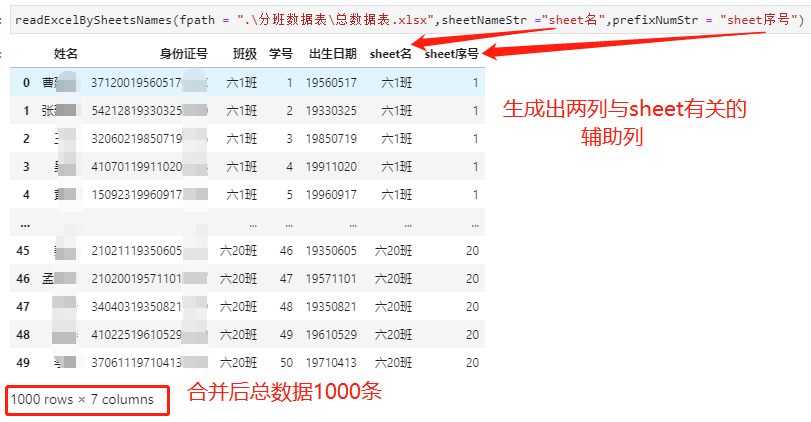
如下调用readExcelBySheetsNames,运行效果如下: readExcelBySheetsNames(fpath = ".\分班数据表\总数据表.xlsx",sheetNameStr ="sheet名",prefixNumStr = "sheet序号")
对于不同Excel工作表之间的横向合并,主要是用根据某些列(如:姓名、身份证号等)进行合并。在pandas库中可以用merge方法来实现,这是个十分好用的方式,展开讲篇幅较长,后续详细整理。 DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None) 结语本文所谈的Python处理Excel文件方式主要是基于pandas库的,主要针对的是清单型的数据表。清单型的数据表在下面的文章中有详细介绍: 数据表的分主要涉及的是文件保存(写入),对程序来说属于输出环节; 数据表的合主要针对的是文件打开(读取),对程序而言属于输入环节。 以上代码在针对大量重复性的表格分与合时,优势巨大;但对于偶尔、少量的分与合,也许用鼠标点击更快。 技术没有好坏之分,需要我们灵活使用! 清单型的数据表在下面的文章中有详细介绍: 数据表的分主要涉及的是文件保存(写入),对程序来说属于输出环节; 数据表的合主要针对的是文件打开(读取),对程序而言属于输入环节。 以上代码在针对大量重复性的表格分与合时,优势巨大;但对于偶尔、少量的分与合,也许用鼠标点击更快。 技术没有好坏之分,需要我们灵活使用! |

【本文地址】
今日新闻 |
推荐新闻 |