目标检测 |
您所在的位置:网站首页 › yolov1模型 › 目标检测 |
目标检测
目标检测|YOLOv2原理与实现(附YOLOv3)
 小小将
分类:机器学习
发布时间 2022.03.15阅读数 937 评论数 0
小小将
分类:机器学习
发布时间 2022.03.15阅读数 937 评论数 0
在前面的一篇文章中,我们详细介绍了YOLOv1的原理以及实现过程。这篇文章接着介绍YOLOv2的原理以及实现,YOLOv2的论文全名为YOLO9000: Better, Faster, Stronger,它斩获了CVPR 2017 Best Paper Honorable Mention。在这篇文章中,作者首先在YOLOv1的基础上提出了改进的YOLOv2,然后提出了一种检测与分类联合训练方法,使用这种联合训练方法在COCO检测数据集和ImageNet分类数据集上训练出了YOLO9000模型,其可以检测超过9000多类物体。所以,这篇文章其实包含两个模型:YOLOv2和YOLO9000,不过后者是在前者基础上提出的,两者模型主体结构是一致的。YOLOv2相比YOLOv1做了很多方面的改进,这也使得YOLOv2的mAP有显著的提升,并且YOLOv2的速度依然很快,保持着自己作为one-stage方法的优势,YOLOv2和Faster R-CNN, SSD等模型的对比如图1所示。这里将首先介绍YOLOv2的改进策略,并给出YOLOv2的TensorFlow实现过程,然后介绍YOLO9000的训练方法。近期,YOLOv3也放出来了,YOLOv3也在YOLOv2的基础上做了一部分改进,我们在最后也会简单谈谈YOLOv3所做的改进工作。
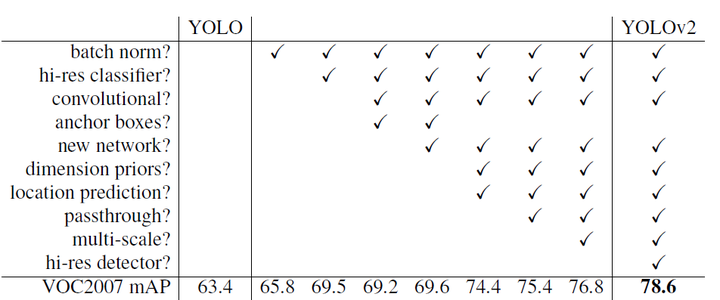
YOLOv1虽然检测速度很快,但是在检测精度上却不如R-CNN系检测方法,YOLOv1在物体定位方面(localization)不够准确,并且召回率(recall)较低。YOLOv2共提出了几种改进策略来提升YOLO模型的定位准确度和召回率,从而提高mAP,YOLOv2在改进中遵循一个原则:保持检测速度,这也是YOLO模型的一大优势。YOLOv2的改进策略如图2所示,可以看出,大部分的改进方法都可以比较显著提升模型的mAP。下面详细介绍各个改进策略。
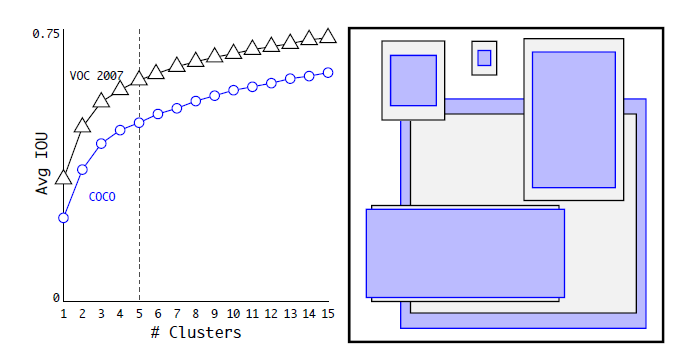
Batch Normalization Batch Normalization可以提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。在YOLOv2中,每个卷积层后面都添加了Batch Normalization层,并且不再使用droput。使用Batch Normalization后,YOLOv2的mAP提升了2.4%。 High Resolution Classifier 目前大部分的检测模型都会在先在ImageNet分类数据集上预训练模型的主体部分(CNN特征提取器),由于历史原因,ImageNet分类模型基本采用大小为 Convolutional With Anchor Boxes 在YOLOv1中,输入图片最终被划分为 使用anchor boxes之后,YOLOv2的mAP有稍微下降(这里下降的原因,我猜想是YOLOv2虽然使用了anchor boxes,但是依然采用YOLOv1的训练方法)。YOLOv1只能预测98个边界框( Dimension Clusters 在Faster R-CNN和SSD中,先验框的维度(长和宽)都是手动设定的,带有一定的主观性。如果选取的先验框维度比较合适,那么模型更容易学习,从而做出更好的预测。因此,YOLOv2采用k-means聚类方法对训练集中的边界框做了聚类分析。因为设置先验框的主要目的是为了使得预测框与ground truth的IOU更好,所以聚类分析时选用box与聚类中心box之间的IOU值作为距离指标: 图3为在VOC和COCO数据集上的聚类分析结果,随着聚类中心数目的增加,平均IOU值(各个边界框与聚类中心的IOU的平均值)是增加的,但是综合考虑模型复杂度和召回率,作者最终选取5个聚类中心作为先验框,其相对于图片的大小如右边图所示。对于两个数据集,5个先验框的width和height如下所示(来源:YOLO源码的cfg文件): COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)但是这里先验框的大小具体指什么作者并没有说明,但肯定不是像素点,从代码实现上看,应该是相对于预测的特征图大小(
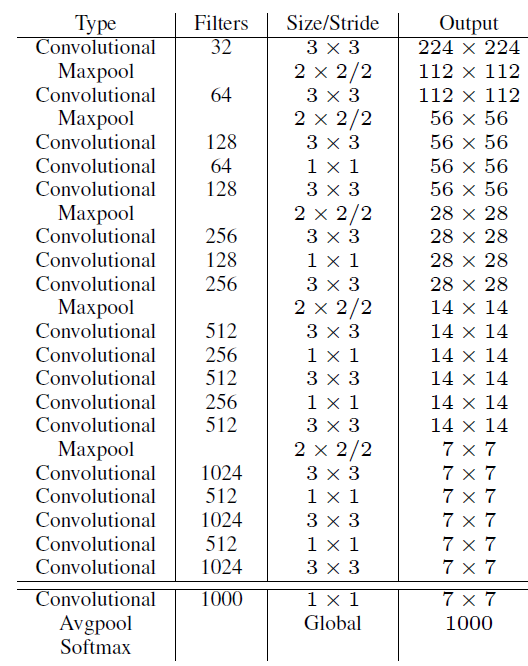
New Network: Darknet-19 YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如图4所示。Darknet-19与VGG16模型设计原则是一致的,主要采用
Direct location prediction 前面讲到,YOLOv2借鉴RPN网络使用anchor boxes来预测边界框相对先验框的offsets。边界框的实际中心位置 但是上面的公式是无约束的,预测的边界框很容易向任何方向偏移,如当 其中 如果再将上面的4个值分别乘以图片的宽度和长度(像素点值)就可以得到边界框的最终位置和大小了。这就是YOLOv2边界框的整个解码过程。约束了边界框的位置预测值使得模型更容易稳定训练,结合聚类分析得到先验框与这种预测方法,YOLOv2的mAP值提升了约5%。 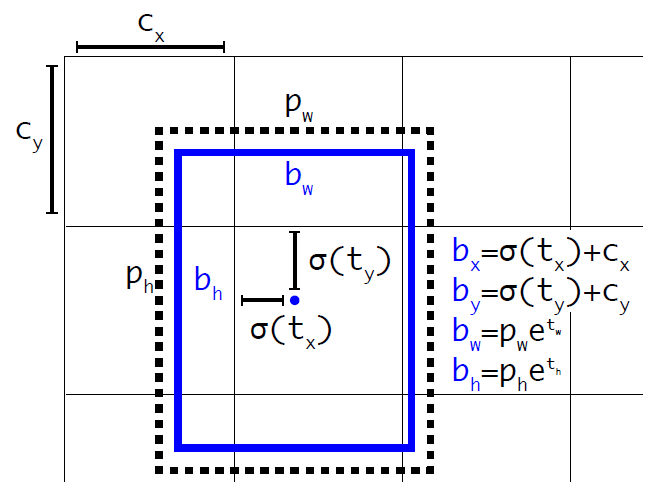 图5:边界框位置与大小的计算示例图
图5:边界框位置与大小的计算示例图
Fine-Grained Features YOLOv2的输入图片大小为 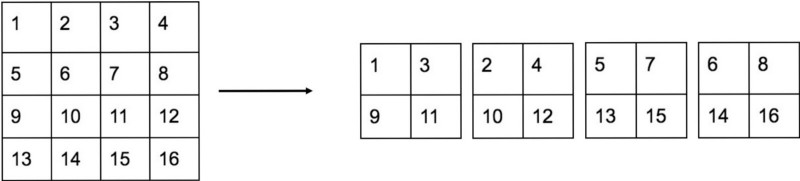 图6:passthrough层实例
图6:passthrough层实例
另外,作者在后期的实现中借鉴了ResNet网络,不是直接对高分辨特征图处理,而是增加了一个中间卷积层,先采用64个 Multi-Scale Training 由于YOLOv2模型中只有卷积层和池化层,所以YOLOv2的输入可以不限于 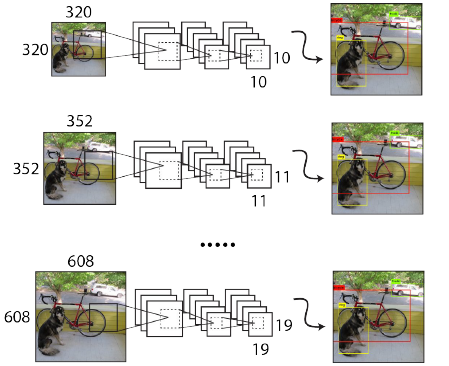 图7:Multi-Scale Training
图7:Multi-Scale Training
采用Multi-Scale Training策略,YOLOv2可以适应不同大小的图片,并且预测出很好的结果。在测试时,YOLOv2可以采用不同大小的图片作为输入,在VOC 2007数据集上的效果如下图所示。可以看到采用较小分辨率时,YOLOv2的mAP值略低,但是速度更快,而采用高分辨输入时,mAP值更高,但是速度略有下降,对于 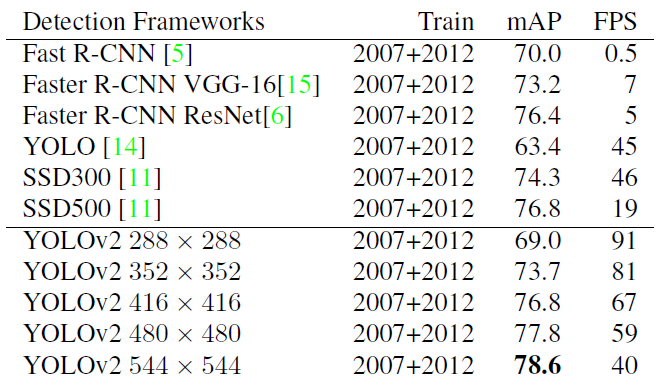 图8:YOLOv2在VOC 2007数据集上的性能对比
图8:YOLOv2在VOC 2007数据集上的性能对比
总结来看,虽然YOLOv2做了很多改进,但是大部分都是借鉴其它论文的一些技巧,如Faster R-CNN的anchor boxes,YOLOv2采用anchor boxes和卷积做预测,这基本上与SSD模型(单尺度特征图的SSD)非常类似了,而且SSD也是借鉴了Faster R-CNN的RPN网络。从某种意义上来说,YOLOv2和SSD这两个one-stage模型与RPN网络本质上无异,只不过RPN不做类别的预测,只是简单地区分物体与背景。在two-stage方法中,RPN起到的作用是给出region proposals,其实就是作出粗糙的检测,所以另外增加了一个stage,即采用R-CNN网络来进一步提升检测的准确度(包括给出类别预测)。而对于one-stage方法,它们想要一步到位,直接采用“RPN”网络作出精确的预测,要因此要在网络设计上做很多的tricks。YOLOv2的一大创新是采用Multi-Scale Training策略,这样同一个模型其实就可以适应多种大小的图片了。 YOLOv2的训练YOLOv2的训练主要包括三个阶段。第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 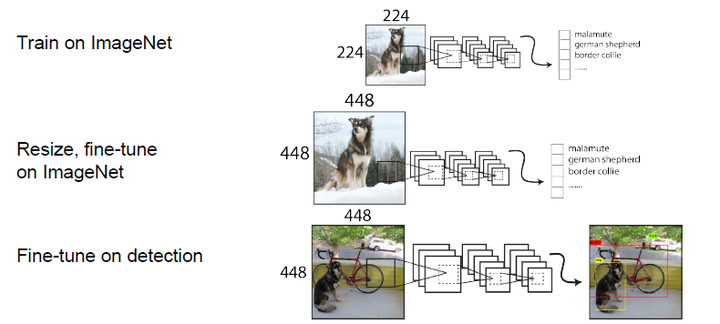 图9:YOLOv2训练的三个阶段
图9:YOLOv2训练的三个阶段
 图10:YOLOv2结构示意图
图10:YOLOv2结构示意图
YOLOv2的网络结构以及训练参数我们都知道了,但是貌似少了点东西。仔细一想,原来作者并没有给出YOLOv2的训练过程的两个最重要方面,即先验框匹配(样本选择)以及训练的损失函数,难怪Ng说YOLO论文很难懂,没有这两方面的说明我们确实不知道YOLOv2到底是怎么训练起来的。不过默认按照YOLOv1的处理方式也是可以处理,我看了YOLO在TensorFlow上的实现darkflow(见yolov2/train.py),发现它就是如此处理的:和YOLOv1一样,对于训练图片中的ground truth,若其中心点落在某个cell内,那么该cell内的5个先验框所对应的边界框负责预测它,具体是哪个边界框预测它,需要在训练中确定,即由那个与ground truth的IOU最大的边界框预测它,而剩余的4个边界框不与该ground truth匹配。YOLOv2同样需要假定每个cell至多含有一个grounth truth,而在实际上基本不会出现多于1个的情况。与ground truth匹配的先验框计算坐标误差、置信度误差(此时target为1)以及分类误差,而其它的边界框只计算置信度误差(此时target为0)。YOLOv2和YOLOv1的损失函数一样,为均方差函数。 但是我看了YOLOv2的源码(训练样本处理与loss计算都包含在文件region_layer.c中,YOLO源码没有任何注释,反正我看了是直摇头),并且参考国外的blog以及allanzelener/YAD2K(Ng深度学习教程所参考的那个Keras实现)上的实现,发现YOLOv2的处理比原来的v1版本更加复杂。先给出loss计算公式: 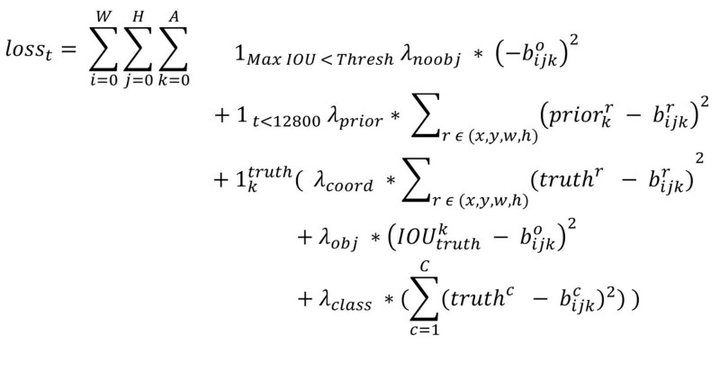
我们来一点点解释,首先 最终的YOLOv2模型在速度上比YOLOv1还快(采用了计算量更少的Darknet-19模型),而且模型的准确度比YOLOv1有显著提升,详情见paper。 YOLOv2在TensorFlow上实现这里参考YOLOv2在Keras上的复现(见yhcc/yolo2),使用TensorFlow实现YOLOv2在COCO数据集上的test过程。首先是定义YOLOv2的主体网络结构Darknet-19: def darknet(images, n_last_channels=425): """Darknet19 for YOLOv2""" net = conv2d(images, 32, 3, 1, name="conv1") net = maxpool(net, name="pool1") net = conv2d(net, 64, 3, 1, name="conv2") net = maxpool(net, name="pool2") net = conv2d(net, 128, 3, 1, name="conv3_1") net = conv2d(net, 64, 1, name="conv3_2") net = conv2d(net, 128, 3, 1, name="conv3_3") net = maxpool(net, name="pool3") net = conv2d(net, 256, 3, 1, name="conv4_1") net = conv2d(net, 128, 1, name="conv4_2") net = conv2d(net, 256, 3, 1, name="conv4_3") net = maxpool(net, name="pool4") net = conv2d(net, 512, 3, 1, name="conv5_1") net = conv2d(net, 256, 1, name="conv5_2") net = conv2d(net, 512, 3, 1, name="conv5_3") net = conv2d(net, 256, 1, name="conv5_4") net = conv2d(net, 512, 3, 1, name="conv5_5") shortcut = net net = maxpool(net, name="pool5") net = conv2d(net, 1024, 3, 1, name="conv6_1") net = conv2d(net, 512, 1, name="conv6_2") net = conv2d(net, 1024, 3, 1, name="conv6_3") net = conv2d(net, 512, 1, name="conv6_4") net = conv2d(net, 1024, 3, 1, name="conv6_5") # --------- net = conv2d(net, 1024, 3, 1, name="conv7_1") net = conv2d(net, 1024, 3, 1, name="conv7_2") # shortcut shortcut = conv2d(shortcut, 64, 1, name="conv_shortcut") shortcut = reorg(shortcut, 2) net = tf.concat([shortcut, net], axis=-1) net = conv2d(net, 1024, 3, 1, name="conv8") # detection layer net = conv2d(net, n_last_channels, 1, batch_normalize=0, activation=None, use_bias=True, name="conv_dec") return net然后实现对Darknet-19模型输出的解码: def decode(detection_feat, feat_sizes=(13, 13), num_classes=80, anchors=None): """decode from the detection feature""" H, W = feat_sizes num_anchors = len(anchors) detetion_results = tf.reshape(detection_feat, [-1, H * W, num_anchors, num_classes + 5]) bbox_xy = tf.nn.sigmoid(detetion_results[:, :, :, 0:2]) bbox_wh = tf.exp(detetion_results[:, :, :, 2:4]) obj_probs = tf.nn.sigmoid(detetion_results[:, :, :, 4]) class_probs = tf.nn.softmax(detetion_results[:, :, :, 5:]) anchors = tf.constant(anchors, dtype=tf.float32) height_ind = tf.range(H, dtype=tf.float32) width_ind = tf.range(W, dtype=tf.float32) x_offset, y_offset = tf.meshgrid(height_ind, width_ind) x_offset = tf.reshape(x_offset, [1, -1, 1]) y_offset = tf.reshape(y_offset, [1, -1, 1]) # decode bbox_x = (bbox_xy[:, :, :, 0] + x_offset) / W bbox_y = (bbox_xy[:, :, :, 1] + y_offset) / H bbox_w = bbox_wh[:, :, :, 0] * anchors[:, 0] / W * 0.5 bbox_h = bbox_wh[:, :, :, 1] * anchors[:, 1] / H * 0.5 bboxes = tf.stack([bbox_x - bbox_w, bbox_y - bbox_h, bbox_x + bbox_w, bbox_y + bbox_h], axis=3) return bboxes, obj_probs, class_probs我将YOLOv2的官方训练权重文件转换了TensorFlow的checkpoint文件(下载链接),具体的测试demo都放在我的GitHub上了,感兴趣的可以去下载测试一下,至于train的实现就自己折腾吧,相对会棘手点。  图11:YOLOv2在自然图片上的测试
YOLO9000
图11:YOLOv2在自然图片上的测试
YOLO9000
YOLO9000是在YOLOv2的基础上提出的一种可以检测超过9000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。众多周知,检测数据集的标注要比分类数据集打标签繁琐的多,所以ImageNet分类数据集比VOC等检测数据集高出几个数量级。在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。 作者选择在COCO和ImageNet数据集上进行联合训练,但是遇到的第一问题是两者的类别并不是完全互斥的,比如"Norfolk terrier"明显属于"dog",所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree,结合COCO和ImageNet建立的WordTree如下图所示: 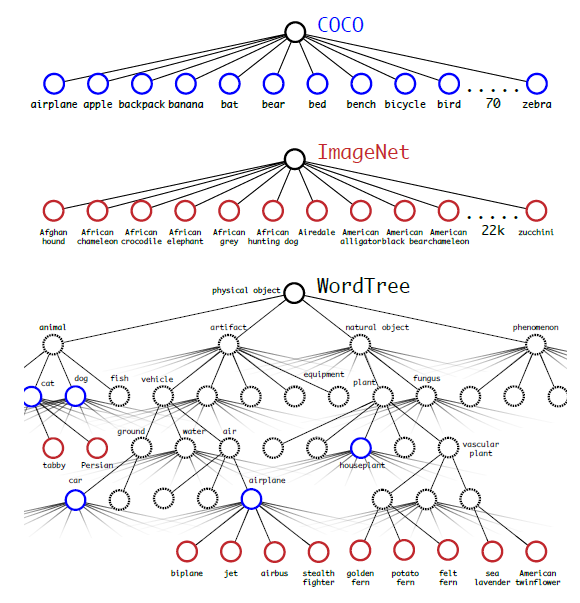 图12:基于COCO和ImageNet数据集建立的WordTree
图12:基于COCO和ImageNet数据集建立的WordTree
WordTree中的根节点为"physical object",每个节点的子节点都属于同一子类,可以对它们进行softmax处理。在给出某个类别的预测概率时,需要找到其所在的位置,遍历这个path,然后计算path上各个节点的概率之积。 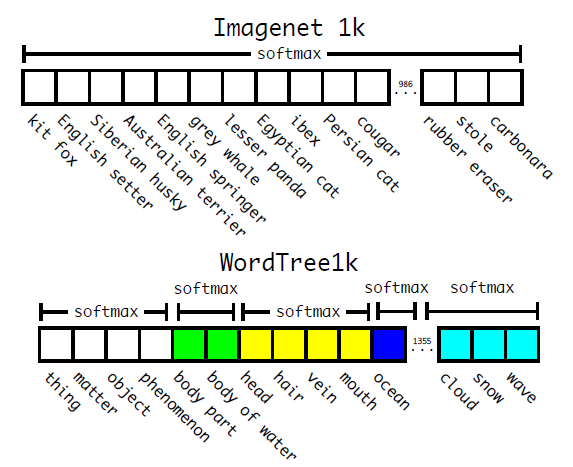 图13:ImageNet与WordTree预测的对比
图13:ImageNet与WordTree预测的对比
在训练时,如果是检测样本,按照YOLOv2的loss计算误差,而对于分类样本,只计算分类误差。在预测时,YOLOv2给出的置信度就是 通过联合训练策略,YOLO9000可以快速检测出超过9000个类别的物体,总体mAP值为19,7%。我觉得这是作者在这篇论文作出的最大的贡献,因为YOLOv2的改进策略亮点并不是很突出,但是YOLO9000算是开创之举。 YOLOv3近期,YOLOv3发布了,但是正如作者所说,这仅仅是他们近一年的一个工作报告(TECH REPORT),不算是一个完整的paper,因为他们实际上是把其它论文的一些工作在YOLO上尝试了一下。相比YOLOv2,我觉得YOLOv3最大的变化包括两点:使用残差模型和采用FPN架构。YOLOv3的特征提取器是一个残差模型,因为包含53个卷积层,所以称为Darknet-53,从网络结构上看,相比Darknet-19网络使用了残差单元,所以可以构建得更深。另外一个点是采用FPN架构(Feature Pyramid Networks for Object Detection)来实现多尺度检测。YOLOv3采用了3个尺度的特征图(当输入为 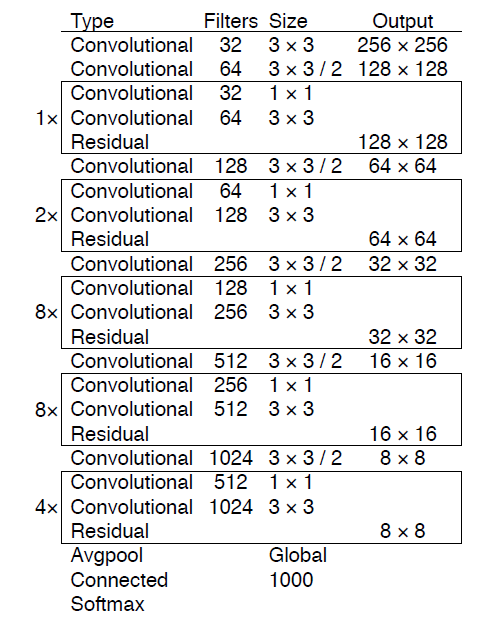 图14:YOLOv3所用的Darknet-53模型
图14:YOLOv3所用的Darknet-53模型
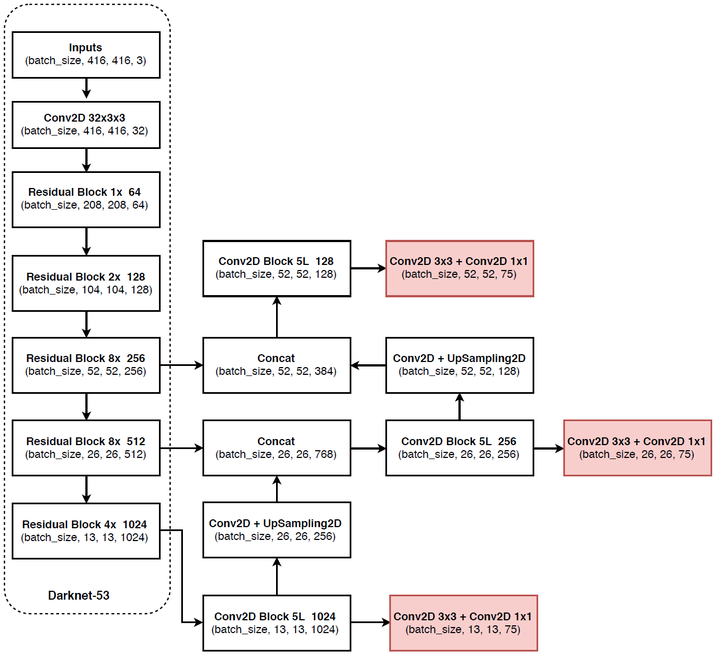 图15 YOLOv3网络结构示意图(VOC数据集)
图15 YOLOv3网络结构示意图(VOC数据集)
YOLOv3与其它检测模型的对比如下图所示,可以看到在速度上YOLOv3完胜其它方法,虽然AP值并不是最好的(如果比较AP-0.5,YOLOv3优势更明显)。 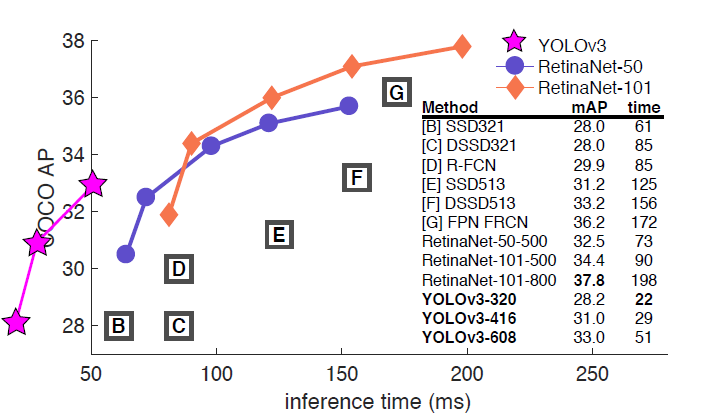 图16:YOLOv3在COCO测试集与其它检测算法对比图
小结
图16:YOLOv3在COCO测试集与其它检测算法对比图
小结
从YOLO的三代变革中可以看到,在目标检测领域比较好的策略包含:设置先验框,采用全卷积做预测,采用残差网络,采用多尺度特征图做预测。期待未来有更好的策略出现。本人水平有限,文中难免出现错误,欢迎指正! 参考 Darknet官网. thtrieu/darkflow. You Only Look Once: Unified, Real-Time Object Detection. YOLO9000: Better, Faster, Stronger. YOLOv3: An Incremental Improvement. yhcc/yolo2. pytorch-yolo2. Training Object Detection (YOLOv2) from scratch using Cyclic Learning Rates. allanzelener/YAD2K. marvis/pytorch-yolo3. 机器学习YOLO深度学习神经网络图像处理转载原出处:https://zhuanlan.zhihu.com/p/35325884 打赏 0 点赞 0 收藏 0 分享 微信 微博 QQ 图片 上一篇:目标检测|YOLO原理与实现 下一篇:目标检测|SSD原理与实现 |

【本文地址】
今日新闻 |
推荐新闻 |