CVPR 2022 Oral |
您所在的位置:网站首页 › vit图像去模糊 › CVPR 2022 Oral |
CVPR 2022 Oral
|
CVPR 2022 Oral | MAXIM: Multi-Axis MLP for Image Processing
这篇论文写的一眼难尽。可能是因为涉及到很多的内容,总想全面,但是却又无法完美。很多细节都在附录里,正文看完在看附录,你会发现原来是这样。。。 这是一篇在底层视觉任务上构建更有效的局部+全局交互策略的文章,再多个任务上实现了良好的效果。 主要内容
现在许多Transformer和MLP的工作在目标识别等任务中体现出来了不错的效果,但是其在底层视觉任务上的应用中仍然充满挑战。最近有这样一些尝试: 直接应用来自Transformer的full self-attention,由于其高昂的计算成本,只能使用相对小的patch作为输入。这样基于crop的策略将不可避免地造成patch边界的伪影。采用局部注意力的策略来约束self-attention的计算复杂度,这在一定程度上缓解一些问题。但是这也受限于有限的感受野,或者说丢失了非局部性,而这正是Transformer或者MLP模型相较于分层CNN模型的重要优势所在。所以,作者们将困难归因于这些结构并不够灵活来支持高分辨率的图像,以及他们在局部注意力上的局限。
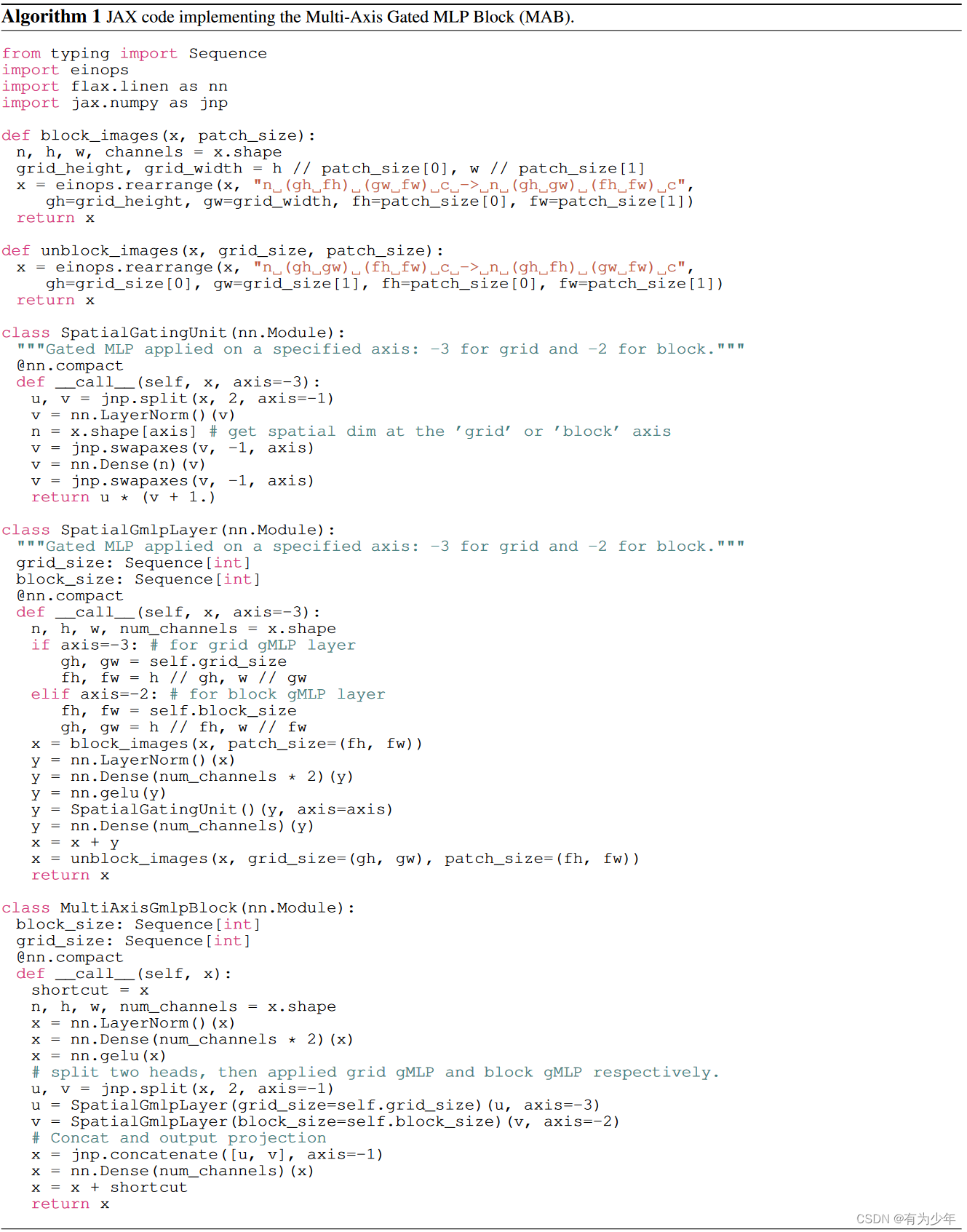
具体而言,MAXIM包括了两种MLP构建单元: 多轴门控MLP(multi-axis gated MLP),这允许实现有效和可伸缩的局部和全局视觉线索的空间混合。交叉门控块(cross-gating block),这是一种对于交叉注意力的替换,负责跨特征的调解(cross-feature conditioning)。这些设计仅仅基于MLP操作,而且都受益于全局和全卷积的属性。这两种属性对于图像处理任务来说都是很需要的。 这些提出的核心构建块基于多轴策略,并行式的捕获局部(Conv)和全局(MLP)的交互(局部感受野+全局感受野)。在每个分支上,通过单轴混合信息,这种基于MLP的操作变成了全卷积的形式(输入形状无约束),并且可以相对于图像大小实现线性放缩(线性复杂度),这显著增加了结构对于密集图像处理任务的灵活性,而且提出的方法也不需要使用大规模预训练。 最终提出的方法在多个底层视觉任务——去噪、去模糊、去雨、去雾和增强——上获得了最好的效果。 MAXIM延续了最近的恢复模型的形式,作者们基于多阶段范式,通过堆叠提出的结构,构建了一种简单有效的多阶段、多尺度的“编码-解码”架构。 对于多阶段结构中的每一个阶段,都可以称为一个独立的MAXIM骨干模型,者遵循编解码设计模式。 观察到具有较小感受野(例如Conv3x3)的操作对于UNet网络的性能至关重要,因此作者们在模块设计中采用了混合形式。使用卷积处理局部,使用MLP处理长距离依赖,从而充分利用他们(to make the most of them)。 因此本文的设计主要在于如何简单有效的实现局部交互、全局交互、以及局部和全局信息的整合。 对于整体模型而言,有许多零碎的调整: 基础构建单元:为了在不同尺度进行长距离空间交互,作者们在让多轴门控MLP块与图像恢复中常用的残差通道注意力模块(RCAB)搭配使用,顺序堆叠在每个编码器、解码器和瓶颈层中。编解码器连接:同时受到[Attention u-net: Learning where to look for the pancreas和U-net transformer: self and cross attention for medical image segmentation]中编码器与解码器之间的skip connection上的门控滤波机制的启发,作者们扩展了门控MLP(gMLP:Pay attention to mlps)来构建了cross gating block(CGB),这是一种对于传统的基于三阶相关的交叉注意力的有效的二阶替换,来控制或者约束两个的不同的特征。在CGB模块中,使用来自瓶颈层中的全局特征来门控处理skip connection结构,同时将细化的全局特征上传到下一个CGB模块中。不同stage之间的连接接:不同尺度特征之间的多尺度融合被用来集成来自各个编码器和来自各个CGB输出的特征。 Multi-Axis Gated MLP(MAB)这份工作收到了Improved Transformer for High-Resolution GANs(HiT)中引入的多轴块自注意力机制的启发,但是这篇参考工作中的设计并不太适合与图像恢复或者是图像增强任务,因为要面对的图像通常具有任意的形状(这里解释的有些牵强,因为严格来讲,本文的方法也没法处理任意形状,毕竟每个模块的划分必须保证边长可以被b和g拆分,只能说这里的方法基于MLP形式更加简单)。
具体操作流程: 特征送入模块中,通过按照头,均匀拆分成两部分,分别送入局部分支和全局分支。局部分支中: 特征划分成H/bxW/b个不重叠的bxb大小的块:(C/2,H,W)->(H/bxW/b,bxb,C/2)。在具有固定大小的维度bxb上使用gMLP块其他轴共享参数,以保证对于输入形状的无约束,即全卷积性质。这种操作可以理解为一种局部交互操作,因为其工作在局部的邻域上。将特征形状恢复原始状态:(H/bxW/b,bxb,C/2)->(C/2,H,W) 全局分支中: 特征则被分配到多个dxd大小的网格中,即划分为dxd个大小为H/dxW/d的块:(C/2,H,W)->(dxd,H/dxW/d,C/2)。在具有固定大小的维度dxd上使用gMLP块其他轴共享参数,以保证对于输入形状的无约束,即全卷积性质。这种操作可以理解为一种全局(扩张)的交互操作,因为其工作在被聚集在邻域上的稀疏的全局信息。将特征形状恢复到原始状态:(dxd,H/dxW/d,C/2)->(C/2,H,W) 两个分支的结果被拼接到一起,之后一起投影降低通道数。这里的策略实际上体现出了一种可伸缩的将1d操作应用在二维图像上的方法,这具有灵活性和通用性。实际上,可以用其他的算子,例如空间MLP、自注意力、甚至是傅里叶变换等替代这里实际使用的gMLP。 Cross Gating MLP Block(CGB)UNet的一种常见改进,是利用纹理特征来选择门控skip connections的特征传播,可以使用交叉注意力实现。这里实现了一种轻量级的替代结构CGB。他是MAB的一种扩展,可以实现多个特征的交互。 计算流程: 输入的x1和y1各自通过独立的线性层、归一化层和激活层得到x2和y2。通过多轴块计算门控权重。这里使用了交叉的形式,即x2计算y2的权重,y2计算x2的权重,分别得到hatx和haty。算出来的权重使用像素级乘法处理x2和y2。这里计算权重的多轴块有这样的计算过程: 输入经过归一化层、线性层和激活层得到z。将特征沿通道拆分分别送入local和global结构中,变形、MLP、恢复形状。结果输出后沿通道拼接再经过一个线性层输出。 hatx和haty各自经过一个独立的线性层后与原始输入x1和x2相加得到两个输入各自对应的实际输出。 Multi-Stage Multi-Scale Framework
|

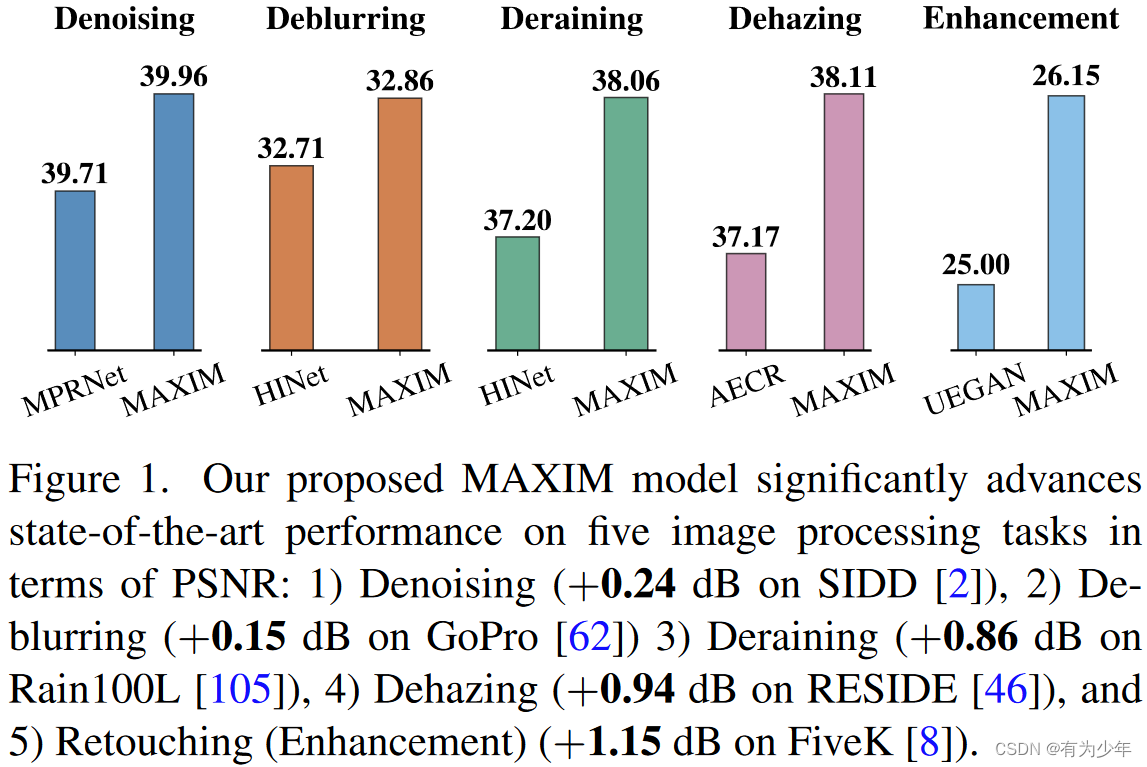 图像处理任务,例如恢复和增强,都是重要的计算机视觉任务,这些主要的目的在于从退化的输入上产生理想的输出。不同类型的退化可能需要不同的图像增强策略,例如去噪denoising、去模糊deblurring、超分辨super-resolution、去雾dehazing、低亮度增强low-light enhancement和其他的一些任务。随着精细构建的大规模训练集的增加,最近许多高性能方法基于精心设计的CNN架构,在许多任务上获得了卓越的效果。提升模型的架构设计是大多数计算机视觉任务提升性能的关键之一,包括图像恢复领域。
图像处理任务,例如恢复和增强,都是重要的计算机视觉任务,这些主要的目的在于从退化的输入上产生理想的输出。不同类型的退化可能需要不同的图像增强策略,例如去噪denoising、去模糊deblurring、超分辨super-resolution、去雾dehazing、低亮度增强low-light enhancement和其他的一些任务。随着精细构建的大规模训练集的增加,最近许多高性能方法基于精心设计的CNN架构,在许多任务上获得了卓越的效果。提升模型的架构设计是大多数计算机视觉任务提升性能的关键之一,包括图像恢复领域。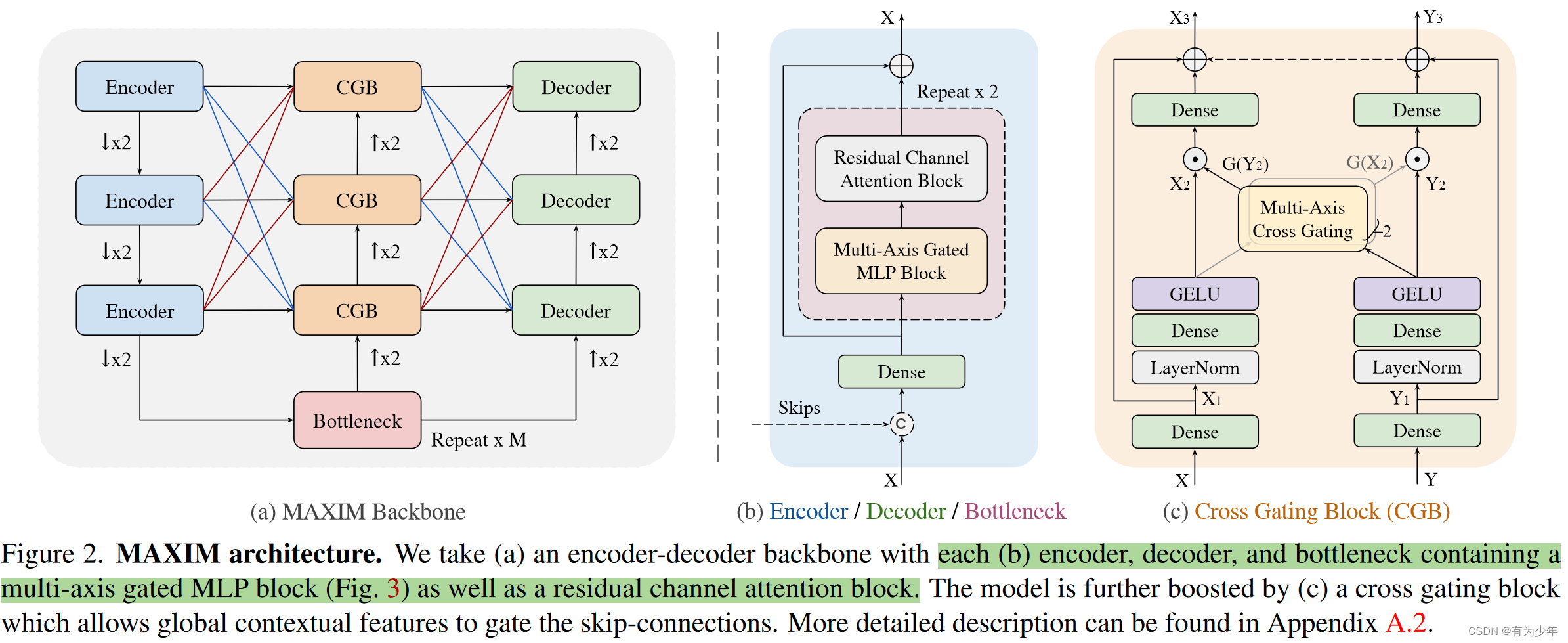 为此作者们提出了一种基于multi-axis多轴思想[HiT: Improved Transformer for High-Resolution GANs]改进的MLP结构,称为MAXIM,这可以作为一种图像处理任务中有效且灵活的通用视觉骨干架构。这是一种UNet分割的分层结构,通过使用空间门控MLP实现了长距离的交互。
为此作者们提出了一种基于multi-axis多轴思想[HiT: Improved Transformer for High-Resolution GANs]改进的MLP结构,称为MAXIM,这可以作为一种图像处理任务中有效且灵活的通用视觉骨干架构。这是一种UNet分割的分层结构,通过使用空间门控MLP实现了长距离的交互。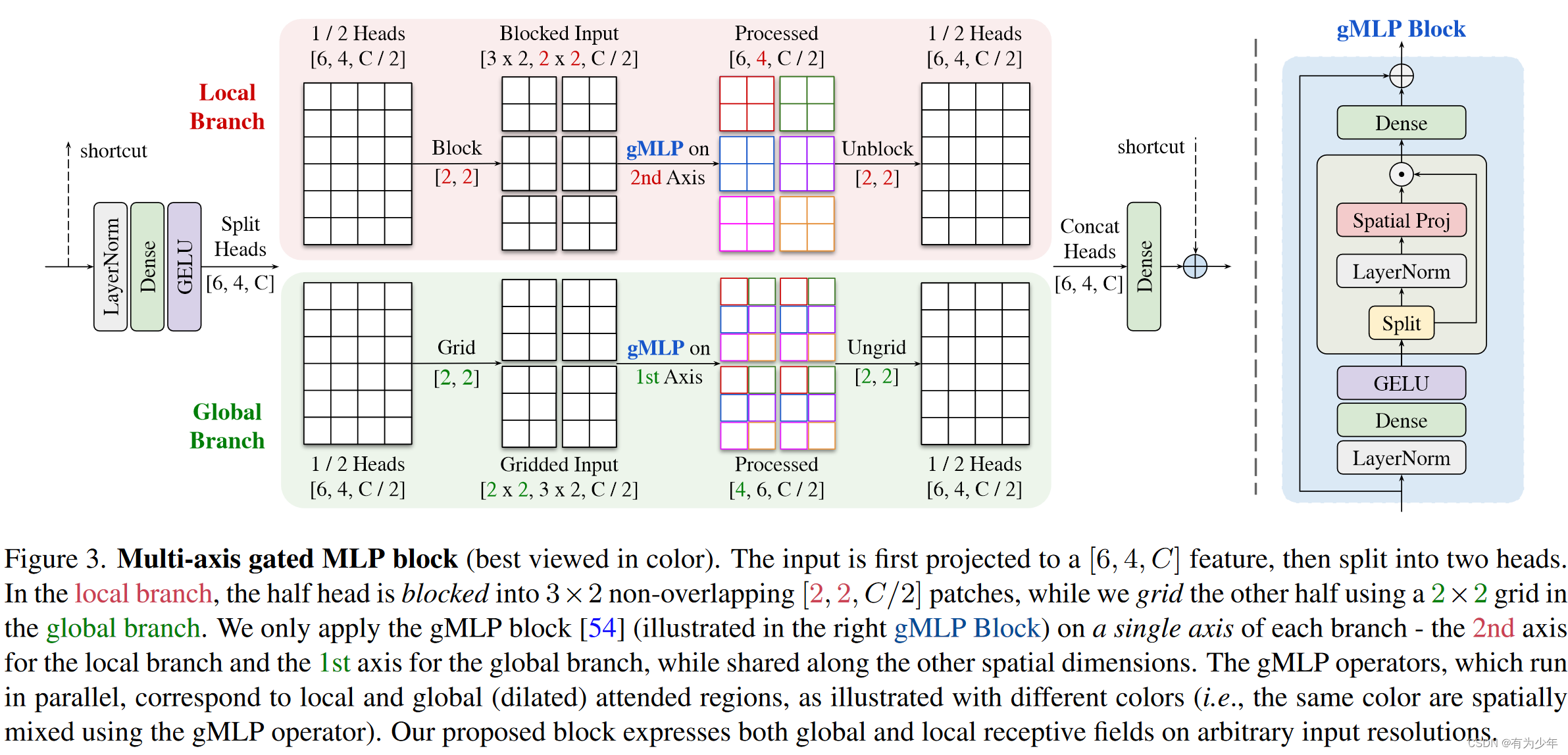 为此作者们针对图像处理任务,通过构建分离头形式的多轴门控MLP块(MAB),从而扩展了多轴的概念。
为此作者们针对图像处理任务,通过构建分离头形式的多轴门控MLP块(MAB),从而扩展了多轴的概念。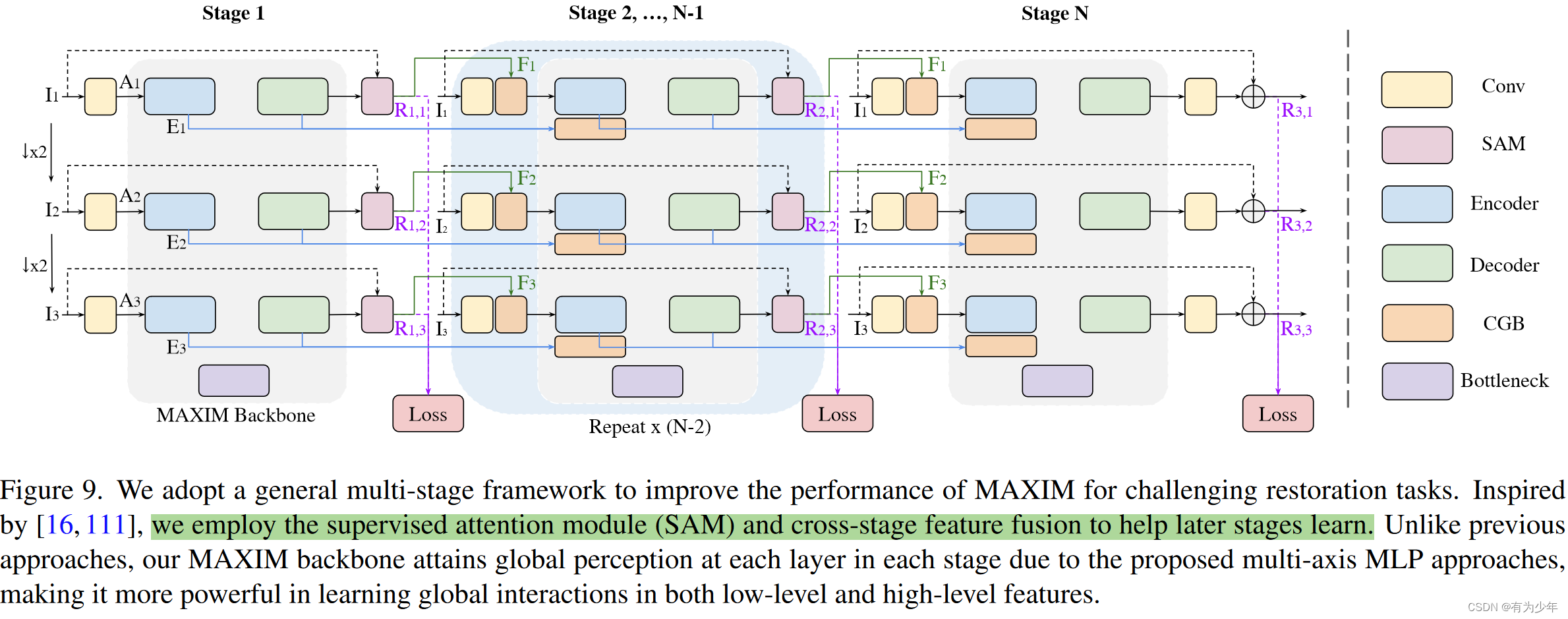 - 作者们一步采用了多阶段框架,因为与扩大模型宽度或高度相比,发现它更高效。
- 作者们一步采用了多阶段框架,因为与扩大模型宽度或高度相比,发现它更高效。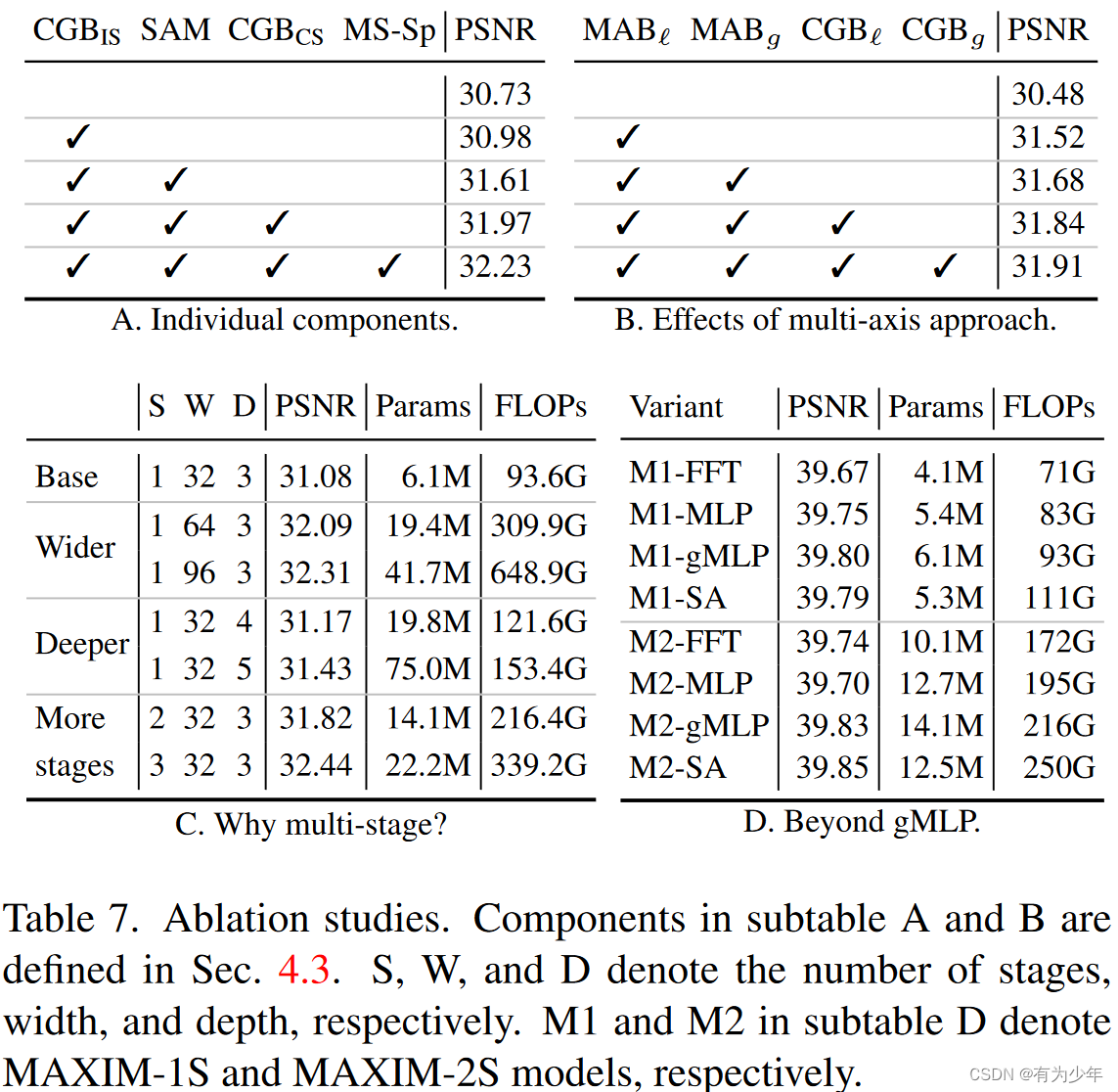
 实验中比较有趣的发现是,学习到的权重显示出了局部性和空间不变性。令人惊讶的是,global grid gMLP层也学会了执行“局部”操作(但在均匀的扩张网格上)。同一层中block gMLP和grid gMLP的空间权重,通常显示出相似或耦合的形状,这可能归因于多轴gMLP块中的并行分支设计。但是,作者们尚未观察到这些在不同阶段的滤波器如何变化的清晰趋势。
实验中比较有趣的发现是,学习到的权重显示出了局部性和空间不变性。令人惊讶的是,global grid gMLP层也学会了执行“局部”操作(但在均匀的扩张网格上)。同一层中block gMLP和grid gMLP的空间权重,通常显示出相似或耦合的形状,这可能归因于多轴gMLP块中的并行分支设计。但是,作者们尚未观察到这些在不同阶段的滤波器如何变化的清晰趋势。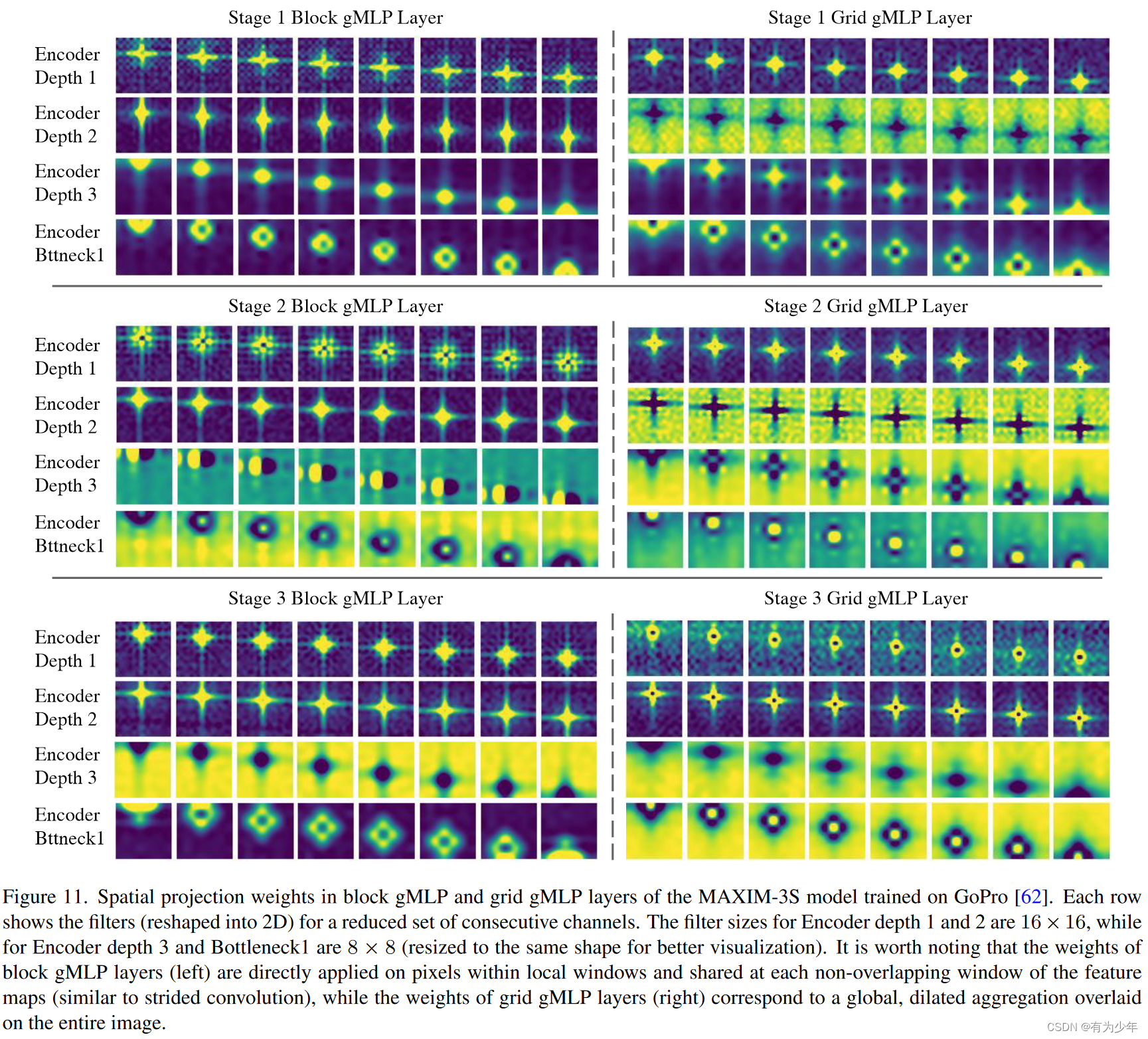
【本文地址】