R语言:断点回归(RD)学习手册(包含rdrobust命令详解、设计前提条件内生分组等显著性检验、全套标准动作) |
您所在的位置:网站首页 › r语言做回归分析的命令 › R语言:断点回归(RD)学习手册(包含rdrobust命令详解、设计前提条件内生分组等显著性检验、全套标准动作) |
R语言:断点回归(RD)学习手册(包含rdrobust命令详解、设计前提条件内生分组等显著性检验、全套标准动作)
|
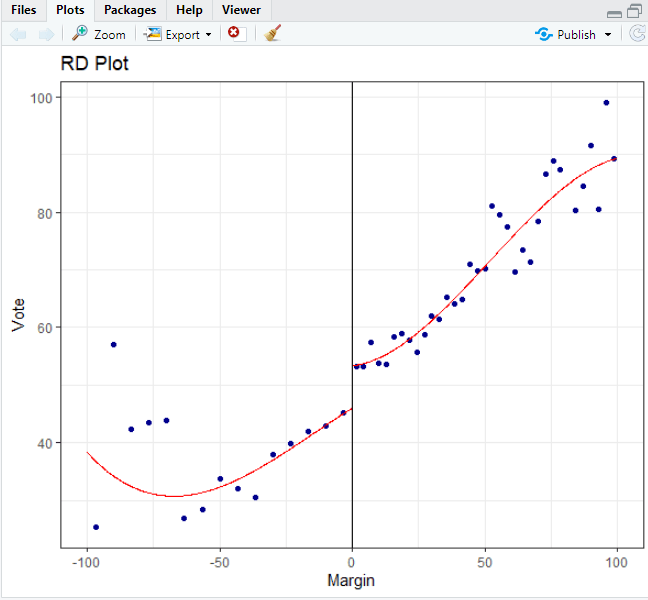
3、图形分析 画出结果变量与参考变量之间的关系图,如果是模糊断点,再画出原因变量与参考变量的关系图,呈现结果变量和原因变量在断点处行为,为断点回归设计提供理论支撑。 4、检验结果对不同带宽、不同多项式次数的稳健性 设置不同带宽,通过选择最优带宽,再检验并选择相对应的模型。stata断点回归命令有相关的操作选项。另外还有图形选择(在最优带宽处画线),可以考虑加协变量进行选择。 5、检验其他影响结果变量的因素(协变量),在断点处是否存在跳跃 检验协变量在断点处是否存在跳跃,若是存在跳跃,说明该协变量的条件密度函数在断点处不是连续的,需要剔除。若将存在跳跃的协变量剔除。则需要重新选择最优带宽再重新进行断点回归分析。 6、显著性检验 模型估计完成后,可以进行下列模型设定检验,以判断估计结果的稳健性(见赵西亮编著的《基本有用的计量经济学》) (1)协变量连续性检验,也称为伪结果检验( pseudo outcome)。以协变量 作为伪结果,利用与前面相同的方法,检验相应的RDD估计量是否显著,如果 显著说明这些协变量不符合连续性假设,上文的RDD估计量可能存在问题。 (2)参考变量分布连续性检验,如果参考变量分布连续,意味着在断点处个体没有精确操纵参考变量的能力,局部随机化假设成立,从而保证断点附近左右样本能够代表断点处的总体。(此处与检验内生分组一致) (3)伪断点检验( pseudo cutoff point)。在参考变量的其他位置,比如断点 左右两侧中点位置作为伪断点,利用同样的方法估计RDD估计量,我们知道在 伪断点干预效应为零,如果发现伪断点的RDD估计量不为零,则说明我们的RDD设计可能有问题,可能混杂了其他未观测因素的影响,得到的因果效应可能是由其他未观测混杂的跳跃造成的,而不完全是干预的影响 (4)带宽选择的敏感性检验。选择不同的带宽对RDD估计量进行重新估 计,检验估计结果是否有较大的变量,如果差异较大,尤其是影响方向有变化说明RDD设计可能有问题。 上述显著性检验其实在前面进行分析时候已经部分有所提及需要进行检验的。 二 、断点回归命令 在Stata中,断点回归的基本命令是rd,另外,还有一些其他命令,例如rdrobust、rdlocrand、rddensity等等。 本文主要介绍在R语言中的rdrobust。rdrobust有两个配套命令:rdbwselect用于带宽选择,rdplot用于RD绘图(详细信息请参见Calonico、Cattaneo和Titiunik [2015a])。 1、rdbwselect 下载安装方法为: install.packages( 'rdrobust') library(rdrobust) rdrobust语法格式为: rdbwselect(y, x, c = NULL, fuzzy = NULL, deriv = NULL, p = NULL, q = NULL, covs = NULL, covs_drop = TRUE, kernel = "tri", weights = NULL, bwselect = "mserd", vce = "nn", cluster = NULL, nnmatch = 3, scaleregul = 1, sharpbw = FALSE, all = NULL, subset = NULL, masspoints = "adjust", bwcheck = NULL, bwrestrict = TRUE, stdvars = FALSE) 选项含义为: y表示因变量。 x表示驱动变量(又称使动变量)。 c指定RD中断点位置;默认值是c = 0。 fuzzy指定用于实现模糊RD估计的处理状态变量,默认是Sharp RD设计,因此不使用此选项。 cov表示指定用于估计和推断的附加协变量。 kernel是用来构造局部多项式估计器的核函数。选项有三角形(默认选项)、epanechnikov和uniform。 weights是用于估计过程的可选加权的变量。单位权重乘以核函数。 bwselect指定要使用的带宽选择过程。 2、rdrobust 语法含义为: rdrobust(y, x, c = NULL, fuzzy = NULL, deriv = NULL, p = NULL, q = NULL, h = NULL, b = NULL, rho = NULL, covs = NULL, covs_drop = TRUE, kernel = "tri", weights = NULL, bwselect = "mserd", vce = "nn", cluster = NULL, nnmatch = 3, level = 95, scalepar = 1, scaleregul = 1, sharpbw = FALSE, all = NULL, subset = NULL, masspoints = "adjust", bwcheck = NULL, bwrestrict = TRUE, stdvars = FALSE) 选项含义为: y表示因变量。 x表示驱动变量(又称使动变量)。 c指定RD中断点位置;默认值是c = 0。 fuzzy指定用于实现模糊RD估计的处理状态变量,默认是Sharp RD设计,因此不使用此选项。 covs表示指定用于估计和推断的附加协变量。 p指定用于构造点估计器的局部多项式的阶数;默认值是p = 1(本地线性回归)。 q指定用于构造偏差校正的局部多项式的顺序;默认值是q = 2(局部二次回归)。 h指定用于构造RD点估计器的主要带宽。如果没有指定,带宽h将由同伴命令rdbwselect计算。如果指定了两个带宽,第一个带宽用于低于截止值的数据,第二个带宽用于高于截止值的数据。 b指定用于构造偏差校正估计器的偏差带宽。如果没有指定,带宽b将由同伴命令rdbwselect计算。如果指定了两个带宽,第一个带宽用于低于截止值的数据,第二个带宽用于高于截止值的数据。 3、rdplot 语法含义为 rdplot(y, x, c = 0, p = 4, nbins = NULL, binselect = "esmv", scale = NULL, kernel = "uni", weights = NULL, h = NULL, covs = NULL, covs_eval = 0, covs_drop = TRUE, support = NULL, subset = NULL, hide = FALSE, ci = NULL, shade = FALSE, title = NULL, x.label = NULL, y.label = NULL, x.lim = NULL, y.lim = NULL, col.dots = NULL, col.lines = NULL) 选项含义为 rdplot函数可用于RD结果的可视化,其语法与rdrobust或者rdrobust相同 y表示因变量。 x表示驱动变量(又称使动变量)。 c指定RD中断点位置;默认值是c = 0。 p指定用于近似控制单元和处理单元的总体条件平均函数的全局多项式的阶数;默认值是p = 4。 binselect指定选择容器数量的过程。 三、案例 rdrobust采用Calonico, Cattaneo和Titiunik (2014a)、Calonico, Cattaneo和Farrell(2018)、Calonico, Cattaneo, Farrell和Titiunik(2019)和Calonico, Cattaneo和Farrell(2020)开发的鲁棒偏差校正置信区间和推理程序,实现了局部多项式回归不连续(RD)点估计。它还计算可供选择的估计和推理程序,在文献中。 配套命令有:rdbwselect用于数据驱动带宽选择,rdplot用于数据驱动RD图(详见Calonico, Cattaneo and Titiunik (2015a))。 这个命令的详细介绍在Calonico, Cattaneo和Titiunik (2015b)和Calonico, Cattaneo, Farrell和Titiunik(2017)中给出。配套的Stata包在Calonico, Cattaneo和Titiunik (2014b)中有描述。 有关更多细节,以及用于分析RD设计的相关Stata和R包,请访问https://sites.google.com/site/rdpackages/ Cattaneo, Frandsen和Titiunik构建的数据集(2015),其中包括1914-2010年期间美国参议院在任优势的衡量。 该数据包含以下两个变量的1390个观察值的数据框架。 其包含两个变量vote和margin,vote表示某次选举民主党在州参议院的席位占比,margin表示上次选举中获得相同参议院席位的边际收益,其中大于0表示民主党胜出,反之则为失败。 将vote作为被解释变量,margin作为解释变量,即可研究民主党赢得参议院席位对于在下次选举中获得相同席位的影响。具体操作代码如下 1导入数据 data(rdrobust_RDsenate) 2最优带宽 rdbwselect(y = rdrobust_RDsenate $vote, x = rdrobust_RDsenate $margin, all = TRUE) summary 结果为: > rdbwselect(y = rdrobust_RDsenate $vote, x = rdrobust_RDsenate $margin, all = TRUE) Call: rdbwselect Number of Obs. 1297 BW typeAll Kernel Triangular VCE method NN Number of Obs. 595 702 Order est. (p) 1 1 Order bias (q) 2 2 Unique Obs. 595 665 ======================================================= BW est. (h) BW bias (b) Left of c Right of c Left of c Right of c ======================================================= mserd 17.754 17.754 28.028 28.028 msetwo 16.170 18.126 27.104 29.344 msesum 18.365 18.365 31.319 31.319 msecomb1 17.754 17.754 28.028 28.028 msecomb2 17.754 18.126 28.028 29.344 cerrd 12.407 12.407 28.028 28.028 certwo 11.299 12.667 27.104 29.344 cersum 12.834 12.834 31.319 31.319 cercomb1 12.407 12.407 28.028 28.028 cercomb2 12.407 12.667 28.028 29.344 ======================================================= 3 参数估计 rdrobust(y = rdrobust_RDsenate $vote, x = rdrobust_RDsenate $margin) %>% summary Call: rdrobust Number of Obs. 1297 BW typemserd Kernel Triangular VCE method NN Number of Obs. 595 702 Eff. Number of Obs. 360 323 Order est. (p) 1 1 Order bias (q) 2 2 BW est. (h) 17.754 17.754 BW bias (b) 28.028 28.028 rho (h/b) 0.633 0.633 Unique Obs. 595 665 ============================================================================= Method Coef. Std. Err. z P>|z| [ 95% C.I. ] ============================================================================= Conventional 7.414 1.459 5.083 0.000 [4.555 , 10.273] Bias-Corrected 7.507 1.459 5.146 0.000 [4.647 , 10.366] Robust 7.507 1.741 4.311 0.000 [4.094 , 10.919] ============================================================================= 4 绘图 rdplot(rdrobust_RDsenate $vote, rdrobust_RDsenate $margin, p = 3, x.label = 'Margin', y.label = 'Vote')
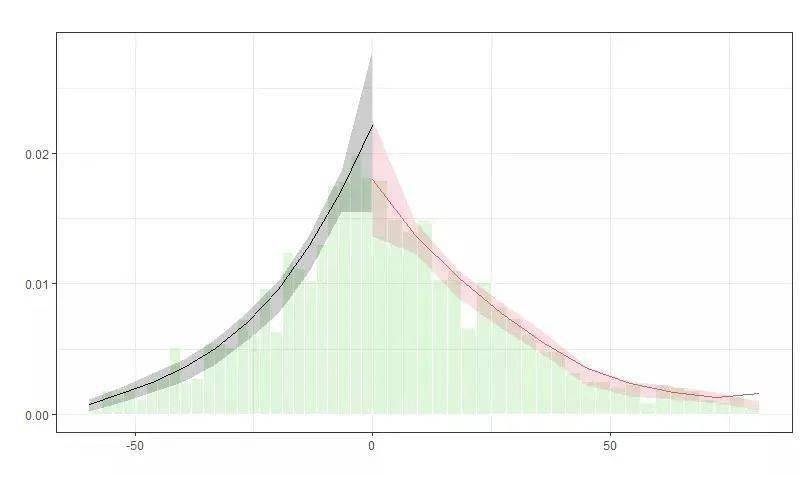
四、稳健性检验 下面我们结合rdrobust这个命令来介绍如何进行断点回归的一个稳健性检验。 也就是rd的有效性检验,首先进行RD断点回归设计的时候呢,需要满足一些先决条件。 1、局部平滑性假设 除了结果变量,其他协变量,在断点处也是没有出现跳跃性的这样一个现象,满足平滑性,也就是连续性,我们可以假设将协变量作为结果变量,利用rdrobust函数来进行检验,协变量应该在统计学上是不显著的。 上述假设也称为协变量连续性检验,也称为伪结果检验( pseudo outcome)。以协变量 作为伪结果,利用与前面相同的方法,检验相应的RDD估计量是否显著,如果 显著说明这些协变量不符合连续性假设,上文的RDD估计量可能存在问题。 具体代码如下 rdrobust(y = other variables, x = assignment variable) %>% summary 2、驱动变量的有效性 也就是参考变量分布连续性检验,如果参考变量分布连续,意味着在断点处个体没有精确操纵参考变量的能力,局部随机化假设成立,从而保证断点附近左右样本能够代表断点处的总体。(此处与检验内生分组一致) 该假设可通过rddensity中的对应函数进行McCrary检验,具体代码如下 library(rdrobust) library(rddensity) data(rdrobust_RDsenate) rdplotdensity(rddensity(rdrobust_RDsenate $margin), X = rdrobust_RDsenate $margin)
3、RDD中的稳健性检验 对于RDD中的稳健性检验,一般主要包括对伪断点检验、样本选择和带宽选择进行分析。 3.1、伪断点检验 伪断点检验( pseudo cutoff point)。在参考变量的其他位置,比如断点 左右两侧中点位置作为伪断点,利用同样的方法估计RDD估计量,我们知道在 伪断点干预效应为零,如果发现伪断点的RDD估计量不为零,则说明我们的RDD设计可能有问题,可能混杂了其他未观测因素的影响,得到的因果效应可能是由其他未观测混杂的跳跃造成的,而不完全是干预的影响 具体可使用rdrobust进行检验,预期结果为系数不再显著。具体代码如下 ## 除c以外的参数应当与benchmark一致 sen_cut_1 |
【本文地址】
今日新闻 |
推荐新闻 |