YOLOv8的多分类模型如何计算准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1 |
您所在的位置:网站首页 › cnn分类准确率很低吗 › YOLOv8的多分类模型如何计算准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1 |
YOLOv8的多分类模型如何计算准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1
|
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐------》 一、AI应用软件开发实战专栏【链接】 项目名称项目名称1.【人脸识别与管理系统开发】2.【车牌识别与自动收费管理系统开发】3.【手势识别系统开发】4.【人脸面部活体检测系统开发】5.【图片风格快速迁移软件开发】6.【人脸表表情识别系统】7.【YOLOv8多目标识别与自动标注软件开发】8.【基于YOLOv8深度学习的行人跌倒检测系统】9.【基于YOLOv8深度学习的PCB板缺陷检测系统】10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】11.【基于YOLOv8深度学习的安全帽目标检测系统】12.【基于YOLOv8深度学习的120种犬类检测与识别系统】13.【基于YOLOv8深度学习的路面坑洞检测系统】14.【基于YOLOv8深度学习的火焰烟雾检测系统】15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】16.【基于YOLOv8深度学习的舰船目标分类检测系统】17.【基于YOLOv8深度学习的西红柿成熟度检测系统】18.【基于YOLOv8深度学习的血细胞检测与计数系统】19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】22.【基于YOLOv8深度学习的路面标志线检测与识别系统】23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】27.【基于YOLOv8深度学习的人脸面部表情识别系统】28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】29.【基于YOLOv8深度学习的智能肺炎诊断系统】30.【基于YOLOv8深度学习的葡萄簇目标检测系统】31.【基于YOLOv8深度学习的100种中草药智能识别系统】32.【基于YOLOv8深度学习的102种花卉智能识别系统】33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~ 三、深度学习【Pytorch】专栏【链接】 四、【Stable Diffusion绘画系列】专栏【链接】 五、YOLOv8改进专栏【链接】,持续更新中~~ 六、YOLO性能对比专栏【链接】,持续更新中~ 《------正文------》
如下图是YOLOv8训练的多分类结果文件,只给出了混淆矩阵与TOP1与TOP5的准确率曲线。并没有给出最终各个类别的准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1-Score等评估参数。因此我们需要额外计算每个类别的准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1-Score评估参数。以及这些参数平均值。本文的计算方式同样可以适用于其他分类模型的评估参数计算。 有了这些参数之后可以更加方便的进行不同分类模型的参数对比,或者模型改进前后的参数对比。 因为我们参数计算需要使用到机器学习库sklearn,因此我们需要先安装该库,命令如下: pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple 2.计算每个分类的评估参数我的验证集目录如下,每个类别里面放置的是该类别对应的图片: 运行上述代码后,打印结果如下: 上面已经给出了所有的评估结果,如果我们只想单独计算的平均的准确率、精确率、F1分数和召回率,代码如下: # 计算并打印一系列评估指标,包括准确率、精确率、F1分数和召回率 # 参数: # real_labels: 真实标签列表,表示样本的真实类别 # pre_labels: 预测标签列表,表示模型预测的样本类别 print('单独计算的准确率、精确率、F1分数和召回率:') # 1. accuracy_score: 准确率,表示预测正确的样本占总样本的比例 print('accuracy_score:',accuracy_score(real_labels, pre_labels)) # 2. precision_score: 精确率,表示预测为正类且实际为正类的样本占预测为正类样本的比例 print('precision_score:',precision_score(real_labels, pre_labels, average='macro')) # 3. f1_score: F1分数,是精确率和召回率的调和平均值,综合评估精确度和召回率 print('f1_score:',f1_score(real_labels, pre_labels, average='macro')) # 4. recall_score: 召回率,表示预测为正类且实际为正类的样本占实际正类样本的比例 print('recall_score:',recall_score(real_labels, pre_labels, average='macro'))运行上述代码后,打印结果如下: 好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~ 关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流! |

 详细代码如下,其中real_labels 和pre_labels 分别代表真实标签与预测标签。
详细代码如下,其中real_labels 和pre_labels 分别代表真实标签与预测标签。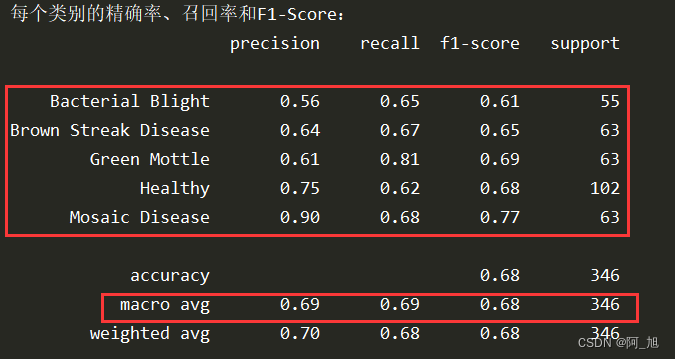 分别计算出了每个类别的准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1-Score参数,并且给出了平均参数,就是macro avg那一行。
分别计算出了每个类别的准确率(Accuracy)、精确率(Precision)、召回率(recall)和F1-Score参数,并且给出了平均参数,就是macro avg那一行。 计算出这些模型评估结果之后可以更加方便的进行不同分类模型的性能对比,或者模型改进前后的性能对比。 如果文章对你有帮助,麻烦动动你的小手,给点个赞,鼓励一下吧,谢谢~~~
计算出这些模型评估结果之后可以更加方便的进行不同分类模型的性能对比,或者模型改进前后的性能对比。 如果文章对你有帮助,麻烦动动你的小手,给点个赞,鼓励一下吧,谢谢~~~【本文地址】
今日新闻 |
推荐新闻 |