用于图像分类的经典的卷积神经网络CNN |
您所在的位置:网站首页 › cnn分类算法 › 用于图像分类的经典的卷积神经网络CNN |
用于图像分类的经典的卷积神经网络CNN
|
文章目录
概览1.计算机视觉简介:2.图像分类
一、LeNet-51.模型架构2.模型简介3.模型特点
二、AlexNet1.网络架构2.模型介绍3.模型特点
三、VGGNet1.模型架构2.模型简介3.模型特点
四、GoogLeNet1. 网络架构2、模型解析3、模型特点
五、ResNet(深度残差网络)1、模型解析2、模型特点
六、DenseNet1.模型架构2.模型特点
在上一篇详细讲解了卷积神经网络的基本模块之后,对卷积的神经网络应该有了一个清晰的认识。后边的卷积神经网络,都是基于这些模块不断优化、改进,但是并未真正跳出这个框架。那么,这一章内容就讲一下用于图像分类的卷积神经网络的发展历程。 概览 1.计算机视觉简介:计算机视觉是当前最热门的研究之一,是一门多学科交叉的研究,涵盖计算机科学(图形学、算法、理论研究等)、数学(信息检索、机器学习)、工程(机器人、NLP等)、生物学(神经系统科学)和心理学(认知科学)。计算机视觉中主要有五大内容,分别为图像分类、目标检测、目标跟踪、语义分割以及物体分割。针对每项内容,都有自己的基本概念及相应的适用于自己的一套典型方法。 今天要讲的是基于图像分类的经典的卷积神经网络的发展历程。 2.图像分类
完整的图像分类步骤一般形式如下: 1.首先,输入一组训练图像数据集; 2.然后,使用该训练集训练一个分类器,该分类器能够学习每个类别的特征; 3.最后,使用测试集来评估分类器的性能,即将预测出的结果与真实类别标记进行比较; 大多数图像分类算法都是在ImageNet数据集上训练的,该数据集由120万张的图像组成,涵盖1000个类别,该数据集也可以称作改变人工智能和世界的数据集。ImagNet 数据集让人们意识到,构建优良数据集的工作是 AI 研究的核心,数据和算法一样至关重要。为此,世界组织也举办了针对该数据集的挑战赛——ImageNet挑战赛。 而本文所讲解的适用于图像分类的经典的卷积神经网络,也是历年来的ImageNet的冠军。 本文将从经典的LeNet-5网络讲起,到了2012年,AlexNet一举夺得首届ImageNet的冠军。之后,有很多基于CNN的算法也在ImageNet上取得了特别好的成绩,比如ZFNet(2013)、GoogleNet(2014)、VGGNet(2014)、ResNet(2015)以及DenseNet(2016)等。 一、LeNet-5这个是n多年前就有的一个CNN的经典结构,卷积神经网络的开山之作,主要是用于手写字体的识别,也是刚入门需要学习熟悉的一个网络。网络虽然简单,但是麻雀虽小五脏俱全,卷积层、池化层、全链接层一直沿用至今 1.模型架构
S2和S4两个池化层使用的window大小均为2×2,这里的池化有两种。 F6是一个有84个神经元的全连接层。 2.模型简介用下图所示的模型,更加直观: LeNet有一个很有趣的地方,就是S2层与C3层的连接方式,在原文里,这个方式称为“Locally Connect” AlexNet(论文原文下载)在2012年的ImageNet竞赛上以,比以往最低错误率低10个百分点的成绩夺冠。在测试集上Top-1和Top-5的错误率为37.5%和17.0%。
网络的输入为150,528(224x224x3)维,各层的神经元数量为: 253,440=>186,624=>64,896=>64,896=>43,264=>4096=>4096=>1000(ImageNet有1000个类) 举个例子,计算一个186,624是怎么来的:27x27x256=186,624 举个例子,怎么计算feature map尺寸: AlexNet包含了8个学习层——5个卷积层(卷积+非线性激活+Max Pooling)和3个全连接层,最后一层是1000维的softmax层。 输入层:图像大小为 227×227×3,其中 3 表示输入图像的 channel 数(R,G,B)为 3。卷积层:filter 大小 11×11,filter 个数 96,卷积步长 s=4。(filter 大小只列出了宽和高,filter矩阵的 channel 数和输入图片的 channel 数一样,在这里没有列出)池化层:max pooling,filter 大小 3×3,步长 s=2。卷积层:filter 大小 5×5,filter 个数 256,步长 s=1,padding 使用 same convolution,即使得卷积层输出图像和输入图像在宽和高上保持不变。池化层:max pooling,filter 大小 3×3,步长 s=2。卷积层:filter 大小 3×3,filter 个数 384,步长 s=1,padding 使用 same convolution。卷积层:filter 大小 3×3,filter 个数 384,步长 s=1,padding 使用 same convolution。卷积层:filter 大小 3×3,filter 个数 256,步长 s=1,padding 使用 same convolution。池化层:max pooling,filter 大小 3×3,步长 s=2;池化操作结束后,将大小为 6×6×256 的输出矩阵 flatten 成一个 9216 维的向量。全连接层:neuron 数量为 4096。全连接层:neuron 数量为 4096。全连接层,输出层:softmax 激活函数,neuron 数量为 1000,代表 1000 个类别。
大约 60million 个参数; 使用 ReLU 作为激活函数,缓解了Sigmoid在网络较深时的梯度弥散问题。; 提出了局部响应归一化层(Local Response Normalization Layer),LRN层只存在于第一层卷积层和第二层卷积层的激活函数后面,引入这一层的主要目的,主要是为了防止过拟合,增加模型的泛化能力。具体方法是在某一确定位置(x,y)将前后各2/n个feature map求和作为下一层的输入。; 采用了重叠池化(Overlapping Pooling):特征的丰富性。通过设置s |
 官方定义为:给定一组图像集,其中每张图像都被标记了对应的类别。之后为一组新的测试图像集预测其标签类别,并测量预测准确性。
官方定义为:给定一组图像集,其中每张图像都被标记了对应的类别。之后为一组新的测试图像集预测其标签类别,并测量预测准确性。 层数很浅,并且kernel大小单一,C1、C3、C5三个卷积层使用的kernel大小全部都是5×5。C5的feature map大小为1×1是因为,S4的feature map大小为5×5而kernel大小与其相同,所以卷积的结果大小是 1×1。
层数很浅,并且kernel大小单一,C1、C3、C5三个卷积层使用的kernel大小全部都是5×5。C5的feature map大小为1×1是因为,S4的feature map大小为5×5而kernel大小与其相同,所以卷积的结果大小是 1×1。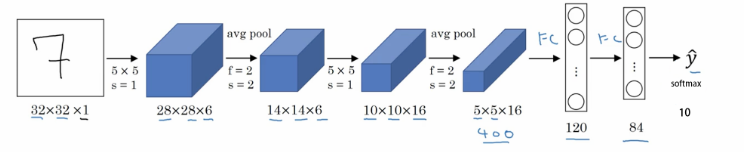
 规定左上角为(0,0),右下角为(15,5),那么在(n,m)位置的“X”表示S2层的第m个feature map与C3层的第n个kernel进行卷积操作。例如说,C3层的第0个kernel只与S2层的前三个feature map有连接,与其余三个feature map是没有连接的;C3层的第15个kernel与S2层的所有feature map都有连接。
规定左上角为(0,0),右下角为(15,5),那么在(n,m)位置的“X”表示S2层的第m个feature map与C3层的第n个kernel进行卷积操作。例如说,C3层的第0个kernel只与S2层的前三个feature map有连接,与其余三个feature map是没有连接的;C3层的第15个kernel与S2层的所有feature map都有连接。

 注:上图的结构简图是从下往上看。
注:上图的结构简图是从下往上看。 224为输入大小,11为kernel大小,4为stride。
224为输入大小,11为kernel大小,4为stride。


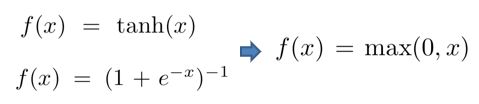

【本文地址】
今日新闻 |
推荐新闻 |