06 |
您所在的位置:网站首页 › cmu15-445 › 06 |
06
|
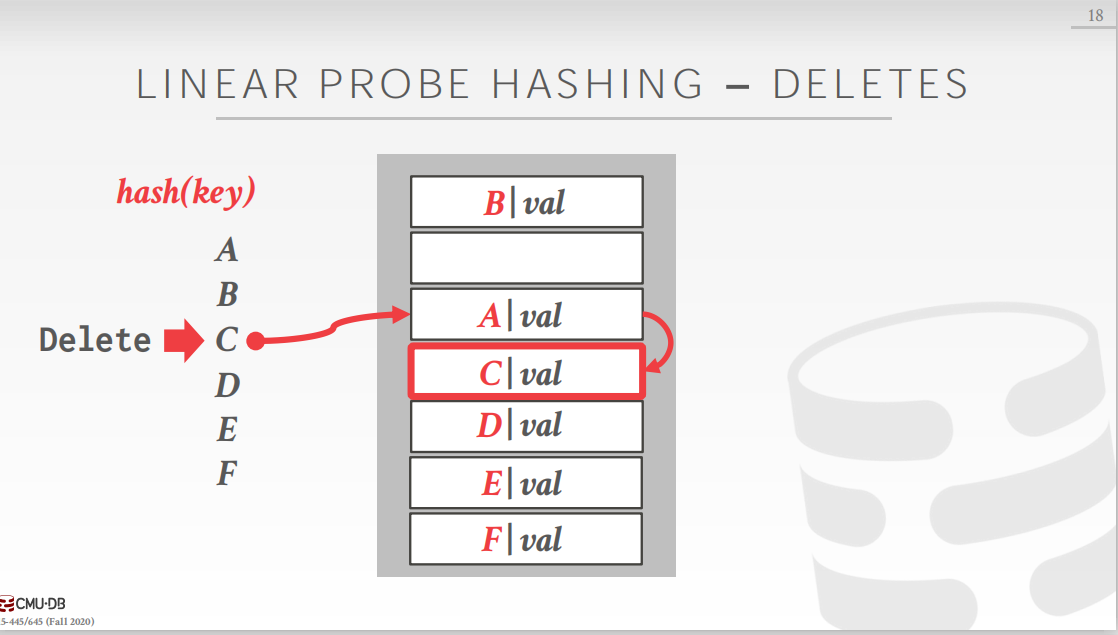
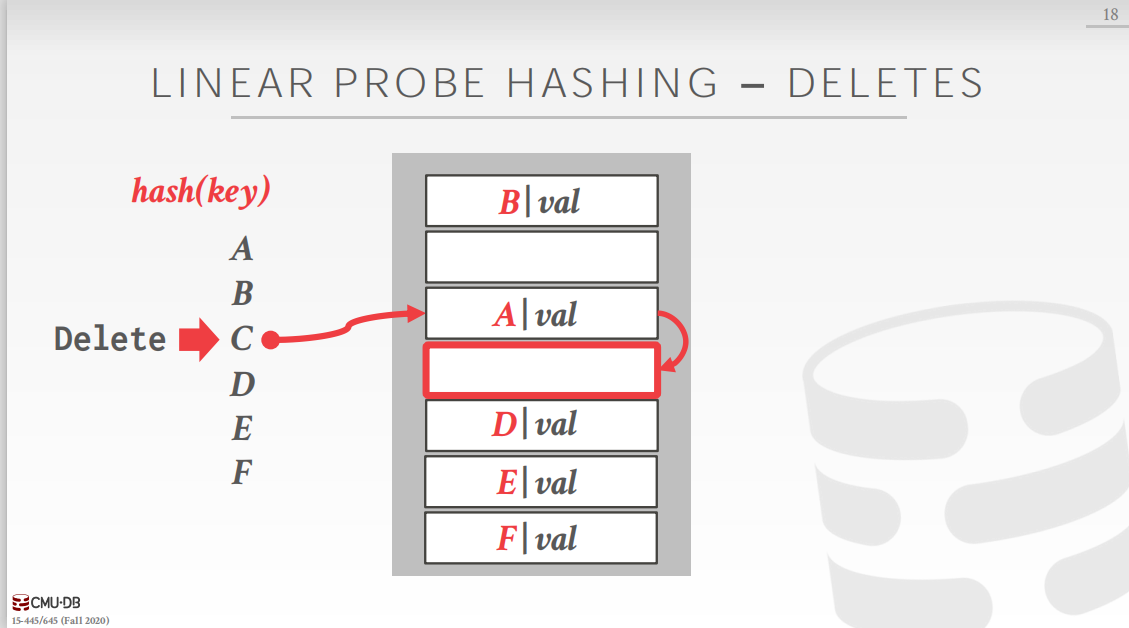
本文根据CMU15-445课程内容编写,因为数据库术语较多,为避免翻译问题带来的理解偏差,部分术语使用英语表达。 1. 数据结构DBMS需要使用各种各样的数据结构来维护系统的内部数据。比如: 内部元信息(Internal Meta-Data):这些数据记录了数据库的一些关键信息和系统的状态。比如,页表,页目录等。核心数据存储(Core Data Storage):用来保存数据库中的元组临时数据结构(Temporary Data Structures):DBMS在执行一些查询时,会构建一些临时的数据结构来加快执行速度。表索引(Table Indices):表的辅助数据结构,帮助我们更快地找到表中的某些特定数据。当我们在DBMS中实现数据结构时,有两点需要特别注意: 数据组织(Data organization):我们需要设计数据在内存中的布局,以及数据结构中需要保存哪些数据来提高访问效率。并发(Concurrency):我们在设计数据结构时需要考虑到多个线程同时访问数据结构的情况。 2. 哈希表哈希表是一种抽象数据类型,它使用哈希函数将数据从键空间(key space)映射到值空间(value space)。在哈希表上做增删改查等操作的平均时间复杂度是 O ( 1 ) O(1) O(1)(最差的情况是 O ( n ) O(n) O(n)),空间复杂度是 O ( n ) O(n) O(n)。值得注意的是,即使哈希操作的平均时间复杂度已经达到了 O ( 1 ) O(1) O(1),在这个常数级别上的优化依然是很有价值的。 哈希表的实现主要包括两部分: 哈希函数(Hashing Function):哈希函数是一个从范围较大的键空间(key space)到范围较小的值空间(value space)的映射。通常来说,对于给定的键,哈希函数计算出一个确定的数值,这个数值指向数组的位置就是存储对应值的地方。在设计哈希函数的时候,通常需要在执行速度和碰撞率之间做折中。过于复杂的哈希函数可能碰撞率比较低,但是执行速度可能会比较慢;过于简单的哈希函数可能执行速度比较快,但是碰撞发生的概率可能比较高。哈希方案(Hashing Scheme):哈希方式是处理哈希之后的碰撞问题,碰撞问题是不可避免的。通常来说,对于比较大的哈希表,碰撞发生的概率是比较低的,所以在碰撞发生时不需要执行太多复杂的逻辑。因此我们通常也需要在哈希表的逻辑复杂度和占用空间之间做一个折中。 3. 哈希函数一般来说,哈希函数以键key作为输入,输出一个确定的整数值(在这里,确定的意思是只要哈希函数和哈希函数的种子不变,每次输入同一个键key,输出的都是同一个整数)。 对于DBMS来说,使用加密的哈希函数是没有必要的,因为大多数时候,哈希函数仅仅在DBMS内部使用,并不会暴露给外部系统,因此,DBMS没有必要保护键key的内容。我们仅仅需要考虑哈希函数的运行速度和碰撞率。 4. 静态的哈希方案(Static Hashing Schemes)静态的哈希方案要求事先知道我们大约需要对多少keys进行哈希。在静态哈希方案中,哈希表的大小是固定的。如果哈希表的空间用完,那么我们需要重新构建一个更大的哈希表,这是一个非常耗时的操作。新的哈希表的大小一般是原来的两倍。但是在现实中,我们事先通常不知道需要存储的数据有多少。 4.1 线性探测哈希(Linear probe hashing)这是最普遍的哈希方案,一般来说也是最快的。线性探测哈希方式首先申请一大块内存作为环形数组。 插入数据时,如果插入位置已经被占用,那么就从插入位置向下查找,直到找到一个空位并将数据插入到这个空位中。如果一直扫描到数组尾部都没有空位,那么就从数组头部开始向下扫描(我们申请的是逻辑上的环形数组)。如果整个哈希表都满了,那么就需要重新申请更大的内容,然后将所有数据重新插入到新的哈希表中。 查找数据时,计算key对应的哈希值,查找数组对应位置的key是否和所需的key相同,如果不同,那么向下扫描直到找到所需的键值对(查找成功)或者遇到一个空位(查找失败)。 删除数据时,如果仅仅将对应位置的键值对抹去可能会导致该键值对下方的键值对在之后的查找中失败。举个例子,首先看图1,A,C,D经过哈希之后的位置分别是数组的第3,3,4位,经过线性探测之后,C插入到第4格,D插入到第5格。现在如果删除C,就会出现图2的情况,这时,如果我们查找D,哈希值为4,查找对应位置是没有数据,此时就会认定D不存在于哈希表中(发生错误)。
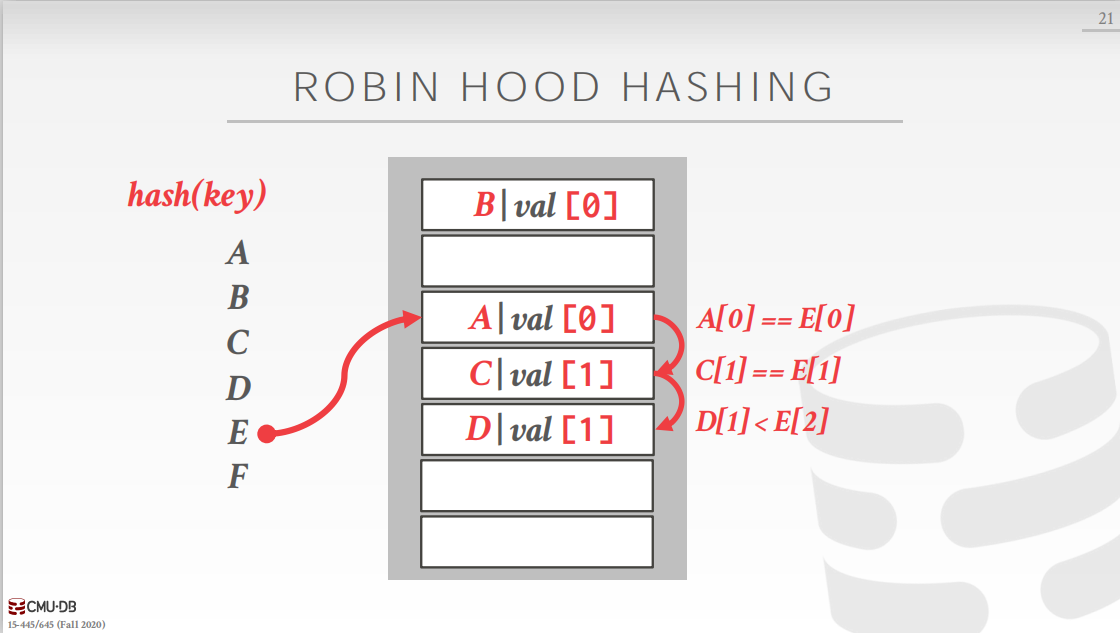
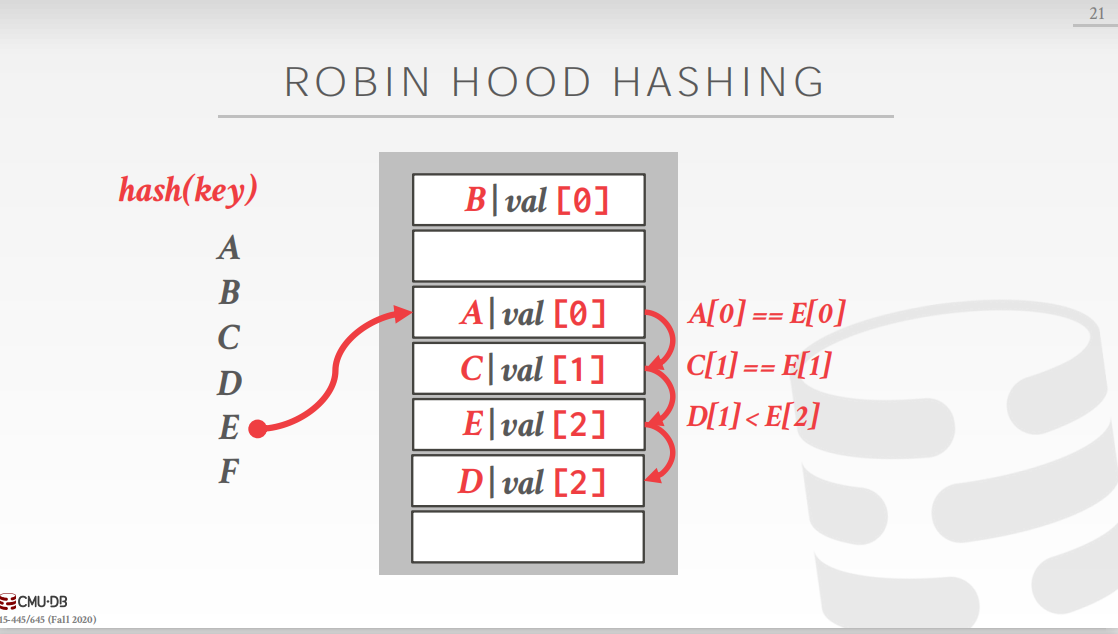
为了解决这个问题,在删除时有两种处理方式: (常用)在删除位置设置墓碑标识,标识这个位置已经被占用,但是并没有保存数据。在查找的时候如果发现墓碑符号就正常向下扫描,插入时发现墓碑符号就可以插入。(不常用)在删除键值对时,移动当前位置之下的键值对。这个方法相对复杂,计算当前位置之下的键值对哈希值,并和其实际位置做比较,以此决定是否移动。当键key不唯一时,即有存在多个键值对,其键key相同,但是值不同。这种情况有有两种处理方式: 链表:键值对中的值不再保存实际的值,而是保存一个指针。该指针指向一个链表,在链表中保存该键对应的多个值。冗余keys:直接在哈希表中保存多个键相同的键值对,线性探测哈希的规则在这种情况下依旧可以正常工作且不会出错。 4.2 罗宾汉哈希(Robin Hood Hashing)线性探测哈希的变种,罗宾汉是一个“劫富济贫”的强盗,在哈希表,也有这样一个“劫富济贫”的操作。首先我们定义“贫富”的概念,如果一个键值对的实际位置和其理想位置(经过一次哈希函数计算得到的位置)相对比较远,那么就是相对“贫穷”的;反之,就是相对“富有”的。 那么“劫富济贫”的操作具体是什么呢?首先,每个键值对都需要记录自己的“贫富”,也就是自己离理想位置的距离。这样在插入的过程中,如果发现某一个位置已经被占用,那么就比较当前插入键值对和占用该位置的键值对的贫富程度,如果当前插入的键值对比较贫穷,也就是离自己的理想位置更远,那么就替换占用该位置的键值对。 具体的说看下图:A,C,D已经占用了3个空间,此时,E计算的哈希值为3,但是插入位置已经被A占据,那么就比较其贫富程度,发现,A和E此时一样富有,不做处理,E继续向下寻找,离自己的理想位置距离加1。查找到C,C和E此时里自己的理想位置距离都是1,不做处理,继续向下寻找,距离加1。查找到D,发现D离自己的理想位置距离更近,即D此时比E“富有”,那么就让E替换D,然后带着D继续向下寻找。D向下查找发现一个空位,直接插入。
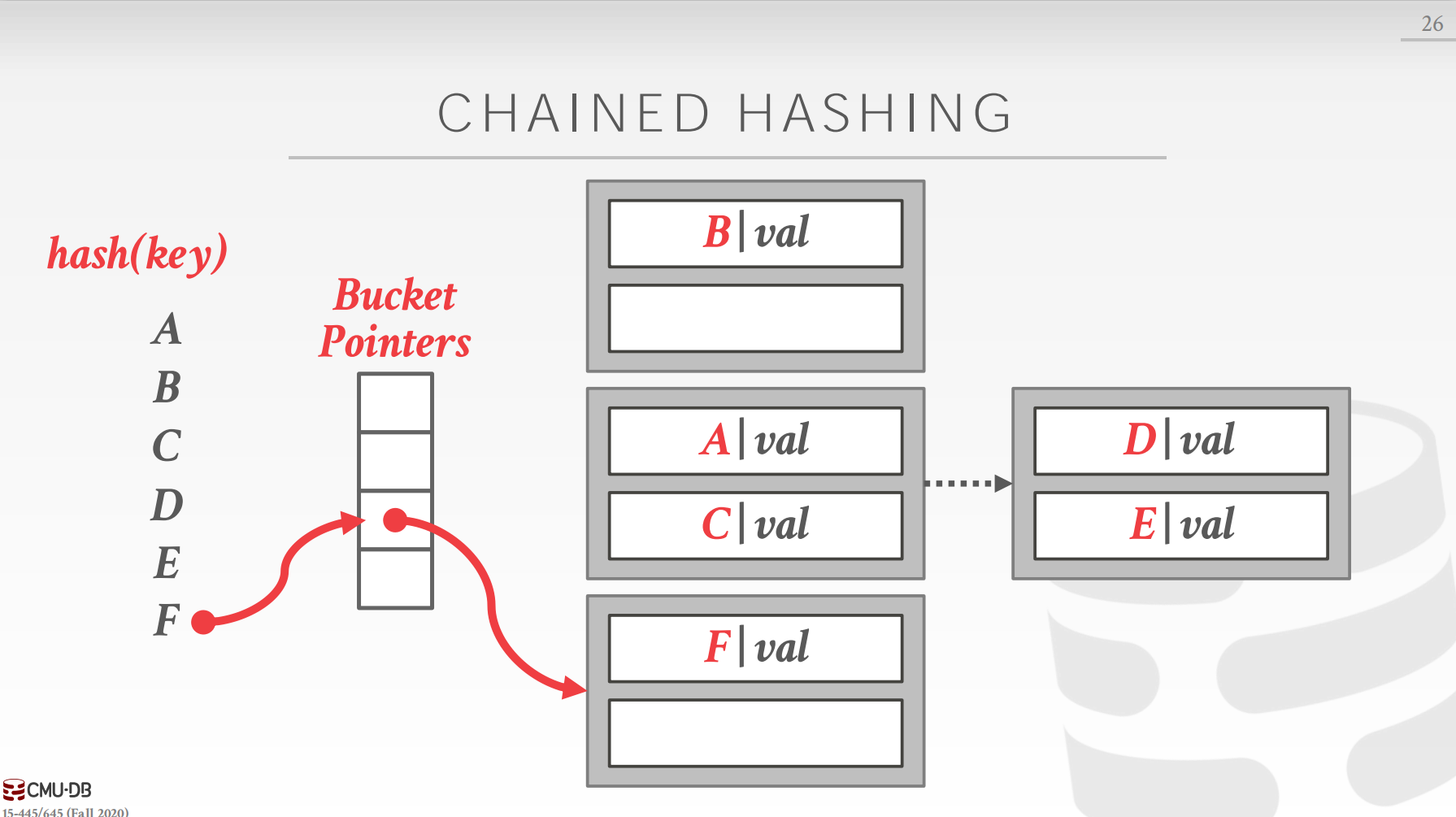
这样做的好处是什么呢?最大的好处就是各个键值对离自己的理想位置的距离变得“均衡”了,或许对查询的平均时间复杂度有一定的优化,但是一定复杂化了插入操作的时间复杂度。 实际上,经过实验发现,这种方法的效率不如线性探测法,不过这种方法的思想还是很有价值的。 4.3 布谷时钟哈希(Cuckoo Hashing)布谷钟摆动哈希方式准备了两个哈希表来存储数据,两个哈希表一般采用不同种子的哈希函数,并且提供 O ( 1 ) O(1) O(1)时间复杂度的查找和删除,但是插入操作会比较复杂。和线性探测不同,布谷时钟摆动哈希完全不需要扫描,具体来说: 对于查找和删除操作,在两个哈希表上分别运行哈希函数,然后比较键值对决定哪一个是所需的键值对。 而对于插入操作,我们依然在两个哈希表运行哈希函数,但是情况稍有些复杂。 如果两个哈希表上都有空位,那么就随机选择一个哈希表插入如果只有一个有空位,那么就插入到有空位的哈希表上如果两个哈希表都没有空位,那么就随机选择一个哈希表替换其对应位置的键值对,然后递归地插入被替换掉的键值对,直到所有键值对都插入到哈希表中。 5. 动态哈希方案(Dynamic Hashing Schemes)静态哈希方案都有一个大前提就是我们事前是知道哈希表需要容纳多少键值对的,否则如果出现预设的容量过大或者过小问题时,我们对其扩容或者缩容的代价都比较大(可以采用一致性哈希)。 因此,我们为了解决这个问题,提出了一些动态的哈希方案,即哈希表的运行的过程中可以按需增长或者减小。下面介绍三种动态哈希方案: 5.1 链式哈希(Chained Hashing)这是最简单的动态哈希方案,也是java或者jvm中默认的哈希方案。链式哈希中,哈希表中数组的成员是buckets的链表,因此,当发生冲突时,将元素添加到对应Bucket的末尾即可,如果Bucket已满,则创建一个新的Bucket即可。
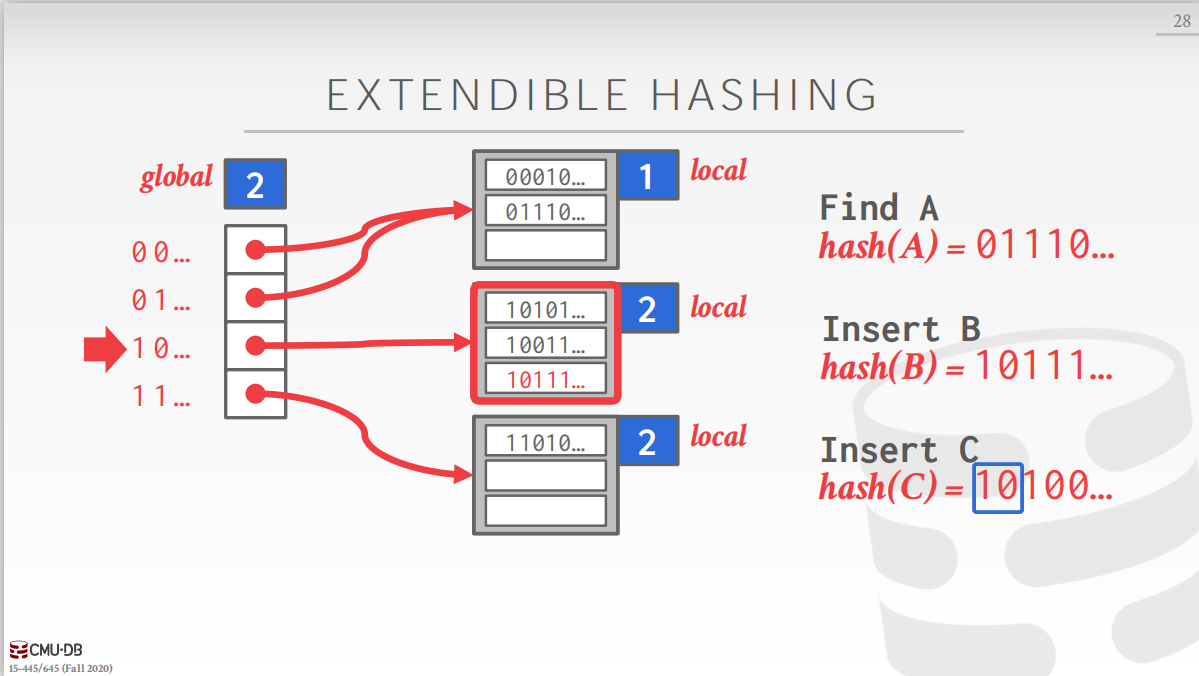
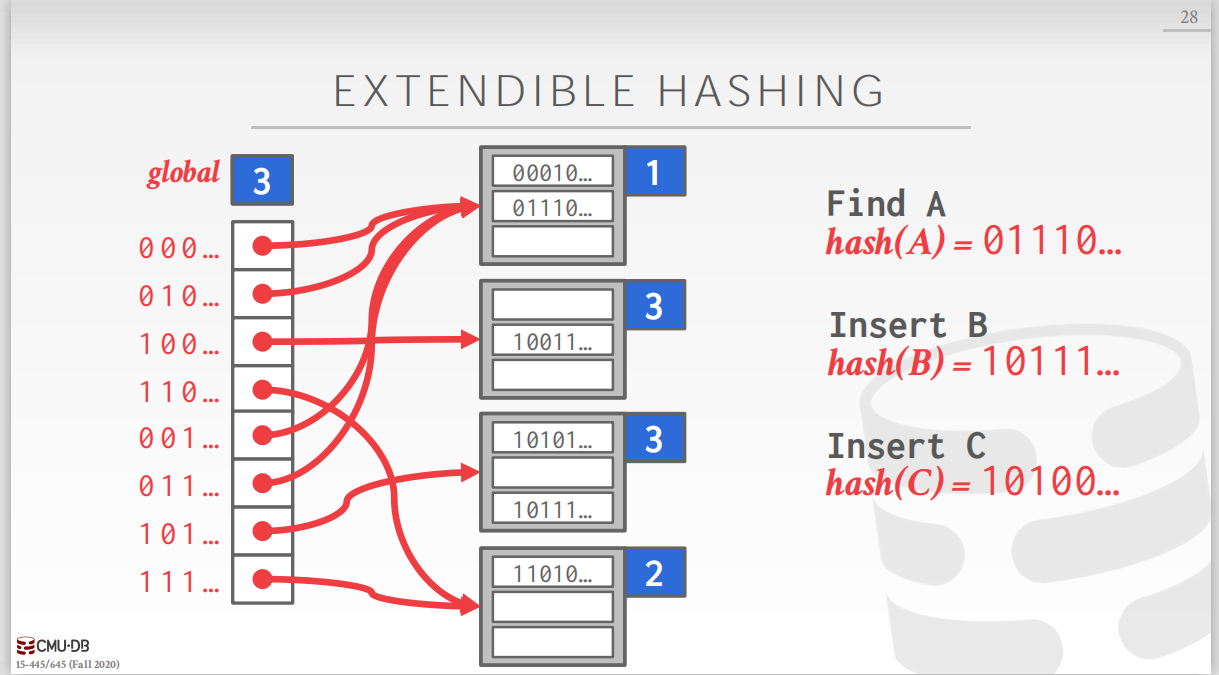
链式哈希的一种改进,每个bucket不再链式的生长,而是用分裂的方式来扩展,分裂的过程只会移动被分裂的bucket中的元素,而不会影响其他的元素。 如下图所示,可扩展哈希方式包含一个slot数组和一系列的buckets,每个slot中保存对应bucket的指针。对于slot数组有一个全局bit位,记录在这个哈希表中需要多少位才能找到对应bucket,对于每一个bucket,有一个本地bit位,记录找到本地的bucket需要多少位。 插入过程中,如下图,当插入C时,第二个bucket已满,此时再插入就需要对第二个bucket进行分裂,分裂之后,本地bit加1变成3,全局bit随之改变。注意分裂过程中,只改变了slot数组并移动了第二个bucket中的元素,修改slot数组的代价比较小,移动元素的代价较高。
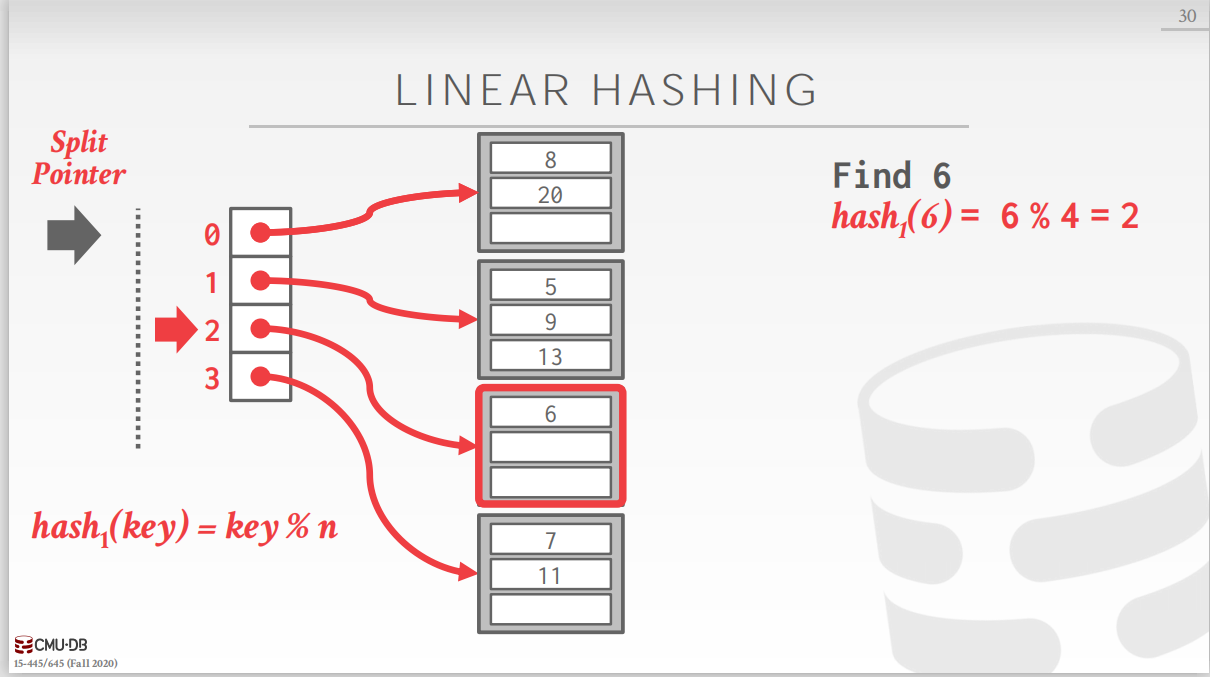
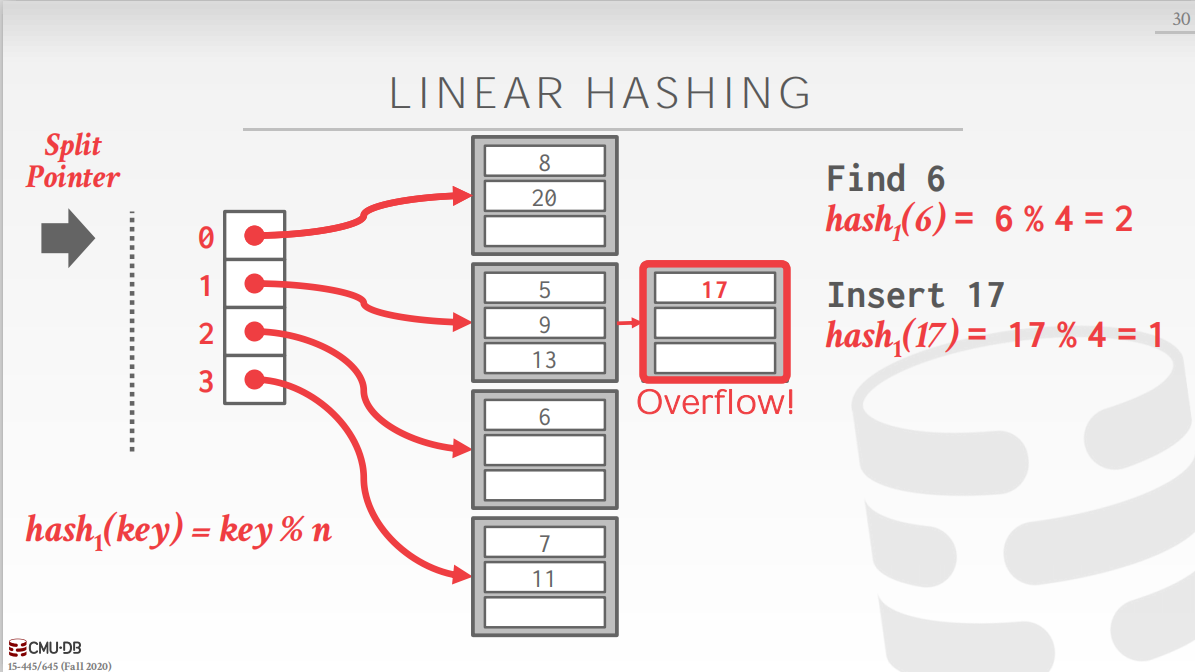
线性哈希是可扩展哈希的改进,可扩展哈希有一个小的性能瓶颈,在bucket分裂且需要扩展slot array时,需要对整个slot array加锁直到bucket分裂完成。为了解决这个问题,提出了线性哈希方式。哈希表维护一个指针,指向下一个准备分裂的bucket,并且线性哈希采用多个哈希函数来寻找正确的bucket。 当插入过程中,任何一个bucket溢出,都将分裂指针指向的bucket(无论这个bucket是否溢出),举个例子,,如下图。 最初,指针指向第一个bucket,即当任何一个bucket发生溢出时,都分裂第一个bucket。且现在只有一个哈希函数。
现需要插入17,发现对应的bucket已满,发生了溢出,因此需要分裂第一个bucket.
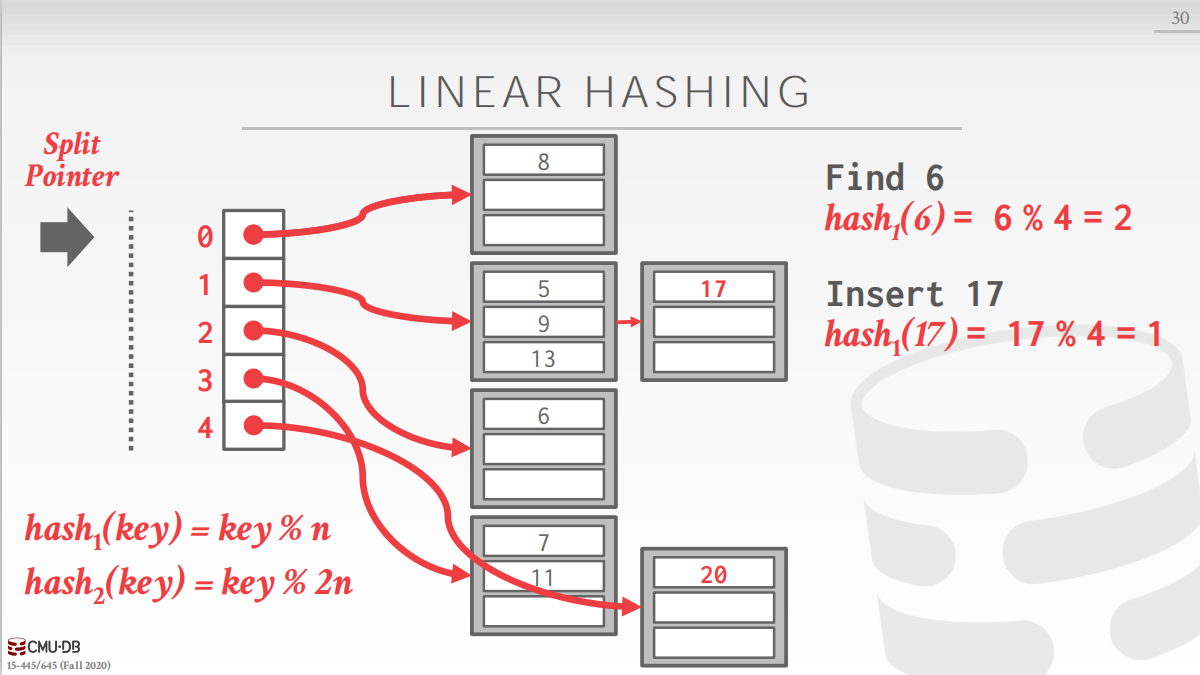
现在将第一个bucket分裂,就需要增加一个bucket,那么哈希哈希表中已经有了5个bucket,原来的哈希函数中的n为4,不能满足使用要求,需要增加新的哈希函数 h a s h 2 hash_2 hash2。然后使用新的哈希函数重新分配第一个bucket中的元素。
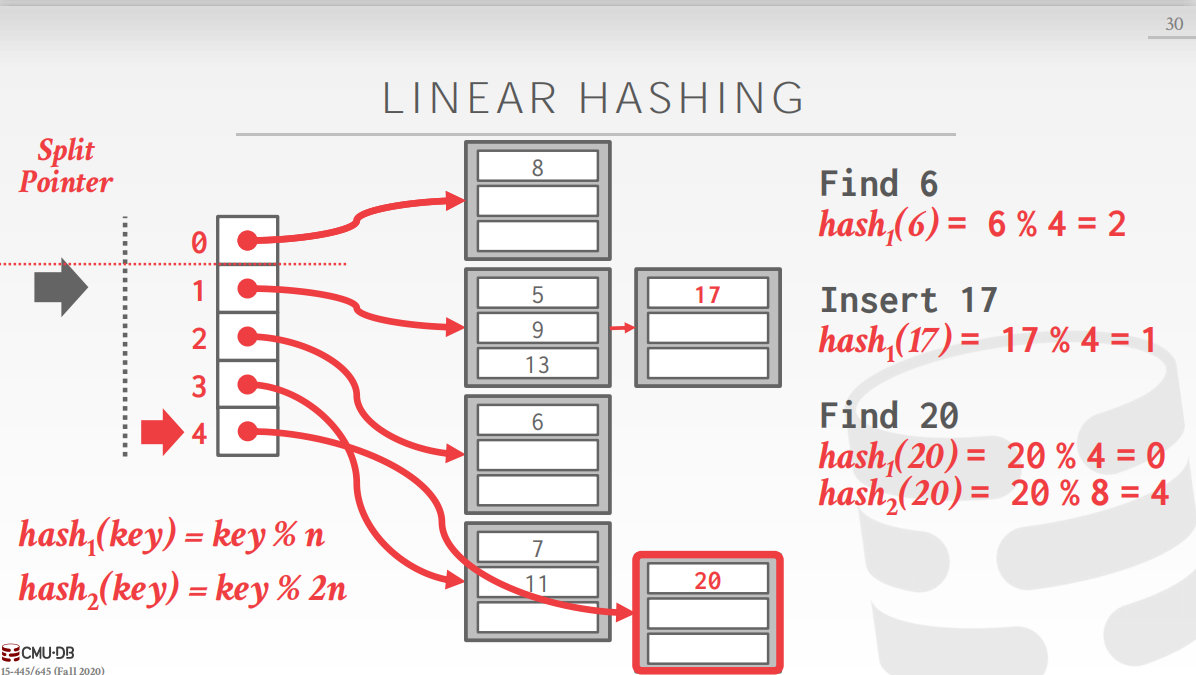
现在我们再来观察查询过程,现在需要查询20,首先使用第一个哈希函数,发现哈希值为0,即第一个bucket。但是这个哈希值落在了分裂指针的上面,即我们要查询的值落在一个已经分裂的bucket上,而这个bucket中的所有键值对已经用第二个哈希函数重新分配位置,因此,需要用第二个哈希函数重新计算哈希值为4,即第五个bucket中,然后在这个bucket中循序查询即可。
哈希表是一种速度非常快的数据结构,支持 O ( 1 ) O(1) O(1)级别的查找速度,哈希表的设计主要包括哈希函数和哈希方案。其中哈希方案包括静态方案和动态方案,静态方案即哈希表的大小是固定的,动态方案是哈希表的大小可以按需生长或者缩小。虽然对于哈希表有许多改进,但是其中速度最快还是最初的线性探测哈希。 哈希表是普遍使用的数据结构,有部分数据库使用哈希表作为索引(例如memcached),但哈希表并不适合用于索引的构建,因为哈希函数查找需要完整的key值,且不支持快速查找大于某个key的数据。实际上,构建索引一般使用B+树的方式,B+树是另一种极为优秀的数据结构。 测哈希**。 哈希表是普遍使用的数据结构,有部分数据库使用哈希表作为索引(例如memcached),但哈希表并不适合用于索引的构建,因为哈希函数查找需要完整的key值,且不支持快速查找大于某个key的数据。实际上,构建索引一般使用B+树的方式,B+树是另一种极为优秀的数据结构。 |
【本文地址】
今日新闻 |
推荐新闻 |