(11 |
您所在的位置:网站首页 › 设计的特征没有 › (11 |
(11
|
11.2 基于特征提取和机器学习的图像分类
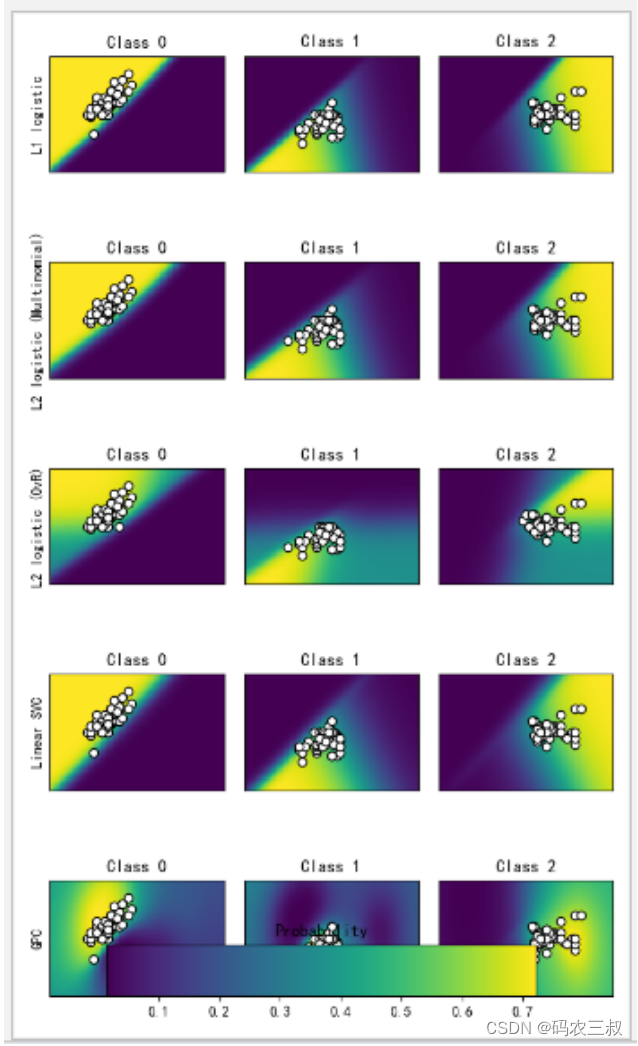
统的图像分类方法通常涉及手工设计的特征提取步骤,例如边缘检测、纹理特征提取、颜色直方图等。然后,这些提取的特征被输入到机器学习算法中,如支持向量机(SVM)、随机森林(Random Forest)和k最近邻(k-Nearest Neighbors)等进行分类。 11.2.1 基本流程使用特征提取和机器学习方法实现图像分类的基本流程如下: (1)数据准备:首先,需要收集并准备好带有标注的图像数据集。确保数据集中包含各个类别的典型样本,并确保标注准确和完整。 (2)特征提取:特征提取是将图像转换为机器学习算法能够理解和处理的特征向量的过程。常见的特征提取方法包括: 边缘检测:使用边缘检测算法(如Sobel、Canny等)提取图像的边缘信息。颜色直方图:将图像中各个颜色通道的像素值统计为直方图,用于表示颜色分布。纹理特征:提取图像中的纹理信息,如灰度共生矩阵(GLCM)和局部二值模式(LBP)等。尺度不变特征变换(SIFT):提取具有尺度和旋转不变性的局部特征描述子。主成分分析(PCA):将高维的图像特征降维到低维空间中,以减少特征的维度和冗余信息。(3)特征表示:将提取得到的特征转换为机器学习算法所需的向量形式。可以将特征向量简单地按照一定的规则进行拼接或者使用降维方法(如PCA)将其转换为较低维度的特征表示。 (4)数据划分:将准备好的特征向量以及对应的标签划分为训练集和测试集,通常采用交叉验证等方法进行划分。 (5)机器学习模型训练和分类:选择适当的机器学习算法,如支持向量机(SVM)、随机森林(Random Forest)或k最近邻(k-Nearest Neighbors)等。使用训练集的特征向量和标签进行模型训练,通过优化算法调整模型参数。训练完成后,使用测试集的特征向量进行分类预测,并评估分类准确率、精确率、召回率等指标。 (6)模型评估和调优:根据评估结果,可以调整机器学习模型的超参数、特征选择、模型选择等来提高分类性能。常用的方法包括网格搜索、交叉验证等。 需要注意的是,特征提取和机器学习方法在处理大规模图像数据集时可能存在一些限制,例如手工设计特征可能无法捕捉到复杂的语义信息。然而,在小规模数据集或资源受限的环境中,特征提取和机器学习方法仍然是一个有效的选择。随着深度学习技术的发展,深度学习方法在图像分类任务上取得了更好的性能,但传统方法仍然具有一定的实用性和应用场景。 11.2.2 基于Scikit-Learn机器学习的图像分类机器学习从开始到建模的基本流程是:获取数据、数据预处理、训练模型、模型评估、预测、分类。本次我们将根据传统机器学习的流程,看看在每一步流程中都有哪些常用的函数以及他们的用法是怎么样的。例如下面是一个使用库Scikit-learn实现图像分类的例子,其中采用了特征提取和机器学习方法。 实例11-1:使用库Scikit-learn实现图像分类 源码路径:daima\9\catdog.py import os import cv2 import numpy as np from sklearn.model_selection import train_test_split from sklearn.svm import SVC from sklearn.metrics import accuracy_score # 数据集路径和类别标签 dataset_path = "path_to_dataset" categories = ["cat", "dog"] # 提取特征的函数(示例中使用颜色直方图作为特征) def extract_features(image_path): image = cv2.imread(image_path) image = cv2.resize(image, (100, 100)) # 调整图像大小 hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256]) # 计算颜色直方图 hist = cv2.normalize(hist, hist).flatten() # 归一化并展平 return hist # 加载图像数据和标签 data = [] labels = [] for category in categories: category_path = os.path.join(dataset_path, category) for image_name in os.listdir(category_path): image_path = os.path.join(category_path, image_name) features = extract_features(image_path) data.append(features) labels.append(category) # 将数据集划分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42) # 使用支持向量机(SVM)作为分类器 classifier = SVC() classifier.fit(X_train, y_train) # 在测试集上进行预测 y_pred = classifier.predict(X_test) # 计算分类准确率 accuracy = accuracy_score(y_test, y_pred) print("Accuracy:", accuracy)在上述代码中,首先定义了数据集路径和类别标签。然后,通过函数extract_features()提取图像的特征,这里使用的是颜色直方图。接下来,遍历数据集中的图像,提取特征并将其添加到数据列表中,同时记录对应的类别标签。然后,使用函数train_test_split()将数据集划分为训练集和测试集。在训练阶段,使用SVC类作为分类器,通过调用fit方法对训练数据进行训练。最后,使用训练好的分类器在测试集上进行预测,并计算分类准确率。执行后会输出: Accuracy: 0.7857142857142857注意:上面输出的准确率只有0.78的原因是作者在运行时使用的数据集过小导致的,机器学习算法通常需要足够的数据来学习和泛化。在源码中提供了kaggle dog VS.cat 数据集(下载地址是:https://aistudio.baidu.com/aistudio/datasetdetail/11544),在这个训练集中共有25000张图片,猫狗各一半。格式为dog.xxx.jpg/cat.xxx.jpg(xxx为编号) 测试集12500张,没标定是猫还是狗,格式为xxx.jpg。大家可以使用这个数据集进行训练识别,准确率会大大提高。这只是一个简单的示例,实际应用中可能需要根据具体情况进行更多的数据预处理、特征选择、模型调优等步骤。另外,可以尝试使用其他特征提取方法和机器学习算法,以及结合交叉验证等技术来提高分类性能。 再看下面的实例文件hua.py,实现了鸢尾花识别的功能。这是一个经典的机器学习分类问题,它的数据样本中包括了4个特征变量,1个类别变量,样本总数为150。本实例的目标是根据花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)这四个特征来识别出鸢尾花属于山鸢尾(iris-setosa)、变色鸢尾(iris-versicolor)和维吉尼亚鸢尾(iris-virginica)中的哪一种。 实例11-2:实现鸢尾花的识别功能 源码路径:daima\9\hua.py # 引入数据集,sklearn包含众多数据集 from sklearn import datasets # 将数据分为测试集和训练集 from sklearn.model_selection import train_test_split # 利用邻近点方式训练数据 from sklearn.neighbors import KNeighborsClassifier # 引入数据,本次导入鸢尾花数据,iris数据包含4个特征变量 iris = datasets.load_iris() # 特征变量 iris_X = iris.data # print(iris_X) print('特征变量的长度', len(iris_X)) # 目标值 iris_y = iris.target print('鸢尾花的目标值', iris_y) # 利用train_test_split进行训练集和测试机进行分开,test_size占30% X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3) # 我们看到训练数据的特征值分为3类 print(y_train) # 训练数据 # 引入训练方法 knn = KNeighborsClassifier() # 进行填充测试数据进行训练 knn.fit(X_train, y_train) params = knn.get_params() print(params) score = knn.score(X_test, y_test) print("预测得分为:%s" % score) # 预测数据,预测特征值 print(knn.predict(X_test)) # 打印真实特征值 print(y_test)执行后会输出训练和预测结果: 特征变量的长度 150 鸢尾花的目标值 [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2] [2 1 2 1 0 2 0 1 0 1 0 1 1 2 1 0 0 0 1 2 2 2 2 1 1 2 1 0 2 0 2 0 0 2 2 2 0 1 1 2 0 2 1 1 1 2 0 0 1 1 1 1 1 0 1 0 2 2 2 1 1 0 0 2 0 2 1 0 2 1 1 0 2 2 2 0 1 1 0 2 0 1 2 2 1 1 1 0 1 1 2 0 0 2 0 0 1 2 0 0 0 0 1 2 2] {'algorithm': 'auto', 'leaf_size': 30, 'metric': 'minkowski', 'metric_params': None, 'n_jobs': None, 'n_neighbors': 5, 'p': 2, 'weights': 'uniform'} 预测得分为:1.0 [0 2 0 0 1 0 1 1 0 0 2 2 1 0 2 2 1 0 0 2 0 2 1 0 2 1 2 2 2 2 0 2 0 0 1 2 2 0 1 2 1 1 1 0 1] [0 2 0 0 1 0 1 1 0 0 2 2 1 0 2 2 1 0 0 2 0 2 1 0 2 1 2 2 2 2 0 2 0 0 1 2 2 0 1 2 1 1 1 0 1] 11.2.3 分类算法请看下面的实例文件fen.py,功能是绘制不同分类器的分类概率。我们使用一个3类的数据集,并使用支持向量分类器、带L1和L2惩罚项的Logistic回归, 使用One-Vs-Rest或多项设置以及高斯过程分类对其进行分类。在默认情况下,线性SVC不是概率分类器,但在本例中它有一个内建校准选项(probability=True)。箱外的One-Vs-Rest的逻辑回归不是一个多分类的分类器,因此,与其他分类器相比,它在分离第2类和第3类时有更大的困难。 实例11-3:绘制不同分类器对于一个数据集的分类概率 源码路径:daima\9\fen.py import matplotlib.pyplot as plt import numpy as np from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.gaussian_process import GaussianProcessClassifier from sklearn.gaussian_process.kernels import RBF from sklearn import datasets iris = datasets.load_iris() X = iris.data[:, 0:2] # we only take the first two features for visualization y = iris.target n_features = X.shape[1] C = 10 kernel = 1.0 * RBF([1.0, 1.0]) # for GPC # Create different classifiers. classifiers = { 'L1 logistic': LogisticRegression(C=C, penalty='l1', solver='saga', multi_class='multinomial', max_iter=10000), 'L2 logistic (Multinomial)': LogisticRegression(C=C, penalty='l2', solver='saga', multi_class='multinomial', max_iter=10000), 'L2 logistic (OvR)': LogisticRegression(C=C, penalty='l2', solver='saga', multi_class='ovr', max_iter=10000), 'Linear SVC': SVC(kernel='linear', C=C, probability=True, random_state=0), 'GPC': GaussianProcessClassifier(kernel) } n_classifiers = len(classifiers) plt.figure(figsize=(3 * 2, n_classifiers * 2)) plt.subplots_adjust(bottom=.2, top=.95) xx = np.linspace(3, 9, 100) yy = np.linspace(1, 5, 100).T xx, yy = np.meshgrid(xx, yy) Xfull = np.c_[xx.ravel(), yy.ravel()] for index, (name, classifier) in enumerate(classifiers.items()): classifier.fit(X, y) y_pred = classifier.predict(X) accuracy = accuracy_score(y, y_pred) print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100)) # View probabilities: probas = classifier.predict_proba(Xfull) n_classes = np.unique(y_pred).size for k in range(n_classes): plt.subplot(n_classifiers, n_classes, index * n_classes + k + 1) plt.title("Class %d" % k) if k == 0: plt.ylabel(name) imshow_handle = plt.imshow(probas[:, k].reshape((100, 100)), extent=(3, 9, 1, 5), origin='lower') plt.xticks(()) plt.yticks(()) idx = (y_pred == k) if idx.any(): plt.scatter(X[idx, 0], X[idx, 1], marker='o', c='w', edgecolor='k') ax = plt.axes([0.15, 0.04, 0.7, 0.05]) plt.title("Probability") plt.colorbar(imshow_handle, cax=ax, orientation='horizontal') plt.show()上述代码实现了在一个二维特征空间中可视化多个分类器的决策边界和分类概率。这段代码主要用于演示不同分类器在二维特征空间中的分类效果和概率分布情况。通过观察决策边界和概率图像,可以了解不同分类器在鸢尾花数据集上的性能和特点。具体实现流程如下: 首先,加载了鸢尾花(Iris)数据集,其中X是特征矩阵,包含了鸢尾花的萼片长度和宽度两个特征;y是目标变量,包含了鸢尾花的类别标签。然后,定义了一个正态核函数(RBF)作为高斯过程分类器(GPC)的核函数,并设置了惩罚参数C。创建不同的分类器,包括L1正则化的逻辑回归(L1 logistic)、L2正则化的逻辑回归(L2 logistic)、线性支持向量机(Linear SVC)和高斯过程分类器(GPC)。这些分类器使用不同的参数和算法来进行训练和分类。使用plt.subplots_adjust调整子图的位置和间距,创建一个绘图窗口,并设置图像的大小。生成了一个网格点坐标矩阵(Xfull),用于在整个特征空间中生成预测结果。对于每个分类器,依次进行训练和预测,计算训练集上的准确率,并打印出来。对于每个分类器,绘制了类别的预测概率图像,显示了每个类别的概率分布情况。通过调整颜色条的位置和大小,将颜色条添加到图像中。最后使用plt.show()显示绘制的图像。执行后会输出下面的结果,并在Matplotlib中绘制三种分类的概率,如图6-1所示。 Accuracy (train) for L1 logistic: 83.3% Accuracy (train) for L2 logistic (Multinomial): 82.7% Accuracy (train) for L2 logistic (OvR): 79.3% Accuracy (train) for Linear SVC: 82.0% Accuracy (train) for GPC: 82.7%
图11-1 执行效果 11.2.4 聚类算法请看下面的实例文件face.py,功能是使用一个大型的Faces数据集学习一组组成面部的20 *20的图像修补程序。本实例非常有趣,展示了使用Scikit-Learn在线API学习按块处理一个大型数据集的方法。本实例处理的方法是一次加载一个图像,并从这个图像中随机提取50个补丁。一旦积累了500个补丁(使用10个图像),则运行在线KMeans对象 MiniBatchKMeans的partial_fit方法。在连续调用partial-fit期间,某些聚类会被重新分配。这是因为它们所代表的补丁数量太少了,所以最好选择一个随机的新聚类。 实例11-4:使用一个Faces数据集学习一组组成面部的20 *20的图像修补程序 源码路径:daima\9\face.py import time import matplotlib.pyplot as plt import numpy as np from sklearn import datasets from sklearn.cluster import MiniBatchKMeans from sklearn.feature_extraction.image import extract_patches_2d faces = datasets.fetch_olivetti_faces() # ############################################################################# # Learn the dictionary of images print('Learning the dictionary... ') rng = np.random.RandomState(0) kmeans = MiniBatchKMeans(n_clusters=81, random_state=rng, verbose=True) patch_size = (20, 20) buffer = [] t0 = time.time() # 在整个数据集上循环6次 index = 0 for _ in range(6): for img in faces.images: data = extract_patches_2d(img, patch_size, max_patches=50, random_state=rng) data = np.reshape(data, (len(data), -1)) buffer.append(data) index += 1 if index % 10 == 0: data = np.concatenate(buffer, axis=0) data -= np.mean(data, axis=0) data /= np.std(data, axis=0) kmeans.partial_fit(data) buffer = [] if index % 100 == 0: print('Partial fit of %4i out of %i' % (index, 6 * len(faces.images))) dt = time.time() - t0 print('done in %.2fs.' % dt) # ############################################################################# # Plot the results plt.figure(figsize=(4.2, 4)) for i, patch in enumerate(kmeans.cluster_centers_): plt.subplot(9, 9, i + 1) plt.imshow(patch.reshape(patch_size), cmap=plt.cm.gray, interpolation='nearest') plt.xticks(()) plt.yticks(()) plt.suptitle('Patches of faces\nTrain time %.1fs on %d patches' % (dt, 8 * len(faces.images)), fontsize=16) plt.subplots_adjust(0.08, 0.02, 0.92, 0.85, 0.08, 0.23) plt.show()上述代码主要用于学习和展示图像字典中的图像块。通过将图像块提取为数据,然后使用MiniBatchKMeans算法对数据进行聚类,可以学习到一组具有代表性的图像块,用于后续的图像处理和特征表示。本实例实现了使用MiniBatchKMeans算法学习图像字典,并展示学习到的图像字典中的图像块。具体实现流程如下所示: 首先,导入了需要的库和模块,包括time、matplotlib.pyplot和numpy。通过datasets.fetch_olivetti_faces()加载了奥利维蒂人脸数据集(Olivetti Faces),该数据集包含了一组人脸图像。接下来,定义了一个MiniBatchKMeans聚类器,并设置了聚类的数量n_clusters为81,以及随机数生成器的种子random_state。定义了一个图像块的大小patch_size,它在本例中是一个20x20的矩形。创建了一个空列表buffer,用于存储图像块的数据。通过循环遍历整个数据集6次,对每张人脸图像进行处理。在每次循环中,使用extract_patches_2d函数从图像中提取图像块,设置最大提取数量为50,然后将图像块的数据进行重塑和规范化处理,将其添加到buffer列表中。每当buffer列表中的图像块数量达到10个时,将它们连接成一个数据矩阵,并进行均值归一化处理。然后,使用kmeans.partial_fit对数据进行部分拟合(partial fit)来更新聚类器的参数。每当处理了100个图像块时,打印出部分拟合的进度。通过计算总共花费的时间来评估学习过程的耗时。最后,使用matplotlib.pyplot绘制了学习到的图像字典中的图像块。循环遍历聚类器的聚类中心,并使用plt.subplot在子图中显示图像块。设置了合适的标题和调整子图的布局。通过plt.show()显示绘制的图像。执行效果如图11-2所示。
图11-2 执行效果 |

【本文地址】
今日新闻 |
推荐新闻 |