随机森林做特征重要性排序和特征选择 |
您所在的位置:网站首页 › 随机森林可以做回归吗 › 随机森林做特征重要性排序和特征选择 |
随机森林做特征重要性排序和特征选择
|
随机森林模型介绍:
随机森林模型不仅在预测问题上有着广泛的应用,在特征选择中也有常用。 随机森林是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,更令人惊奇的是它在分类和回归上表现出了十分惊人的性能。 随机森林模型在拟合数据后,会对数据属性列,有一个变量重要性的度量,在sklearn中即为随机森林模型的 feature_importances_ 参数,这个参数返回一个numpy数组对象,对应为随机森林模型认为训练特征的重要程度,float类型,和为1,特征重要性度数组中,数值越大的属性列对于预测的准确性更加重要。 随机森林(RF)简介:只要了解决策树的算法,那么随机森林是相当容易理解的。随机森林的算法可以用如下几个步骤概括: 1、用有抽样放回的方法(bugging)从样本集中选取n个样本作为一个训练集2、用抽样得到的样本集生成一棵决策树。在生成数的每一个结点: 1、随机不重复地选择d个特征2、利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数(CART数)、增益率(C4.5)或者信息增益(ID3)判别) 3、重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。4、用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。 下图比较直观地展示了随机森林算法:
随机森林的随机性体现在: 选取样本时 有放回的随机选取。 会导致不同的树,分别学到整体数据集的一部分特征,最终大家投票,得到最终的预测结果。sklearn提供前剪枝技术。个人解读, 1.随机森林已经通过随机选择样本和特征,保证了随机性,不用后剪枝应该也能避免过拟合 2.后剪枝是为了避免过拟合,随机森林随机选择变量与树的数量,已经避免了过拟合,没必要去后剪枝了。 3.一般rf要控制的是树的规模,而不是树的置信度,后剪枝的作用其实被集成方法消解了,所以用处不大。 特征重要性评估:sklearn 已经帮我们封装好了一切。 1、 以UCI上葡萄酒的例子为例,首先导入数据集。 数据集介绍:数据集 特征: AlcoholMalic acidAshAlcalinity of ashMagnesiumTotal phenolsFlavanoidsNonflavanoid phenolsProanthocyaninsColor intensityHueOD280/OD315 of diluted winesProline # 导入数据 import pandas as pd url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data' df = pd.read_csv(url, header = None) df.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']2、数据初探 #初看数据 df.head(5)
3、 建模 将数据集分为训练集和测试集。 from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier x = df.iloc[:, 1:].values y = df.iloc[:, 0].values
查看选择的特征具体情况。 x_selected_columns = feat_labels[importances > threshold]Index([‘Flavanoids’, ‘Color intensity’, ‘Proline’], dtype=‘object’) 说明仅仅选择了’Flavanoids’, ‘Color intensity’, 'Proline’3列。 import pandas as pd x_select_pd = pd.DataFrame(x_selected,columns=x_selected_columns) x_select_pd
在做特征选择是特性工程最后一步,一般先进行相关性分,消除两两变量的线性相关性,然后再进行随机森林进行重要特征的筛选。 |

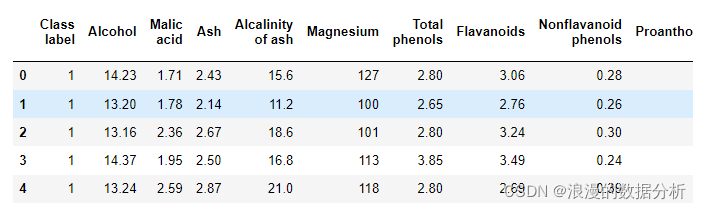
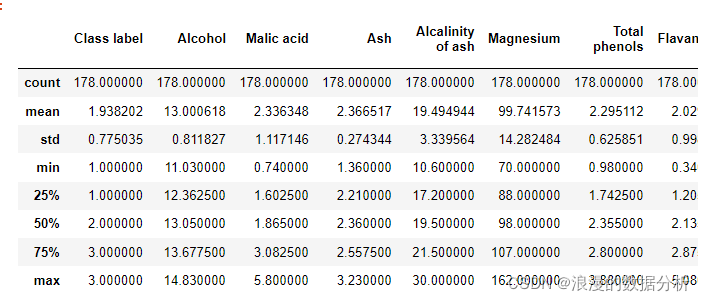 可见除去class label之外共有13个特征,数据集的大小为178。无缺失值。
可见除去class label之外共有13个特征,数据集的大小为178。无缺失值。

 4、设置特征选择阈值:
4、设置特征选择阈值: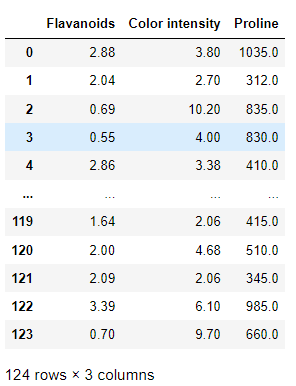 特征选择完毕。
特征选择完毕。【本文地址】
今日新闻 |
推荐新闻 |