如何评估随机森林模型以及重要预测变量的显著性 |
您所在的位置:网站首页 › 随机森林能做什么 › 如何评估随机森林模型以及重要预测变量的显著性 |
如何评估随机森林模型以及重要预测变量的显著性
|
如何评估随机森林模型以及重要预测变量的显著性
说到随机森林(random forest,RF),想必很多同学都不陌生了,毕竟这些机器学习方法目前非常流(fàn)行(làn)……白鱼同学也曾分别分享过“随机森林分类”以及“随机森林回归”在R语言中实现的例子,包括模型拟合、通过预测变量的值预测响应变量的值、以及评估哪些预测变量是“更重要的”等。在这两篇推文中,都是使用randomForest包执行的分析。不过在实际应用中,比方说想模仿一些文献的分析过程时,却发现某些统计无法通过randomForest包实现? 以评估预测变量的重要性为例,借助随机森林的实现方法经常在文献中见到,例如下面的截图所示。先前也有好多同学咨询,说如何像这篇文献中这样,计算出预测变量的显著性?虽说最常使用的randomForest包可以给出预测变量的相对重要性得分,允许我们根据得分排名从中确定哪些预测变量是“更重要的”,但却没有提供估计p值的方法。当我们出于某种需要想获知变量的显著性信息时,仅使用randomForest包就会很困扰?
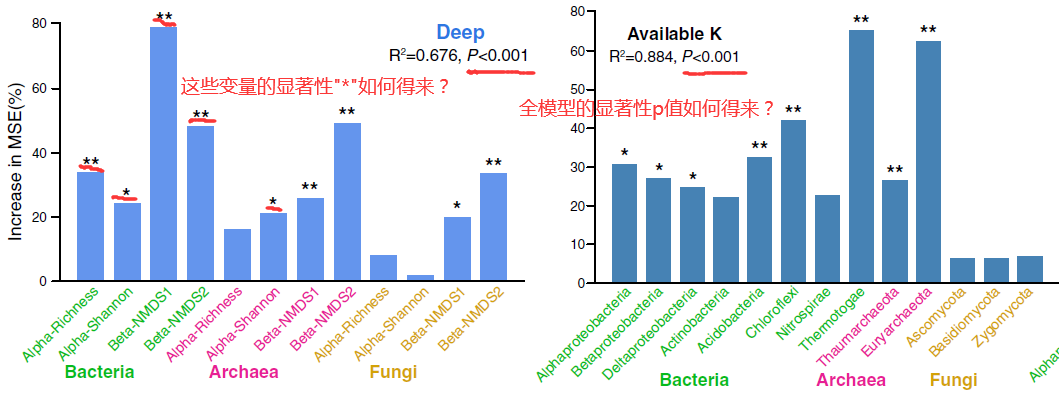
截图来自Jiao等(2018)的图5部分。左图展示了细菌、古细菌和真菌群落的α和β多样性在贡献深层土壤多养分循环指数中的重要性;右图展示了优势微生物分类群与土壤可利用钾的关系。两个图中变量的重要性以随机森林中的“percentage of increase of mean square error”(Increase in MSE(%))值进行衡量,更高的MSE%值意味着更重要的变量,并标识了各变量的显著性。图上方的数值为总方差解释率,以及全模型的显著性p值。
randomForest包实现不了的功能,那就用其它R包进行补充呗。至于用哪些R包可以,文献中通常都有详细的方法描述,仔细看一下材料方法部分大致就明确了。就以上面的Jiao等(2018)的文章为例,材料方法部分提到可通过A3包可获取对全模型显著性的估计,并可通过rfPermute包可获取对随机森林中预测变量重要性的显著水平估计。
接下来,就简单展示A3包和rfPermute包的使用,包括如何使用这些包执行随机森林分析,以及获取对全模型或者重要预测变量的显著性的估计。
下文的测试数据,R代码等的百度盘链接(提取码,z8zb): https://pan.baidu.com/s/1-L78HuRzZCvH2LCzys4wJQ 若百度盘失效,也可在GitHub的备份中获取: https://github.com/lyao222lll/sheng-xin-xiao-bai-yu
通过R包randomForest执行随机森林回归
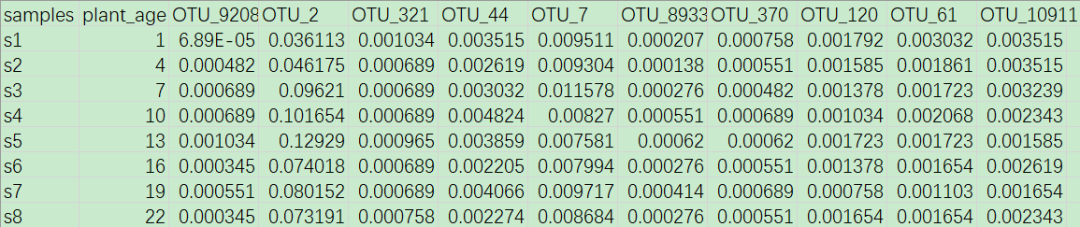
为了进行对比说明,先来回顾一个先前的例子。 例如前文“随机森林回归”中使用R语言randomForest包执行随机森林回归。我们基于45个连续生长时间中植物根际土壤样本中细菌单元(OTU)的相对丰度数据,通过随机森林拟合了植物根际细菌OTU丰度与植物生长时期的响应关系(即,随机森林回归模型构建),根据植物根际细菌OTU丰度预测植物生长时期(即,通过预测变量对响应变量的值进行预测),并筛选出10个重要的具有明显时间特征的植物根际细菌OTU(即,评估预测变量的相对重要性并筛选重要的预测变量组合)。完整分析过程可参考前文“随机森林回归模型以及对重要变量的选择”,这里作了删减和改动,仅看其中的评估变量重要性的环节部分。 示例数据 网盘示例数据“otu_top10.txt”中,共记录了45个连续生长时间中植物根际土壤样本中10种细菌OTU的相对丰度信息。
其中,samples列为45个样本的名称;plant_age记录了这45个根际土壤样本对应的植物生长时间(或称植物年龄),时间单位是天;其余10列为10种重要的细菌OTU的相对丰度信息,预先根据某些统计方法筛选出来的,它们已知与植物生长时间密切相关。 执行随机森林评估变量重要性 在这里,我们期望通过随机森林拟合这10种根际细菌OTU丰度与植物生长时期的响应关系,以得知哪些根际细菌OTU更能指示植物年龄。 #读取 OTU 丰度表 #包含预先选择好的 10 个重要的 OTU 相对丰度以及这 45 个根际土壤样本对应的植物生长时间(天) otu |



【本文地址】
今日新闻 |
推荐新闻 |