pandas数据分析实战 (超详细) |
您所在的位置:网站首页 › 销售数据分析的过程是怎样的 › pandas数据分析实战 (超详细) |
pandas数据分析实战 (超详细)
|
根据以下链接的文章,https://mp.weixin.qq.com/s/RcrQmqty1FHEDbQfxv2XTQ 一步步做了练习,第一次使用Python,遇到问题颇多。花了差不多一周的时间从完成第一步到最后一步。 写下此文章记录下自己遇到的问题。 -------------------------------------------------------------------------------------- 目录 1.数据读取 2.数据概述 3.数据清洗和整理 4.数据分析和可视化 ------------------------------------------------------------------------------ 1.数据读取 常用的数据载入函数: read_csv read_excel read_txt read_sql) 本来原文提供的是csv格式,但因为我电脑的字体设置是英文,导致了乱码。我重新调整了下,保存成了xlsx的格式。 如果你也遇到中文乱码的话,可以尝试下面的方法:ps:后面需要选择Chinese的code,这样中文才会显示出来,不是乱码。
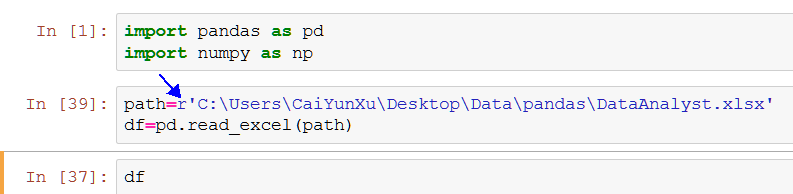
接下来就是使用read_excel函数读取源文件的数据,numpy 和 pandas是第三方工具包,每次使用前都需要载入。
找好源文件的path, 这里注意的是在Python中‘ / ’是转义符,所以如果path的时候用的是 / 的话,前面就要加个r,这样python就能辨别出这里并不是转义符的用法。Python常用的描述路径有一下三种方式:
上面运行的结果如下:
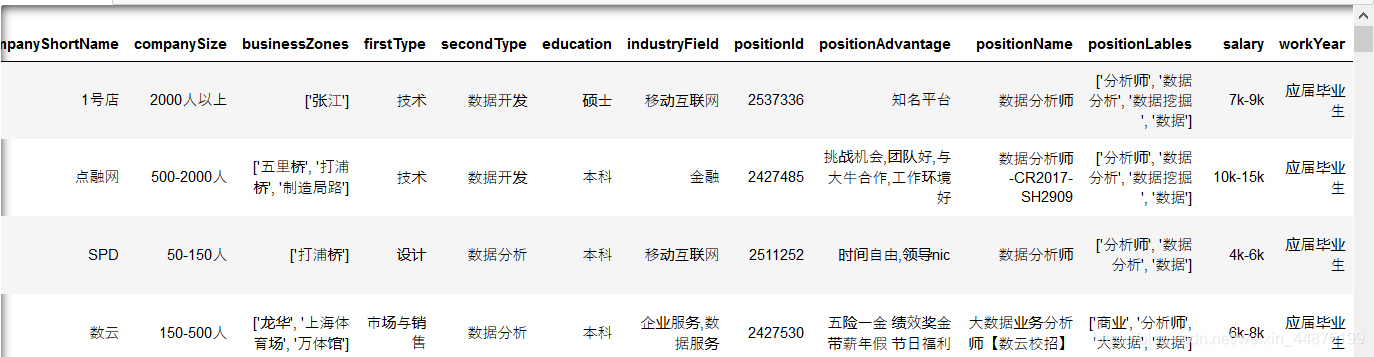
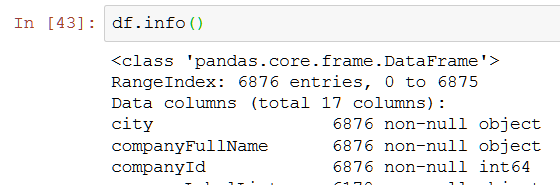
第一步的数据载入end ------------------------------------------------------------------------------------------ 2.数据概述 df.head( ) - 显示头部的数据,默认为5,也可以自由设置参数 df.tail( ) - 显示尾部的数据,默认为5,也可以自由设置参数 df.info( ) - 查看数据类型
这里列举出了数据集拥有的各类字段,一共有6876个,其中companyLabelList,businessZones,secondType,positionLables都存在为空的情况。公司id和职位id为数字,其他都是字符串。因为数据集的数据比较多,如果我们只想浏览部分的话,可以使用head函数,显示头部的数据,默认5,也可以自由设置参数,如果是尾部数据则是tail。
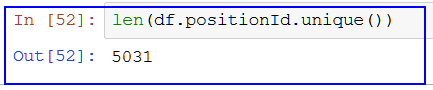
---------------------------------------------------------------------------------------------------------------------------------------------------- 3.数据清洗和整理 我们是要看各地各公司的薪资情况,所以先着重处理薪资数据栏,这也是最高的数据。 第一步:查重 使用函数:unique( ) 注意:column名称区别大小写,python是分大小写的。 unique函数可以返回唯一值,数据集中positionId是职位ID,值唯一 配合len函数计算出唯一值共有5031个,说明有多出来的重复值。
第二步:去重 使用函数:drop duplicates()
函数详解
第三步:加工salary薪资字段,我们要取薪资的平均数。就先取出最低工资和最高工资。 使用函数: 自定义函数def( ): https://blog.csdn.net/u014745194/article/details/70158926 find( )函数: apply( )函数: https://blog.csdn.net/anshuai_aw1/article/details/82347016 可以针对DataFrame中的一行或者一行数据进行操作,允许使用自定义函数。 upper()函数:全部变大写
观察薪资内容,并没有特殊的规律,既有小写k,也有大写K。还有k以上的,k以上的只能默认最低最高一样。 先取最低工资
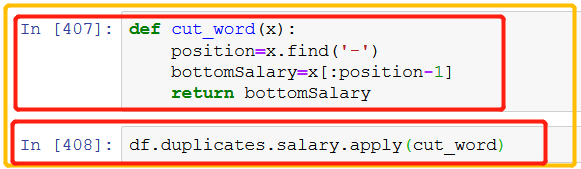
cut_word为自定义函数的名称,其中,利用find( )函数定位‘- ’逻辑位置,并且截取薪资范围开头至K之间的数字,也就是我们想要的薪资上限,即最低工资。apply将word_cut函数应用在salary列的所有行。 不明白的地方 -def cut_word( word) 里面的都word,整个自定义函数都没有定义它,它是怎么跟源文件的薪资栏联系在一起的???? 解答: word可以看成x,这样看起来可能好理解一些;整个自定义函数就是:
第一个红框里面,并没有将x与salary联系起来,在这里面,x是必选参数(位置参数);但是在第二个红框 - salary.apply(cut_word),这个时候就是将salary代入了参数x里面,联系起来了。apply将word_cut函数应用在salary列的所有行。 接下来处理k以上的薪资数据 对于‘k以上的’薪资,用find函数去找的话,结果是-1,代表是找不到结果。如果按照原来的方式截取,是word[:-2],不是我们想要的结果,所以需要加一个if判断。
因为python大小写敏感,我们用upper函数将k都转换为K,然后以K作为截取。这里不建议用「以上」,因为有部分脏数据不包含这两字。
上面的df_dplicates['bottomSalary']相当于直接在df_duplicates的表格上新加一个column - bottomSalary。 将bottomSalary转换成数字,如果转换成功了,说明所有的薪资数字都成功截取了 接下来取最高工资 在word_cut函数增加了新的参数用以判断返回bottom还是top,属于默认参数。 apply中,参数是添加在函数后面,而不是里面的。
接下来求薪资平均值 用到的函数: astype() lamdba函数 (匿名函数): https://blog.csdn.net/anshuai_aw1/article/details/82347016 没有具体名称的函数,它允许快速定义单行函数,可以用在任何需要函数的地方。这区别于def定义的函数。
首先先将上面求出来的bottomSalary & topSalary的数据类型转换成为数据。
然后求平均值
lambda x: ******* ,前面的lambda x:理解为输入,后面的星号区域则是针对输入的x进行运算。案例中,因为同时对top和bottom求平均值,所以需要加上x.bottomSalary和x.topSalary。 axis是apply中的参数,axis=1表示将函数用在行,axis=0则是列。 PS:上面的 lambda 可以用这个来代替 : df_duplicates['avgSalary']=(df_duplicates.topSalary+df_duplicates.bottomSalary) / 2 到此,数据清洗部分完成。接下来切选出几个我们想要的columns(可根据自己需求切选) 为什么这里要引用 ' [ [ ] ] ', 而【 】就不行 ?? - 有待调查
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- 4.数据分析和可视化 针对切取出来的数据,先进行几个描述统计。 使用的函数: value_counts( ) 是计数,统计所有非零元素的个数,以降序的方式输出Series describe( ), 能快速生成各类统计指标 数据分析 【哪个城市招聘的数据师最多】数据中可以看出北京招聘的数据师是对多的。
针对数据分析师的薪资,我们用describe函数。数据分析师的薪资的平均数是17k,中位数是15k,两者相差不大,最大薪资在75k,应该是数据科学家或者数据分析总监档位的水平。标准差在8.99k,有一定的波动性,大部分分析师薪资在17士9k之间。(找时间回顾统计学知识,便于更好的理解)
总结:一般分类数据用value_counts,数值数据用describe,这是最常用的两个统计函数。 文字再多也没图表清晰,我们用图表说话。 数据可视化 python常用的绘图包:matplotlib 和 seaborn。 此次练习只涉及 matplotlib。 pandas自带绘图函数,它是以matplotlib包为基础封装,所以两者能够结合使用。(一开始有import pandas as pd,所以这里就不需要再次import pandas) 每次绘图前,都需要载入 import matplotlib.pyplot as plt %matplotlib inline是jupyter自带的方式 - 允许图表在cell中输出。 plt.style.use('ggplot')使用R语言中的ggplot2配色作为绘图风格,纯粹为了好看。
绘制直方图 使用函数: hist( )函数: https://blog.csdn.net/u014525494/article/details/80157402 https://blog.csdn.net/claroja/article/details/72910163 (参数解释) 直方图是为了表明数据分布情况。通俗地说就是哪一块数据所占比例或者出现次数较高,哪一块出现概率低。 默认情况下,总共分为10段,即 bins=10
hist(x,bins) 函数中bins是指直方图的总个数,个数越多,条形带越紧密。 ------------------------------------------------------------------------------------------------------------ 我们以平均工资为内容,绘制下面的直方图。
图表列出了数据分析师薪资的分布,因为大部分薪资集中20k以下,为了更细的粒度。将直方图的宽距继续缩小。 将bins调整为15,如下:
数据分布呈双峰状,因为原始数据来源于招聘网站的爬取,薪资很容易集中在某个区间,不是真实薪资的反应(10~20k的区间,以本文的计算公式,只会粗暴地落在15k,而非均匀分布)。 ‘双峰型,一般是混合了多种数据源或者类别数据造成的。’
绘制箱线图 使用函数: dataFrame.boxplot( ) https://blog.csdn.net/walking_visitor/article/details/83109846 数据分析的一大思想是细分维度,现在观察不同城市、不同学历对薪资的影响。箱线图是最佳的观测方式。 boxplot方法只是用于DataFrame
column - 默认为None,输入为str 或由str构成的list,其作用是指定要进行箱型图分析的列 by - 默认为None,str or array-like,其作用为pandas的group by,通过指定by=‘columns’,可进行多组合箱型图分析 figsize - 箱型图窗口尺寸大小
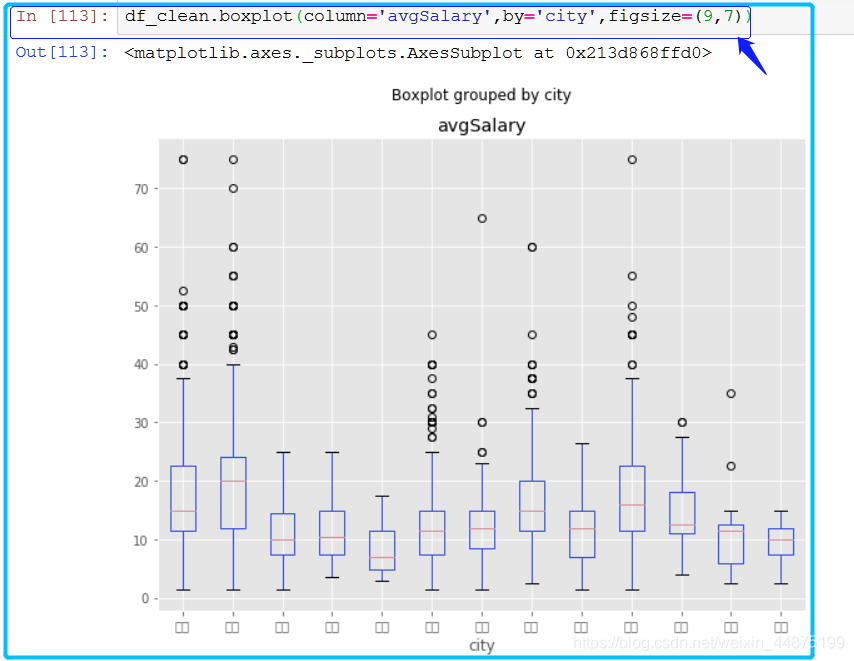
不同城市对薪资的影响
图表的标签出了问题,出现了白框,主要是图表默认用英文字体,而这里的都是中文,导致了冲突。 经过各种调查,有三种方法可以解决。(具体方法参考以下链接), https://blog.csdn.net/u010758410/article/details/71743225 文章有提供别的方法,但我选择比较好操作的第二种 - 动态设置参数。缺点应该是下次还要重新设置。
动态设置好之后,再次运行的时候,城市名称就出来了。 from pylab import mpl mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
关于上面的箱线图解析 - 北京的数据分析师薪资高于其他城市,尤其是中位数。上海和深圳稍次,广州甚至不如杭州 下面看一下不同教育背景对薪资的影响
关于上面的箱线图的解析 - 从学历看,博士薪资遥遥领先,虽然在top区域不如本科和硕士,这点我们要后续分析。大专学历稍有弱势。 下面看一下不同工作年限对薪资的影响
关于上面的箱线图的解析 - 工作年限看,薪资的差距进一步拉大,毕业生和工作多年的不在一个梯度。虽然没有其他行业的数据对比,但是可以确定,数据分析师的职场上升路线还是挺光明的。 上面的箱线图都是单一维度去看, 现在我们试着两个维度来看一下: 二维度分析 使用函数: isin( ) - 筛选函数
解析 - 从图上可以看到,不同学历背景下,北京都是稍优于上海的,北京愿意花费更多薪资吸引数据分析师,而在博士这个档次,也是一个大幅度的跨越。我们不妨寻找其中的原因。 另外,在by传递多个值,箱线图的刻度自动变成元组,也就达到了横向对比的作用(这方法其实并不好,以后会讲解其他方式)。这种方法并不适宜元素过多的场景。 多维度分析 使用的函数: group by ( ) unstack ( ) https://blog.csdn.net/ZK_J1994/article/details/77461480 step 1 - group by + count( )
上面是标准的用法,按city列,针对不同城市进行了分组。不过它并没有返回分组后的结果,只返回了内存地址。这时它只是一个对象,没有进行任何的计算
返回的是不同城市的各列计数结果,因为没有NaN,每列结果都是相等的。现在它和value_counts等价。 step 2 - group by + mean( ) 换成mean,计算出了不同城市的平均薪资。 因为mean方法只针对数值,而各列中只有avgSalary是数值,于是返回了这个唯一结果。
step 3 group by (双条件)+ mean( ) groupby可以传递一组列表,这时得到一组层次化的Series。按城市和学历分组计算了平均薪资。
step 4 - group by (双条件)+ mean( ) + unstack () 再调用unstack方法,进行行列转置,这样看的就更清楚了
在不同城市中,博士学历最高的薪资在深圳,硕士学历最高的薪资在杭州。北京综合薪资最好。这个分析结论有没有问题呢?不妨先看招聘人数。 这次换成count,我们在groupby后面加一个avgSalary,说明只统计avgSalary的计数结果,不用混入相同数据。 要求博士学历的岗位只有6个,所谓的平均薪资,也只取决于公司开出的价码, 波动性很强,毕竟这只是招聘薪资,不代表真实的博士在职薪资。 这也解释了上面几个图表的异常。
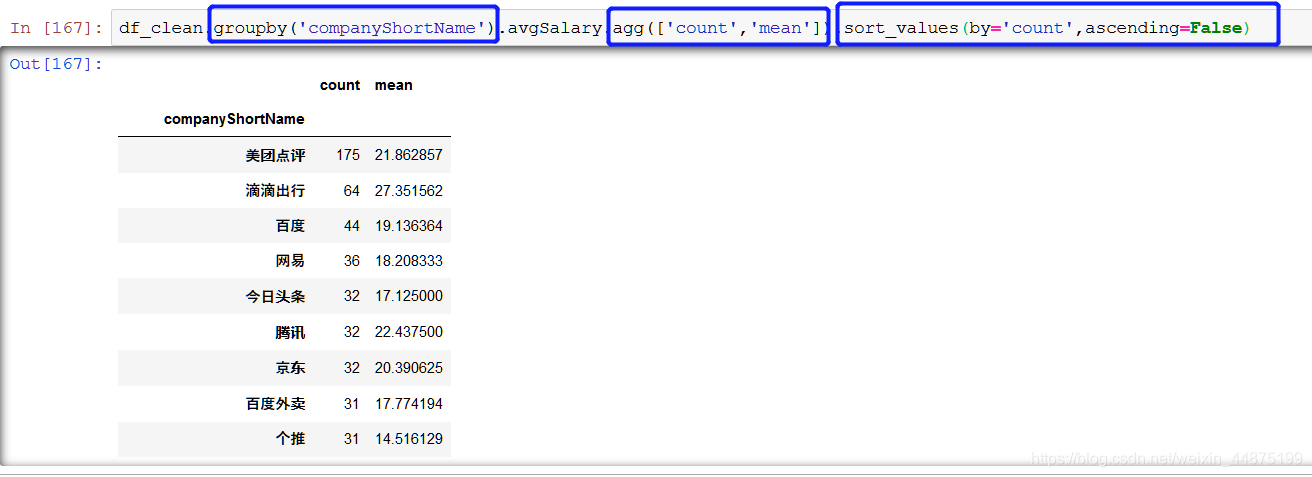
step 5 - (计算不同公司的招聘数据师数量 & 计算平均数) 使用的函数: agg()函数 https://blog.csdn.net/suzyu12345/article/details/50733932 agg除了系统自带的几个函数,它也支持自定义函数。
sort_value()函数 https://blog.csdn.net/wendaomudong_l2d4/article/details/80648633 apply( )函数
这里使用了agg函数,同时传入count和mean方法,然后返回了不同公司的计数和平均值两个结果。
step6 (计算出不同城市,招聘数据分析师需求前5的公司,应该如何处理?) 自定义了函数topN,将传入的数据计数,并且从大到小返回前五的数据。 然后以city聚合分组,因为求的是前5的公司,所以对companyShortName调用topN函数。
step8 (想知道不同城市,各职位招聘数前五,也能直接调用topN) 可以看到,虽说是数据分析师,其实有不少的开发工程师,数据产品经理等。 这是抓取下来数据的缺点,它反应的是不止是数据分析师,而是数据领域。不同城市的需求不一样,北京的数据产品经理看上去要比上海高。
接下来继续mark可视化 单维度条形图 使用函数 plot.bar( ) https://blog.csdn.net/Jinlong_Xu/article/details/70183377 ??? plot.bar( )是不是只适用于 dataFrame
双维度条形图 重要函数: unstack( ) 行列装置 刚开始运行下面的代码时候,显示error: name 'figsize' is not defined. 解决方案就是:Try using [ %pylab ] if 【%matplotlib inline】 does not work. 在前面加了%pylab 就ok了 参考链接:https://stackoverflow.com/questions/23762238/python-pandas-figsize-not-defined
运用group by,我们已经能随意组合不同维度。 下面这个函数中的 mean()求的是同样的city里面,不同教育背景的均值。
直接调用matplotlib的函数,进行更自由的可视化。(它和pandas及numpy是兼容的) 了解下面参数的意思 使用函数: plt.hist( ) 其中参数
x - (n,) array or sequence of (n,) arrays. 这个参数是指定每个bin(箱子)分布的数据,对应x轴 bins - integer or array_like, optional. 这个参数指定bin(箱子)的个数,也就是总共有几条条状图. 默认为10 normed -boolean, optional. If True, the first element of the return tuple will be the counts normalized to form a probability density, i.e.,n/(len(x)`dbin)这个参数指定密度,也就是每个条状图的占比例比,默认为0。 normed: 是否将得到的直方图向量归一化。默认为0 ps: normed='true' 和 normed='False'做出来的图跟 normed=1做出来的图一样的。 ??根据查到的解释, normed=ture表示频率图,默认是频数图。那纵坐标应该有点区别才对?? ormed=True是频率图,默认是频数图facecolor - 直方图颜色 alpha - 透明度 另外还有一个疑问: 1. 代码里面只设置了blue & red两种颜色,为什么会出来3种颜色? 另外橙色颜色个代表什么?
下面的直方图是 norm=0,没有归一化。可以看到因为北京和上海的分析师人数相差较远,所以无法直接对比,需要用normed参数转化为密度
另外一种分析思路是对数据进行深加工。我们将薪资设立出不同的level 使用函数: cut() 参数解释: https://blog.csdn.net/cc_jjj/article/details/78878878 延伸参考:https://blog.csdn.net/geekmubai/article/details/86676313 https://blog.csdn.net/weixin_42398658/article/details/82936525 cut的作用是分桶,它也是数据分析常用的一种方法,将不同数据划分出不同等级,也就是将数值型数据加工成分类数据,在机器学习的特征工程中应用比较多。cut可以等距划分,传入一个数字就好。这里为了更好的区分,我传入了一组列表进行人工划分,加工成相应的标签。 这里有点像用excel制作直方图,先人工订好组宽。不过这里的组宽不是等距的。大概是作者根据经验定下的组距。
抽取df_clean表格里面的avgSalary 跟 level column看下
下面也是进行绘制柱状图,不过跟前面的不太一样。是将数据转换成了百分比再进行绘制图。 下面的是运用group by ,组合了city和Level的维度, 另外,函数的 plot.bar( )里面的参数 stacked = True,值得是条状图叠加。 如果改为stacked=False的话,得出来的条状图就不会叠加的。
下面显示 de_level:
注意使用 unstack()进行 行列装置,如果没有unstack()的话,出来的结果是下面这个
axis是apply中的参数,axis=1表示将函数用在行,axis=0则是列。 当axis=1时,x.sum()指的是x所在行的总和。每行的百分比相加得1 当axis=0时,x.sum()指的是x所在列的总和。每列的百分比相加得1
最后绘制柱状图。如下图所示。 这里可以较为清晰的看到不同等级在不同地区的薪资占比。它比箱线图和直方图的好处在于,通过人工划分,具备业务含义。0~3是实习生的价位,3~6是刚毕业没有基础的新人,整理数据那种,6~10是有一定基础的,以此类推。
如果把代码中的axis改为0的话,就是将lambda运用在列上面。 后面出来的图如下: axis=0,按照column来算百分比的话,就跨越了城市,没办法清晰对比同个city,不同薪资水平所占的百分比了。
--------------------------------------------------------- 终于来到最后一步了 ---- 制作词云图。 使用函数: str.replace() str.split() dropna() - 该函数主要用于滤除缺失数据。
首先把词云图的原材料准备好。
去除中括号 [ ] 现在的目的是统计数据分析师的标签。它只是看上去干净的数据,元素中的[ ]是无意义的,它是字符串的一部分,和数组没有关系。df_clean.positionLables是Series,并不能直接套用replace。apply是一个好方法,但是比较麻烦。这里需要str方法。
采用str方法,str方法允许我们针对列中的元素,进行字符串相关的处理,这里的[1:-1]不再是DataFrame和Series的切片,而是对字符串截取,这里把[ ]都截取掉了。如果漏了str,就变成选取Series第二行至最后一行的数据,切记。 去除空格键 使用完str后,它返回的仍旧是Series,当我们想要再次用replace去除空格。还是需要添加str的。
在这一步试了好久,一开始,使用replace(' ','')的时候,返回的结果全部都是空的。后来先是使用find函数先找出空格的索引,然后再删掉find函数,继续使用replace函数进行空格置换。positionLables本身有空值,所以要删除,不然容易报错。 拆分成列表 & 过滤缺失数据
再次用str.split方法,把元素中的标签按「,」拆分成列表。 这里是重点,通过apply和value_counts函数统计标签数。因为各行元素已经转换成了列表,所以value_counts会逐行计算列表中的标签,apply的灵活性就在于此,它将value_counts应用在行上,最后将结果组成一张新表。
用unstack完成行列转换(为什么要进行行列转换???),看上去有点怪,因为它是统计所有标签在各个职位的出现次数,绝大多数肯定是NaN。
将空值删除,并且重置为DataFrame,此时level_0为标签名,level_1为df_index的索引,也可以认为它对应着一个职位,0是该标签在职位中出现的次数,之前我没有命名,所以才会显示0。部分职位的标签可能出现多次,这里忽略它。
用groupby计算出标签出现的次数
anaconda没有,需要先pip install wordcloud。一步安装成功, 没有出现error 首先载入WordCloud:
清洗掉标签里的引号‘ ’
设置词云相关的参数
然后 duang ~ duang ~ duang~
|























 (箱线图的详解可以参考 - https://blog.csdn.net/Arwen_H/article/details/84855825)
(箱线图的详解可以参考 - https://blog.csdn.net/Arwen_H/article/details/84855825)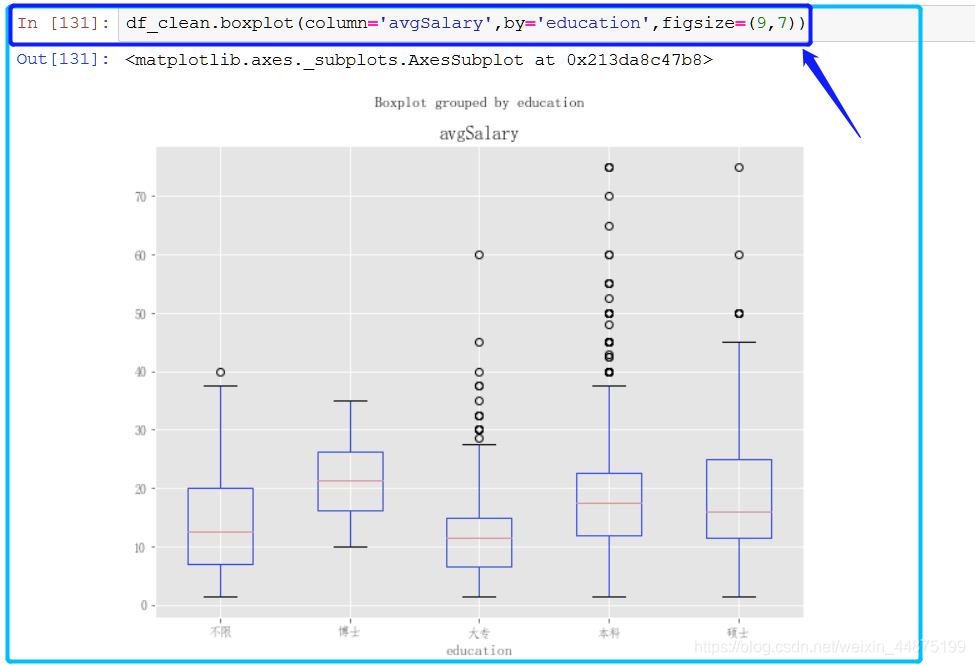
































 制作云图,需要第三方软件 - wordcloud.
制作云图,需要第三方软件 - wordcloud.


【本文地址】