知识图谱学习笔记(三) |
您所在的位置:网站首页 › 逻辑表示法可以用来表示数据吗 › 知识图谱学习笔记(三) |
知识图谱学习笔记(三)
|
知识表示方法
1.概述
1.1 知识分类
陈述性知识:用于描述领域内有关概念、事实、事务的属性和状态等。 1.太阳从东方升起 2.一年有春夏秋冬四个季节过程性知识:用于指出如何处理与领域相关的信息,以求得问题的解。例如: 1.菜谱中的炒菜步骤 2.如果信道畅通,请发绿色信号元知识:关于知识的知识,包括怎样使用规则、解释规则、校验规则、解释程序结构等知识。
1.2 知识表示
知识表示可看成是一组事务的约定,以把人类知识表示成机器能处理的数据结构。对知识进行表示的过程就是把知识编码成某种数据结构的过程。 知识表示方法分为: 陈述性知识表示:将知识表示与知识的运用分开处理,在知识表示时,并不涉及如何运用知识的问题,是一种静态的描述方法。过程性知识表示:将知识表示与知识的运用相结合,知识寓于程序中,是一种动态的描述方法。 1.3 知识表示准则 表示知识的范围是否广泛是否适于推理是否适于加入启发信息是否适于计算机处理是否有高效的求解算法陈述性表示还是过程性表示能够表示不精确知识能够在同一层次上和不同层次上模块化知识和元知识能够用统一的形式表示表示方法是否自然 2. 一阶谓词逻辑表示法一阶谓词逻辑以树立逻辑为基础,是到目前为止能够表达人类思维和推理的一种最精确的形式语言。其表现方式和人类自然语言也非常接近,容易为计算机理解和操作,并支持精确推理。 基本概念 命题:具有真假意义的陈述句。逻辑联结词:用于将多个原子命题组合成复合命题。(包括否定、合取、析取、蕴含、等价联结词)个体词:领域内可以独立存在的具体或抽象的客体。在谓词逻辑中,个体可以是常量也可以是变量(变元) 1.个体常量:表示具体的或特定的个体 2.个体变量:表示抽象的或泛指的个体 3.个体域(论域):个体变量的取值范围,可以是有限集合,也可以是无穷集合。谓词:用来刻画个体性质以及个体之间相互关系的此。 eg:命题:x是有理数。其中x是个体变量,“……是有理数”是谓词,几维Rational,命题符号化为Rational(x)。n元谓词:含有n个个体符号的谓词 P ( x 1 , x 2 , . . . , x n ) P(x_1,x_2,...,x_n) P(x1,x2,...,xn)函数:又称函词,是从若干个个体到某个个体的映射。 eg:Sun(1,2)表示1与2的加和。谓词与函数的区别: 1.谓词实现的是从个体域中的个体到真或假的映射,而函数实现的是从个体域中的一个个体到另一个个体的映射,无真值可言。 2.在谓词逻辑中,函数本身不能单独使用它必须嵌入到谓词中。量词:是表示个体数量属性的词。包括全称量词和存在量词。谓词逻辑表示法特性 优点: 1.精确性:可以较准确地表示知识并支持精确推理 2.通用性:拥有通用的逻辑演算方法和推理规则 3.自然性:是一种接近于人类自然语言的形式语言系统。 4.模块化:各条知识相对独立,它们之间不直接发生联系,便于知识的添加、删除和修改。缺点: 1.表示能力差:智能表示确定性知识,不能表示非确定性知识、过程性知识和启发式知识。 2.管理困难:缺乏知识的组织原则,知识库管理困难 3.效率低:把推理演算与知识含义截然分开,往往使推理过程冗长,降低了系统效率。 3.产生式规则表示法产生式系统是用规则序列的形式来描述问题的思维过程,形成求解问题的思维模式。系统中的每一条规则称为一个产生式。目前产生式规则表示法已成为专家系统首选的知识表示方式,也是人工智能中应用最多的一种知识表示方式。 基本概念:事实与规则 事实:断言一个语言变量的值或断言多个语言变量之间关系的陈述句。 eg.路是平的 语言变量:路;语言变量的值:平的确定性事实:一般用三元组的形式表示为(对象,属性,值)或(关系,对象1,对象2)不确定性事实:一般用四元组的形式表示为(对象,属性,值,置信度)(关系,对象1,对象2,置信度)规则:也称为产生式,通常用于表示事物之间的因果关系。确定性规则:通常表示为 p → Q 或 I F P T H E N Q p \rightarrow Q \quad 或\quad IF~ P ~THEN~Q p→Q或IF P THEN Q 1.P是产生式的前提或条件; 2.Q是一组结论或操作,用于指出前提P所指示的条件被满足时,应该得出的结论或应该执行的操作。不确定性规则:通常表示为 P → Q ( 置 信 度 ) 或 I F P T H E N Q ( 置 信 度 ) P \rightarrow Q(置信度) \quad 或 \quad IF~P~THEN~Q(置信度) P→Q(置信度)或IF P THEN Q(置信度) 1.P是产生式的前提或条件,Q是一组结论或操作。 2.已知事实与前提条件不能精确匹配时,只要按照置信度的要求模糊匹配,再按特定算法将不确定传递到结论。产生式体统结构 正向推理的产生式系统 正向推理:从已知事实出发,通过规则求得结论,也称为数据驱动方式或自底向上的方式。 推理过程: 1.规则库中的规则前件与数据库中的事实进行匹配,得到匹配的规则集合; 2.使用冲突消解算法,从匹配规则集合中选择一条规则作为启用规则; 3.执行启用规则的后件,并将改规则的后件送入数据库;充数上述过程直至达到目标。 示例如下: 框架表示法是以框架理论为基础发展起来的一种结构化知识表示方式,适用于表达多种类型的知识。框架理论认为人们对现实世界中各种事物的认识都是以一种类似于框架的结构存储在记忆当中的,当面临一个新事物时,就从记忆中找出一个适合的框架,并根据实际情况对其细节加以修改补充,从而形成对当前事物的认识。 基本概念 框架(Frame):是一种描述所论对象属性的数据结构 1.框架名:用来指代某一类或某一个对象 2.槽:用来表示对象的某个方面的属性 3.侧面:有时一个属性还要从不同侧面来描述。 4.槽/侧面的取值,可以为原子型,也可以为集合型。 框架分为两种类型 : 1.类框架:用于描述一个概念或一类对象 2.实例框架:用于描述一个具体的对象 -框架的层次结构: 1.
子
类
→
s
u
b
c
l
a
s
s
o
f
]
父
类
子类 \xrightarrow{subclass of]} 父类
子类subclassof]
父类:类框架之间的包含关系 2.
实
例
→
i
n
s
t
a
n
c
e
o
f
]
类
实例 \xrightarrow{instance of]} 类
实例instanceof]
类:实例框架和类框架的从属关系。 下层框架可以从上层框架集成某些属性和值。 框架分为两种类型 : 1.类框架:用于描述一个概念或一类对象 2.实例框架:用于描述一个具体的对象 -框架的层次结构: 1.
子
类
→
s
u
b
c
l
a
s
s
o
f
]
父
类
子类 \xrightarrow{subclass of]} 父类
子类subclassof]
父类:类框架之间的包含关系 2.
实
例
→
i
n
s
t
a
n
c
e
o
f
]
类
实例 \xrightarrow{instance of]} 类
实例instanceof]
类:实例框架和类框架的从属关系。 下层框架可以从上层框架集成某些属性和值。
框架示例: 脚本是一种与框架类似的知识表示方法,由一组槽组成,用来表示特定领域内一些时间的发生序列,类似于电影剧本。脚本表示的知识有明确的时间或因果顺序,必须是前一个动作完成后才会触发下一个动作。与框架相比,脚本用来描述一个过程而非静态知识。 脚本组成 进入条件:给出脚本中所描述时间的前提条件。角色:用来描述实践中可能出现的人物。道具:用来描述事件中可能出现的相关物体。场景:用来描述事件发生的真实顺序。一个事件可以由多个场景组成,而每个场景又可以是其它事件的脚本。结果:给出在脚本所描述事件发生以后所产生的结果。示例 语义网的概念来源于万维网,是万维网的变革与延伸,是Web of documents向Web of data的转变,其目标是让机器或设备能够自动识别和理解万维网上的内容,使得高效的信息共享和机器智能协同成为可能。 简介 本质:以Web数据的内容(即语义)为核心,用机器能够理解和处理的方式链接起来的海量分布式数据库。 特征: 1.Web上的事物拥有唯一的URI 2.事物之间由链接关联。 3.事物之间链接显式存在并拥有不同类型 4.Web上事物的结构显式存在 语义网提供了一套为描述数据而设计的表示语言和工具,用于形式化的描述一个知识领域内的概念、术语和关系 第一层:Unicode和URI(uniform resource identifier),是整个语义网的基础,Unicode处理资源的编码,实现网上信息的统一编码;URI负责标识资源,支持网上对象和资源的惊喜标识。 第二层:XML+NS(name space)+XML Schema,用于表示数据的内容和结构,通过XML标记语言将网上资源信息的结构、内容和数据的表现形式进行分离。 第三层:RDF+RDF Schema,用于描述网上资源及其类型,为网上资源描述提供一种通用框架和实现数据集成的元数据解决方案。 第四层:Ontology,用于描述各种资源之间的联系,揭示资源本身及资源之间更为复杂和丰富的语义联系,明确定义描述属性或类的术语语义及术语间关系。 第五层:逻辑层,主要提供公理和推理规则,为智能推理提供基础,该层用来产生规则。 第六层:证明层,执行逻辑层产生的规则,并结合信任层的应用机制来评判是否能够信赖给定的证明。 第七层:信任层,注重于提供信任机制,以保证用户代理在网上进行个性化服务和彼此间交互合作时更安全可靠。 XML,RDF和Ontology为核心层,用于表示信息的语义 RDF,资源描述框架,是一种资源描述语言,利用当前的多种元数据标准来描述各种网络资源,形成人机可读,并可由机器自动处理的文件。 RDF核心思想:利用Web标识符来标识事物,通过指定的属性和相应的值描述资源的性质或资源之间的关系。 RDF的基本数据模型包括资源(resource)、属性(property)和陈述(statement)。 陈述:特定的资源加上一个属性和相应的属性值就是一个陈述,其中资源是主题,属性是谓词,属性值是客体。 Ontology 本体通过对概念的严格定义和概念与概念之间的关系来确定概念的精确含义,表示共同认可的、可共享的知识。在语义网中,ontology具有非常重要的地位,是解决语义层次上Web信息共享和交换的基础 本体的定义: 哲学界:对世界上客观存在物的系统地描述,即存在论。 工业界:Studer:本体是共享概念模型的明确的形式化规范说明。 1.概念模型(conceptualization):本体是通过抽象客观世界的概念而得到的模型,其表示的含义独立于具体的环境状态。 2.明确性(explicit):本体所使用的概念及使用这些概念的约束都有明确的定义,没有二义性。 3.形式化(formal):本体是计算机可处理的,而非自然语言。 4.共享(shared):本体体现的是共同认可的知识,反映的是相关领域中公认的概念集合,它所针对的是团体而非个体。 本体的组成:O={C, R, F, A, I} 概念(concept)或类(class),关系(relation),函数(function),公理(axiom),实例(instance) 7.知识图谱概念起源知识图谱的概念最早出现于Google公司的知识图谱项目,体现在使用Google搜索引擎时,出现于搜索结果右侧的相关知识展示。 实体(entity):现实世界中可区分、可识别的事物或概念 关系(relation):实体和实体之间的语义关联 事实(fact):陈述两个实体之间关系的断言,通常表示为(head entity, relation, tail entity)三元组形式。 狭义知识图谱:具有图结构的三元组知识库。 知识库中的实体作为知识图谱中的节点。 知识库中的事实作为知识图谱中的边,边的方向由头实体指向尾实体,边的类型就是两实体间关系类型。 知识图谱不太专注于对知识框架的定义,而专注于如何以工程的方式,从文本中自动抽取或依靠众包的方式获取并组件广泛的、具有平铺结构的知识实例,最后再要求使用它的方式具有容错、模糊匹配等机制。 知识图谱的真正魅力在于其图结构,可以在知识图谱上运行搜索、随机游走、网络流等大规模图算法,使知识图谱与图论、概率图等碰撞出火花。 8. 分布式知识表示 核心思想:将符号化的实体和关系在低维连续向量空间进行表示,在简化计算的同时最大程度保留原始的图结构。 1.将实体和关系在向量空间进行表示(向量/矩阵/张量)。 2.定义打分函数,衡量每个三元组成立的可能性。 3.构造优化问题,学习实体和关系的低维连续向量表示。 方法类型: 1.位移距离模型(translational distance models):采用基于距离的打分函数来衡量三元组成立的可能性。 2.语义匹配模型(semantic matching models):采用基于相似度的打分函数来衡量三元组成立的可能性。 方法类型: 1.位移距离模型(translational distance models):采用基于距离的打分函数来衡量三元组成立的可能性。 2.语义匹配模型(semantic matching models):采用基于相似度的打分函数来衡量三元组成立的可能性。
参考:Wang et al. Knowledge Graph Embedding: A Survey of Approaches and Applications. IEEE TKDE, to appear, 2017. https://ieeexplore.ieee.org/document/8047276 小结 XML: 提供了一种结构化文档的表层语法,但没有对文档含义施加任何语义约束。https://www.w3.org/XML/RDF:是一种关于对象(资源)和它们之间关系的数据模型,该模型具备简单语义,能够用XML语法表示。https://www.w3.org/TR/rdf-concepts/RDF Schema:十一组描述RDF资源的类和属性的建模原语,提供了关于这些类和属性的层次结构的语义。https://www.w3.org/TR/rdf-schema/OWL:添加了更多用于描述类和属性的建模原语,支持更加丰富的语义表达并支持推理。https://www.w3.org/TR/2004/REC-owl-ref-20040210/ |
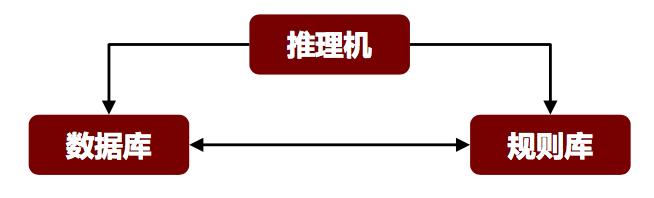 产生式系统由数据库、规则库和推理机三部分组成。
产生式系统由数据库、规则库和推理机三部分组成。
 反向推理的产生式系统 反向推理:从目标出发,反向使用规则,求得已知事实,也称为目标驱动方式或自顶向下的方式。 推理过程: 1.规则库中的规则后件与目标事实进行匹配,得到匹配的规则集合; 2.使用冲突消解算法,从匹配规则集合中选择一条规则作为启用规则; 3.将启用规则的前件作为字母表; 重复上述过程。
反向推理的产生式系统 反向推理:从目标出发,反向使用规则,求得已知事实,也称为目标驱动方式或自顶向下的方式。 推理过程: 1.规则库中的规则后件与目标事实进行匹配,得到匹配的规则集合; 2.使用冲突消解算法,从匹配规则集合中选择一条规则作为启用规则; 3.将启用规则的前件作为字母表; 重复上述过程。 



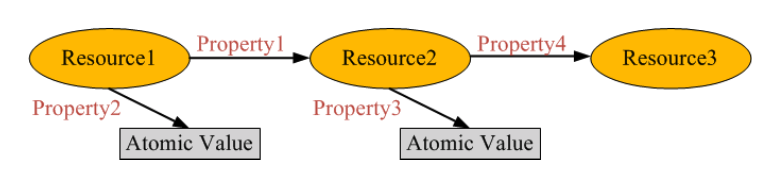 RDFS是RDF的扩展,它在RDF的基础上提供了一组建模原语,用来描述类、属性以及它们之间的关系。 1.Class, subClassOf:描述类别层次结构。 2.Property,subPropertyOf:描述属性层次结构。 3.domain,range:声明属性所应用的资源类和属性值类。 4.type:声明一个资源是一个类的实例。
RDFS是RDF的扩展,它在RDF的基础上提供了一组建模原语,用来描述类、属性以及它们之间的关系。 1.Class, subClassOf:描述类别层次结构。 2.Property,subPropertyOf:描述属性层次结构。 3.domain,range:声明属性所应用的资源类和属性值类。 4.type:声明一个资源是一个类的实例。 

【本文地址】