VALSE 2024年度进展评述内容分享 |
您所在的位置:网站首页 › 赵恒煊的老婆照片 › VALSE 2024年度进展评述内容分享 |
VALSE 2024年度进展评述内容分享
|
2024年视觉与学习青年学者研讨会(VALSE 2024)于5月5日到7日在重庆悦来国际会议中心举行。本公众号将全方位地对会议的热点进行报道,方便广大读者跟踪和了解人工智能的前沿理论和技术。欢迎广大读者对文章进行关注、阅读和转发。文章是对报告人演讲内容的理解或转述,可能与报告人的原意有所不同,敬请读者理解;如报告人认为文章与自己报告的内容差别较大,可以联系公众号删除。 香港大学的赵恒爽教授对视觉基础大模型的年度进展进行了总结,并做了精彩报告,下面对该报告的内容进行介绍。文中的图片均来自于该报告。 1.报告人简介 赵恒爽博士是香港大学计算机科学系的助理教授,他的研究方向涵盖计算机视觉、机器学习和人工智能等广泛的领域。 2.内容概览 随着大型语言模型的快速发展,其在图像识别、场景理解和视觉内容生成等方面的应用正受到越来越多的关注。研究者们正在尝试将这些先进的语言模型技术转化为视觉领域的创新工具,以解决更复杂的视觉认知任务。赵老师从图像分割、大型视觉语言模型(Large Vision-Language Models, LVLM)、视频基础模型几个方向出发,回顾了相关的研究进展。 3.内容整理 (1)图像分割 赵老师首先介绍了名为Segment Anything Model(SAM)的模型,如图1所示。与先前模型具有的单任务、单领域、闭集、单提示类型等局限性相比,SAM具有以下三项优势:1)用于分割的统一并且通用的界面:掩码、点、框、文本;2)数据引擎扩展:超过10亿个掩码,1100万张图片;3)强大的泛化能力:甚至适用于航拍图片、合成图片和医学图片。
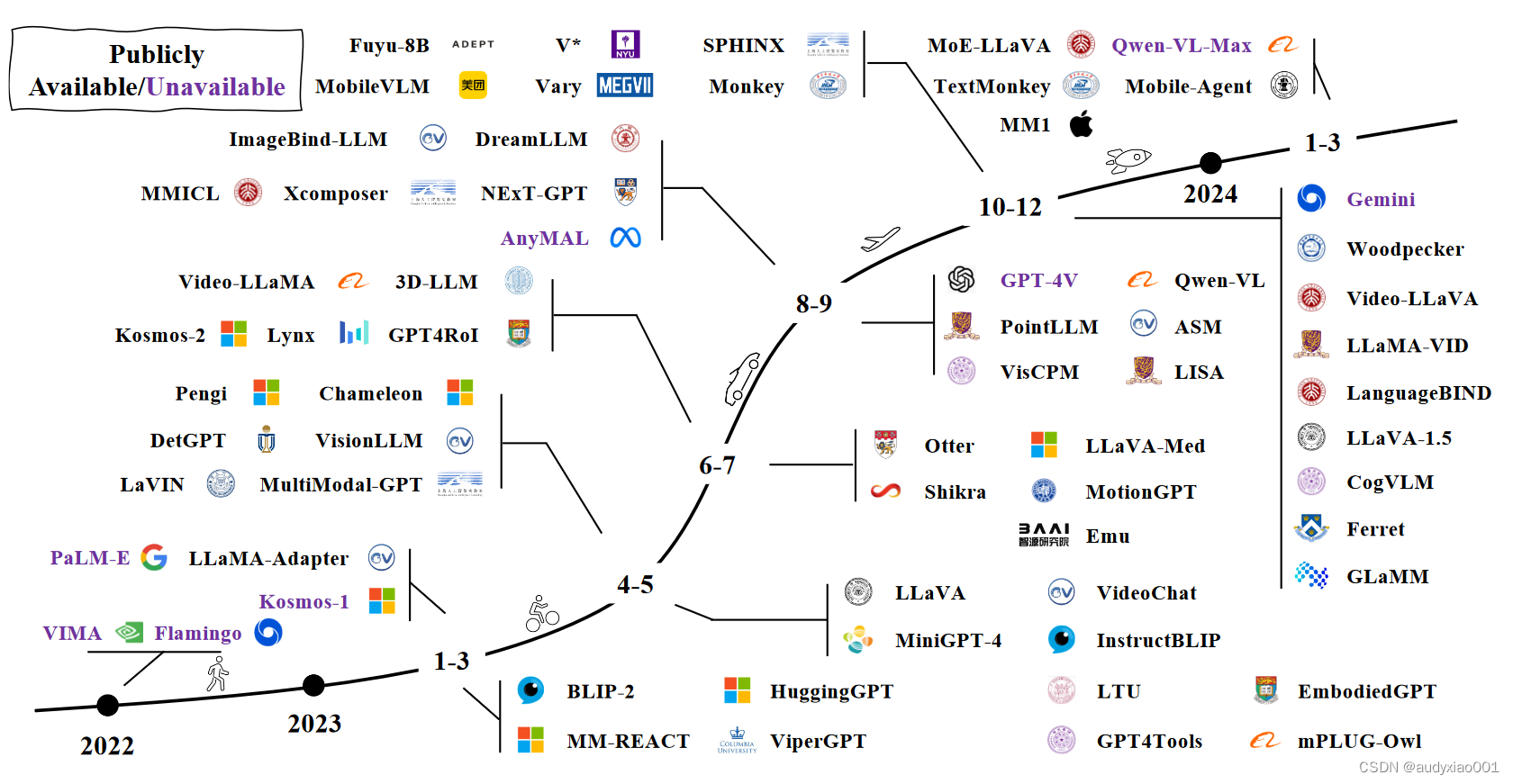
图 1 Segment Anything Model 随后,赵老师提到了SegGPT,这是一种专注于图像分割的模型。它融合了自然语言处理技术。通过对分割任务的上下文色彩处理,SegGPT继承了传统绘画技术中的一些特点,并专注于图像中对象的精确分割。该模型利用语言提示来指导分割过程,能够有效地解析和响应复杂的图像内容,使其在处理多样化的视觉数据方面显示出高度的灵活性和准确性。 在本部分的最后,赵老师还列举了SAM的更多拓展方法,例如:Inpaint Anything [arXiv:2304.06790],Anvthing-3D [arXiv:2304.10261],Track Anything [arXiv:2304.11968],MedSAM [arXiv:2304.12306],Caption Anything [arXiv:2305.02677],PerSAM [arXiv:2305.03048],SAM-Track [arXiv:2305.06558],Matcher [arXiv:2305.13310],Recognize Anything [arXiv:2306.03514],HQ-SAM [arXiv:2306.01567],SAM3D [arXiv:2306.039081],FastSAM [arXiv:2306.12156]等。注:[ ]内为arXiv网站上文章的编号,读者可以到arXiv网站输入此编号搜索对应的论文,详细了解相应的方法。 (2)大型视觉模型 LVLM是一种多模态大型语言模型(Multimodal Large Language Models, MLLMs),能够处理并理解视觉(如图像、视频)与语言(文本)的综合信息。这类模型通过深度学习技术来执行复杂的任务,如图像标注、视觉问答和图像生成等。LVLM的关键在于它们能够跨越视觉和语言的界限,提供更加丰富和准确的信息理解与生成能力。MLLMs的发展历程如图2所示。
图 2具有代表性的MLLMs发展历程 LVLM具有多种多样的应用场景,包括但不限于:文档(TextMonkey、Ureader、TinyChart、OtterHD、DocOwl等)、智能体/用户界面(CogAgent、AppAgent、Mobile-Agent、Ferret-UI等)、医疗(BiomedGPT、Med-Flamingo、PMC-VQA、LLava-Med、Qilin-Med-VL等)、自动驾驶(DriveGPT4、DriveLM、LMdrive、BEV-InMLLM、GPT-Driver等)。 (3)视频基础模型 视频基础模型用于视频处理和分析。这类模型能够理解和解释视频内容,实现诸如视频分类、活动识别、内容检索等功能。视频基础模型通常包括对视频帧的序列化处理,利用深度学习技术捕捉时间和空间上的信息。此外,这些模型也常用于视频生成和编辑,如生成符合特定要求的视频片段或改善视频质量。 以InternVideo2为例,它的训练分为3个阶段,包括无遮挡视频令牌重建、多模态对比学习和大型语言模型联合训练,如图3所示。在阶段1中,视频编码器从头开始训练,而在阶段2和3中,它通过上一阶段使用的版本进行初始化。
图 3 InternVideo2训练步骤 InternVideo2在70个视频理解任务中产生了强大的可迁移的视觉和视觉-语言表征,包括动作识别、视频-文本理解和以视频为中心的对话。此外它还具有长形式视频理解和过程感知推理的能力。 |


【本文地址】