决策树(回归) |
您所在的位置:网站首页 › 费尔曼链码结构是什么 › 决策树(回归) |
决策树(回归)
|
回归树重要参数,属性,接口
决策树(回归)和决策树(分类)的参数,属性和接口基本是一样的。 sklearn里面的计算都是不能够干涉的,它会自己按照公式计算。 回归树衡量分支质量的指标有三种: 1)mse均方差 2)‘friedman_mse’费尔曼德均方误差 3)‘mae’绝对平均误差 属性最重要的依然是‘feature_importances_’,接口依然是‘apply’,‘fit’,‘score’,‘predict’最为核心。 在回归树中,MSE不只是我们的分支质量衡量标准,也是我们最常用的衡量回归树回归质量的指标。 当我们在使用交叉验证,或者其他方法获取回归树结果时,我们往往选择均方误差作为我们的评估(在分类树中这个指标是score代表的是预测准确率)。在回归中,我们追求的是,MSE越小越好。 然而,回归树的接口score返回的是R平方,并不是MSE。R平方被定义如下: 交叉验证是用来观察模型稳定性的一种方法,我们将数据分为n份,依次使用1份作为验证集,其他n-1份作为测试集,多次计算模型的精确性来评估模型的平均准确程度。 训练集和测试集的划分会干扰模型的结果,因此使用交叉验证n次的结果求出的平均值,是对模型效果更好的一个度量。
#scoring=‘neg_mean_squared_error’ ,指标是负均方误差,绝对值越小越好。 #不写scoring时,默认是以R平方作为指标,越接近1越好。 回归树的实例(一维回归的图像绘制) #1.导入需要的库 %matplotlib inline import numpy as np import matplotlib.pyplot as plt from sklearn.tree import DecisionTreeClassifier #2.创建一个含有噪声的正弦曲线 rng=np.random.RandomState(1) #随机数种子 x=np.sort(5*rng.rand(80,1),axis=0) #生成0-5之间的随机的x的取值 y=np.sin(x).ravel() #生成正弦曲线 y[::5]+=3*(0.5-rng.rand(16)) #在正弦曲线上加噪声 #画图玩玩 plt.figure() plt.scatter(x,y,edgecolor='black',c='red',label='data',linewidth=2) plt.legend() plt.show() #3.实例化&训练模型 regr_1=DecisionTreeRegressor(max_depth=2) regr_2=DecisionTreeRegressor(max_depth=5) regr_1=regr_1.fit(x,y) regr_2=regr_2.fit(x,y) #4.测试集导入模型,预测结果 x_test=np.arange(0,5,0.01)[:,np.newaxis] y_1=regr_1.predict(x_test) y_2=regr_2.predict(x_test) #np.arange(开始点,结束点,步长) #了解增维切片np.newaxis的用法 a=np.array([1,2,3,4]) a[:,np.newaxis] a[np.newaxis.:] #5.绘制图像 plt.figure() plt.scatter(x,y,edgecolor='black',c='red',label='data') plt.plot(x_test,y_1,c='red',label='max_depyh=2',linewidth=2) plt.plot(x_test,y_2,c='yellowgreen',label='max_depth=5',linewidth=2) plt.xlabel('data') plt.ylabel('target') plt.title('Decision Tree Regression') plt.legend() plt.show()
|
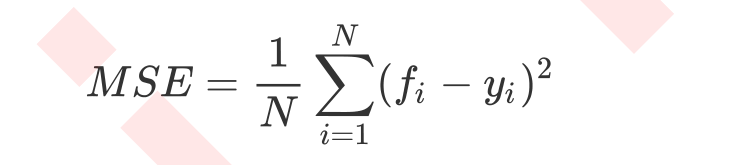


 可见,回归树学习了近视正弦曲线的局部线性回归。我们可以看到,如果树的最大深度(由max_depth参数控制)设置太高,则决策树学习得太精细,它从训练数据中学到了很多细节,包括噪声的呈现,从而使模型偏离真实的正弦曲线,形成过拟合。
可见,回归树学习了近视正弦曲线的局部线性回归。我们可以看到,如果树的最大深度(由max_depth参数控制)设置太高,则决策树学习得太精细,它从训练数据中学到了很多细节,包括噪声的呈现,从而使模型偏离真实的正弦曲线,形成过拟合。【本文地址】
今日新闻 |
推荐新闻 |