深度探索:朴素贝叶斯算法在机器学习中的原理与应用 |
您所在的位置:网站首页 › 贝叶斯定理应用在哪些方面 › 深度探索:朴素贝叶斯算法在机器学习中的原理与应用 |
深度探索:朴素贝叶斯算法在机器学习中的原理与应用
|
1.引言与背景
朴素贝叶斯算法,以其简洁高效的特点,成为了机器学习领域广泛应用的一种经典分类算法。这个名称中的“朴素”,源自其对特征之间独立性的简化假设,虽然在实际问题中这种完全独立的情况并不多见,但这恰恰使得朴素贝叶斯能够在面临高维度数据时依然保持快速且相对准确的分类能力。追溯其历史,朴素贝叶斯算法起源于贝叶斯统计学,随着计算机科学的发展和大数据时代的到来,它的实用性和有效性在诸多领域得到了充分验证。 2.贝叶斯定理贝叶斯定理是朴素贝叶斯算法的基石,其数学表达为 朴素贝叶斯分类器的核心思想是在给定一组特征的情况下,计算各个类别出现的可能性,然后选择可能性最大的类别作为预测结果。其关键之处在于“朴素”假设,即所有特征相互独立,从而将复杂的多维条件概率简化为单个特征的条件概率的乘积。不同类型的朴素贝叶斯算法针对不同类型的特征进行了优化,例如多项式朴素贝叶斯用于处理计数型数据,伯努利朴素贝叶斯适用于二元特征,而高斯朴素贝叶斯则适合连续数值型特征的处理。 4.算法实现在实施朴素贝叶斯算法时,首先需进行必要的数据预处理,如特征缩放、编码转换和缺失值处理等。接下来是参数估计阶段,通常采用极大似然估计或者贝叶斯估计来获取特征条件概率。分类过程分为两步:训练阶段基于训练集估计各类别的先验概率和条件概率,预测阶段则通过计算待分类样本属于各个类别的后验概率来进行分类决策。 以下是一个简单的Python实现朴素贝叶斯分类器的例子,这里使用的是sklearn库中的GaussianNB类,用于处理连续型数据的高斯朴素贝叶斯算法: from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn import metrics # 加载数据集 iris = load_iris() X = iris.data y = iris.target # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) # 创建高斯朴素贝叶斯分类器对象 gnb = GaussianNB() # 使用训练数据训练模型 gnb.fit(X_train, y_train) # 预测测试集的结果 y_pred = gnb.predict(X_test) # 计算模型准确率 accuracy = metrics.accuracy_score(y_test, y_pred) print(f"Accuracy: {accuracy}") # 输出混淆矩阵 confusion_matrix = metrics.confusion_matrix(y_test, y_pred) print(f"Confusion Matrix:\n{confusion_matrix}")这段代码首先加载了鸢尾花数据集,然后将其划分为训练集和测试集。接着创建了一个高斯朴素贝叶斯分类器,并用训练集对其进行训练。训练完成后,对测试集进行预测,并计算模型的预测准确率。最后输出了混淆矩阵以评估模型的分类效果。 如果你想要实现一个多项式朴素贝叶斯分类器(适用于计数型数据,比如词频数据),可以替换为MultinomialNB类: from sklearn.naive_bayes import MultinomialNB # 创建多项式朴素贝叶斯分类器对象 mnb = MultinomialNB() # 其他步骤与上面的高斯朴素贝叶斯相同... mnb.fit(X_train, y_train) y_pred = mnb.predict(X_test) accuracy = metrics.accuracy_score(y_test, y_pred) print(f"Accuracy: {accuracy}")注意,实际应用中,数据可能需要根据特征类型和算法要求进行适当的预处理。对于文本分类任务,通常会进行词汇表构建、TF-IDF转换或者其他文本特征提取步骤。对于数值型数据,也可能需要进行标准化或归一化等预处理工作。 5.优缺点分析朴素贝叶斯算法的优点显著,包括: 学习效率高:只需要计算特征的条件概率,无需复杂的迭代过程;对缺失数据不敏感:即使某些特征值缺失,也可以依据其他特征进行分类;易于理解和实现:理论清晰,实现代码简洁,易于移植和部署。然而,其主要缺点也源于“朴素”假设: 特征条件独立假设过于简化,实际数据中特征间可能存在依赖关系,这可能导致模型性能受限;对于输入噪声非常敏感,因为错误的特征观测值可能会严重影响最终的分类结果。 6.案例应用朴素贝叶斯在众多实际应用中表现出色,例如: 垃圾邮件过滤:通过分析邮件内容中的关键词,有效识别垃圾邮件;情感分析:在社交媒体文本中判断用户的情感倾向;医疗诊断:结合病人的症状和检测指标,辅助医生进行疾病诊断;文档分类:广泛应用于新闻分类、网页主题分类等任务。 7.对比与其他算法相较于决策树、K近邻、逻辑回归和支持向量机等其他分类器,朴素贝叶斯算法在速度上有明显优势,尤其在处理大规模数据时表现优异。然而,由于其严格的独立性假设,当面对高度相关特征时,其准确性可能不如其他更为复杂的非线性模型。 8.结论与展望朴素贝叶斯算法凭借其简洁易用、训练速度快等特点,在许多场景下仍不失为一个理想的选择。随着机器学习研究的不断深入,研究人员正致力于通过引入半朴素贝叶斯或其他改进策略,以克服独立性假设的局限性。未来,朴素贝叶斯算法将继续发展和完善,结合现代计算技术和新的概率模型,有望在更多复杂和大数据驱动的应用中发挥重要作用。 |
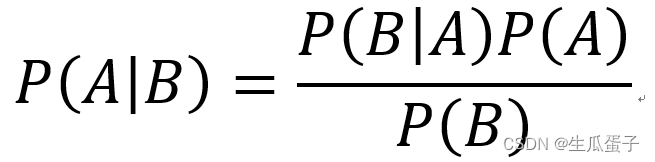 其中 A 和 B 表示两个事件。在分类问题中,我们关注的是在已知特征 B 的情况下,目标类别 A 的后验概率。朴素贝叶斯算法正是巧妙地利用贝叶斯定理来推断未知样本所属的类别。
其中 A 和 B 表示两个事件。在分类问题中,我们关注的是在已知特征 B 的情况下,目标类别 A 的后验概率。朴素贝叶斯算法正是巧妙地利用贝叶斯定理来推断未知样本所属的类别。【本文地址】