编译原理 |
您所在的位置:网站首页 › 语法分析的两种方法包括 › 编译原理 |
编译原理
|
一、学习目的
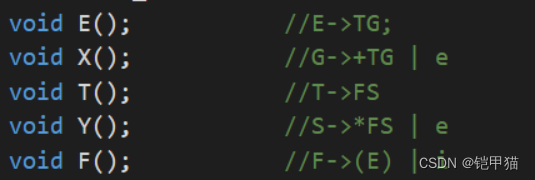
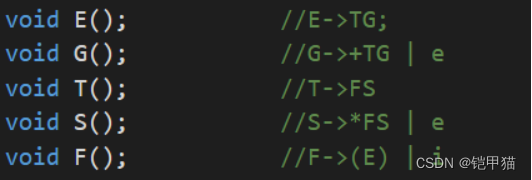
语法分析是编译程序中的核心部分。本次学习通过设计一个典型的自顶向下语法分析程序——LL(1) 语法分析程序或算符优先文法分析,进一步理解并掌握语法分析的原理和实现技术。 二、原理语法分析的主要任务是“组词成句”,将词法分析给出的单词序列按语法规则构成更大的语法单位,如“程序、语句、表达式”等;或者说,语法分析的作用是用来判断给定输入串是否为合乎文法的句子。 按照生成语法树的方向不同,常用的语法分析方法有两类:自顶向下分析和自底向上分析。自顶向下分析也称面向目标的分析方法,也就是从文法的开始符出发,试图推导出与输入单词串相匹配的句子,分为确定的自顶向下分析和不确定的自顶向下分析两种,LL分析法属于确定的自顶向下分析。自底向上分析也称移进 — 归约分析方法,从输入单词串开始,试图归约到文法的开始符。 预测分析法(LL(1)方法)的基本思想是:从文法开始符S 出发,从左到右扫描源程序,每次通过向前查看 1 个字符,选择合适的产生式,生成句子的最左推导。预测分析法有两种实现思路,一种是采用递归思想,针对每个非终结符号构建处理函数。第二种是采用预测分析表的思想,根据当前非终结符和终结符使用产生式进行推导。算符优先分析是一种自下向上的分析方法,首先根据规则构建算符之间的规约优先关系,然后每次对不同串进行规约,直至规约到文法的开始符号。 三、实验说明 3.1学习选题题目:递归分析法设计与实现 3.2实验内容及理解 递归下降分析法是一种自顶向下的语法分析方法,通过递归调用与文法中非终结符对应的子程序,逐步解析输入字符串。分析程序由一组子程序构成,每个非终结符按照其产生式的结构写出相应的子程序,每个子程序对应一个非终结符,且每个子程序的名字用该终结符执行。开始执行时,从文法的开始符号对应的子程序开始,根据文法规则递归调用其他子程序,直到分析完成或发现语法错误。根据分析结果返回匹配情况。 3.3学习目标 LL(1)文法的递归分析法的目标如下: 1.对语法规则有明确的定义;在递归分析法中,文法由程序之间的相互调用形成递归而构成,我们需要在每个子程序中给出该符号的相关选择就可以了 2.编写的分析程序能够进行正确的语法分析; 3.对于遇到的语法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程。 四、设计实现 4.1主要变量及存储结构表1 主要变量表 主要变量 存储结构 作用 str Char类型数组 用于存储输入的字符串 index_a int类型 用于跟踪当前在分析的输入字符串的位置 len int类型 用于存储输入字符串的长度 表 2 函数功能与调用关系 函数名 功能描述 调用关系 E 处理符号 E 的语法规则,即: E->TG 调用 T 和 G G 处理符号 G 的语法规则,即: G->+TG | -TG | e 在符号 ‘+ ’ 或 ‘- ’ 后调 用 T 和 G T 处理符号 T 的语法规则,即: T->FS 调用 F 和 S S 处理符号 S 的语法规则,即: S->*FS | /FS | e 在符号 ‘* ’ 或 ‘/ ’ 后调 用 F 和 S F 处理符号 F 的语法规则,即: F->(E) | i 处理 ‘( ’ 和 ‘) ’,识别’i ’, 判断输入字符串的正确性 4.2算法思路与方法实现 4.2.1算法思路 在main函数中,用户输入一个字符串,并调用 E函数来开始对输入字符串进行分析。 int main() { int len; cin >> str; len = strlen(str); str[len + 1] = '\0'; E(); cout +TG | e { if (str[index_a] == '+'||str[index_a] == '-') { index_a++; T(); X(); } else if(str[index_a] == '#'){ cout *FS| e。当输入字符串当前位置是*或/,则调用F函数,然后递归调用Y函数;当输入字符串的最后一个字符为 '#' 时,意味着输入字符串已经被完整地分析,并且符合了文法规则。此时程序输出当前字符串,并显示它为合法符号串,然后通过 exit(0) 退出程序。 void Y()//S->*FS | e { if(str[index_a]=='*'||str[index_a]=='/'){ index_a++; F(); Y(); } else if(str[index_a] == '#'){ cout ie+FSGE->i+i*FSG E->i+i*iee E->i+i*i 与测试输入相同,为合法符号串 图1 测试集1的运行结果截图 4.3.2 测试数据为i+i/i#预测结果:i+i/i#为合法符号串 分析过程: E->TG E->FS+TG E->ie+FSG E->i+i/FSG E->i+i/iee E->i+i/i 与测试输入相同,为合法符号串
图2 测试集2的运行结果截图 4.3.3测试数据为i+i*#预测结果:非法的符号串! *后没有任何终结符,不符合所给产生式,为非法的符号串 图3 测试集3的运行结果截图 5.1改进设想 5.1.1 命名规范递归下降LL(1)分析程序中的每个非终结符都对应着一个子程序,一般子程序的命名与非终结符是相同的。但是实验平台事先给出的各个子程序的命名与非终结符却不对应,导致在编写代码时十分的别扭,可以把每个子函数的名字都改成与非终结符相同的符号。 图5 平台提供的未与非终结符不一致的子函数命名截图 图6 设想的与非终结符一致的子函数命名截图 #总代码 #include #include #include using namespace std; char str[10]; int index_a = 0; void E(); //E->TG; void X(); //G->+TG | e void T(); //T->FS void Y(); //S->*FS | e void F(); //F->(E) | i int main() { int len; cin >> str; len = strlen(str); str[len + 1] = '\0'; E(); cout |



【本文地址】
今日新闻 |
推荐新闻 |