语音信号处理 |
您所在的位置:网站首页 › 解码器音频失真怎么处理方法 › 语音信号处理 |
语音信号处理
|
语音信号处理二:干净语音的特征提取:
今天的信号与系统,DSP知识点参考 Spoken Language Processing 第5, 6 章 LPC方程的Durbin算法推导:语音信号数字处理(杨行峻,迟惠生)第四章,数字语音处理(Rabiner)第九章 作业是自己实现语音信号的LPC预测算法:输入一段语音信号,选定不同阶数p,在最小二乘准则下,用自相关法估计预测系数 a i a_i ai,对比重建语音和原始语音的时域&短时频谱差别 自相关法可以用普通的矩阵求逆,和Durbin算法做对比。 语音信号的生成模型:激励-滤波模型:

语音信号的滤波部分:无损声管模型 声管:声道各个器官的抽象模型 鼻腔的作用:并行的通道 简化:不考虑口鼻同时打开的情况
声源是由声带产生的,声带向声道提供激励信号,这种激励可以是周期性的或非周期性的。当声带处于发声状态(振动)时,会产生有声声音(例如,元音);而当声带处于无声状态时,会产生无声声音(例如,辅音)。声道可以看作是一个滤波器,它可以对来自声带的激励信号频谱进行整形以产生各种声音。 线性预测编码(LPC):Linear Predictive Coding LPC编码的基本思想:“一个语音取样的现在值可以用若干个语音取样过去值的加权线性组合来逼近”,用过去p个样本点预测当前值: x ~ [ n ] = ∑ k = 1 p a k x [ n − k ] \widetilde{x}[n]=\sum_{k=1}^pa_kx[n-k] x [n]=k=1∑pakx[n−k] 在线性组合中的加权系数 a k a_k ak称为预测器系数。通过使实际语音抽样和线性预测抽样之间差值的平方和达到最小值,能够决定唯一的一组预测器系数。 预测误差: e [ n ] = x [ n ] − x ~ [ n ] = x [ n ] − ∑ k = 1 p a k x [ n − k ] e[n]=x[n]-\widetilde{x}[n] = x[n] - \sum_{k=1}^pa_kx[n-k] e[n]=x[n]−x [n]=x[n]−k=1∑pakx[n−k] m个语音信号样本片段的周期延拓: x m [ n ] = x [ m + n ] x_m[n] = x[m+n] xm[n]=x[m+n] 短时预测误差: E m = ∑ n e m 2 [ n ] = ∑ n ( x m [ n ] − x ~ m [ n ] ) 2 = ∑ n ( x m [ n ] − ∑ j = 1 p a j x m [ n − j ] ) 2 E_m=\sum_ne_m^2[n] = \sum_n\left(x_m[n]-\widetilde{x}_ m[n]\right)^2=\sum_n\left(x_m[n]-\sum_{j=1}^pa_jx_m[n-j]\right)^2 Em=n∑em2[n]=n∑(xm[n]−x m[n])2=n∑(xm[n]−j=1∑pajxm[n−j])2 线性预测编码通过估计共振峰、剔除它们在语音信号中的作用、估计保留的蜂鸣音强度与频率来分析语音信号。剔除共振峰的过程称为逆滤波,经过这个过程剩余的信号称为残余信号(residue)。 描述峰鸣强度与频率、共鸣峰、残余信号的数字可以保存、发送到其它地方。线性预测编码通过逆向的过程合成语音信号:使用蜂鸣参数与残余信号生成源信号、使用共振峰生成表示声道的滤波器,源信号经过滤波器的处理就得到语音信号。 J = E [ e 2 ( k ) ] = E [ ( s ( k ) − ∑ p = 1 P a p s ( k − p ) ) 2 ] J=E\left[e^{2}(k)\right]=E\left[\left(s(k)-\sum_{p=1}^{P}a_{p}s(k-p)\right)^{2}\right] J=E[e2(k)]=E⎣⎡(s(k)−p=1∑Paps(k−p))2⎦⎤ LPC特点:LPC分析/AR模型 把声道抽象为一个全极点模型: H ( z ) = X ( z ) E ( z ) = 1 1 − ∑ k = 1 p a k z − k = 1 A ( z ) H(z)=\frac{X(z)}{E(z)}=\frac{1}{1-\sum_{k=1}^pa_kz^{-k}}=\frac{1}{A(z)} H(z)=E(z)X(z)=1−∑k=1pakz−k1=A(z)1 p:级联声管个数,LPC分析阶数 时域表示: x [ n ] = ∑ k = 1 p a k x [ n − k ] + e [ n ] x[n] = \sum_{k=1}^pa_kx[n-k]+e[n] x[n]=k=1∑pakx[n−k]+e[n] LPC分析的正交性原理:预测误差与当前样本正交: ; e m , x m i ; = ∑ n e m [ n ] x m [ n − i ] = 0 1 ≤ i ≤ p ;e_m,x_m^i;=\sum_ne_m[n]x_m[n-i] =0 \quad\quad1≤i≤p =n∑em[n]xm[n−i]=01≤i≤p ∑ n x m [ n − i ] x m [ n ] = ∑ j = 1 p a j ∑ n x m [ n − i ] x m [ n − j ] i = 1 , 2 , . . . , p \sum_nx_m[n-i]x_m[n]=\sum_{j=1}^pa_j\sum_nx_m[n-i]x_m[n-j]\quad\quad i=1,2,...,p n∑xm[n−i]xm[n]=j=1∑pajn∑xm[n−i]xm[n−j]i=1,2,...,p 相关系数: ϕ m [ i , j ] = ∑ n x m [ n − i ] x m [ n − j ] \phi_m[i,j]=\sum_nx_m[n-i]x_m[n-j] ϕm[i,j]=∑nxm[n−i]xm[n−j] Yule-Walker Equations: ∑ j = 1 p a j ϕ m [ i , j ] = ϕ m [ i , 0 ] i = 1 , 2 , . . . , p \sum_{j=1}^pa_j\phi_m[i,j]=\phi_m[i,0]\quad i=1,2,...,p ∑j=1pajϕm[i,j]=ϕm[i,0]i=1,2,...,p 预测误差: E m = ∑ n x m 2 [ n ] − ∑ j = 1 p a j ∑ n x m [ n ] x m [ n − j ] = ϕ [ 0 , 0 ] − ∑ j = 1 p a j ϕ [ 0 , j ] E_m=\sum_nx_m^2[n]-\sum_{j=1}^pa_j\sum_nx_m[n]x_m[n-j]=\phi[0,0]-\sum_{j=1}^pa_j\phi[0,j] Em=n∑xm2[n]−j=1∑pajn∑xm[n]xm[n−j]=ϕ[0,0]−j=1∑pajϕ[0,j] 预测误差的能量归一化: e m [ n ] = G u m [ n ] ∑ n u m 2 [ n ] = 1 E m = ∑ n e m 2 [ n ] = G 2 ∑ n u m 2 [ n ] = G 2 e_m[n]=Gu_m[n]\quad\quad \sum_nu_m^2[n]=1\quad\quad E_m=\sum_ne_m^2[n]=G^2\sum_nu_m^2[n]=G^2 em[n]=Gum[n]n∑um2[n]=1Em=n∑em2[n]=G2n∑um2[n]=G2 LPC方程求解 Yule-Walker Equations ∑ j = 1 p a j ϕ m [ i , j ] = ϕ m [ i , 0 ] i = 1 , 2 , . . . , p \sum_{j=1}^pa_j\phi_m[i,j]=\phi_m[i,0]\quad\quad i=1,2,...,p ∑j=1pajϕm[i,j]=ϕm[i,0]i=1,2,...,p 本质:矩阵求逆,但是存在有效解法 方差矩阵法(Spoken Language Processing , Section 6.3.2.1)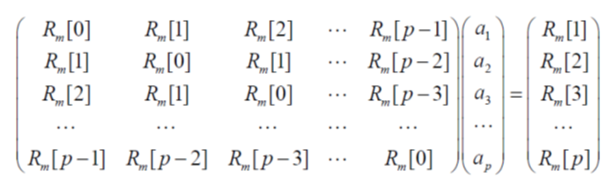 自相关法
加窗
x
m
[
n
]
=
x
[
m
+
n
]
w
[
n
]
x_m[n]=x[m+n]w[n]
xm[n]=x[m+n]w[n]预测误差
E
m
=
∑
n
=
0
N
+
p
−
1
e
m
2
[
n
]
E_m=\sum_{n=0}^{N+p-1}e_m^2[n]
Em=∑n=0N+p−1em2[n]自相关
ϕ
m
[
i
,
j
]
=
∑
n
=
0
N
+
p
−
1
x
m
[
n
−
i
]
x
m
[
n
−
j
]
=
∑
n
=
0
N
−
1
−
(
i
−
j
)
x
m
[
n
]
x
m
[
n
+
i
−
j
]
\phi_m[i,j]=\sum_{n=0}^{N+p-1}x_m[n-i]x_m[n-j]=\sum_{n=0}^{N-1-(i-j)}x_m[n]x_m[n+i-j]
ϕm[i,j]=n=0∑N+p−1xm[n−i]xm[n−j]=n=0∑N−1−(i−j)xm[n]xm[n+i−j]
ϕ
m
[
i
,
j
]
=
R
m
[
i
−
j
]
\phi_m[i,j]=R_m[i-j]
ϕm[i,j]=Rm[i−j]
R
m
[
k
]
=
∑
n
=
0
N
−
1
−
k
x
m
[
n
]
x
m
[
n
+
k
]
R_m[k]=\sum_{n=0}^{N-1-k}x_m[n]x_m[n+k]
Rm[k]=n=0∑N−1−kxm[n]xm[n+k]
语音生成模型 自相关法
加窗
x
m
[
n
]
=
x
[
m
+
n
]
w
[
n
]
x_m[n]=x[m+n]w[n]
xm[n]=x[m+n]w[n]预测误差
E
m
=
∑
n
=
0
N
+
p
−
1
e
m
2
[
n
]
E_m=\sum_{n=0}^{N+p-1}e_m^2[n]
Em=∑n=0N+p−1em2[n]自相关
ϕ
m
[
i
,
j
]
=
∑
n
=
0
N
+
p
−
1
x
m
[
n
−
i
]
x
m
[
n
−
j
]
=
∑
n
=
0
N
−
1
−
(
i
−
j
)
x
m
[
n
]
x
m
[
n
+
i
−
j
]
\phi_m[i,j]=\sum_{n=0}^{N+p-1}x_m[n-i]x_m[n-j]=\sum_{n=0}^{N-1-(i-j)}x_m[n]x_m[n+i-j]
ϕm[i,j]=n=0∑N+p−1xm[n−i]xm[n−j]=n=0∑N−1−(i−j)xm[n]xm[n+i−j]
ϕ
m
[
i
,
j
]
=
R
m
[
i
−
j
]
\phi_m[i,j]=R_m[i-j]
ϕm[i,j]=Rm[i−j]
R
m
[
k
]
=
∑
n
=
0
N
−
1
−
k
x
m
[
n
]
x
m
[
n
+
k
]
R_m[k]=\sum_{n=0}^{N-1-k}x_m[n]x_m[n+k]
Rm[k]=n=0∑N−1−kxm[n]xm[n+k]
语音生成模型
参考线性预测编码 语音生成模型: LPC正是基于这个模型的语音生成技术。在该模型中,语音信号是由一个激励信号 e ( k ) e(k) e(k)经过一个时变的全极点滤波器产生。全极点滤波器的系数取决于所产生的特定声音的声道形状。激励信号 e k e_{k} ek要么是浊音语音的脉冲序列,要么是无声声音的随机噪声。生成语音信号 s ( k ) s(k) s(k)可以表示为: s ( k ) = ∑ p = 1 P a p s ( k − p ) + e ( k ) s(k)=\sum_{p=1}^{P}a_{p}s(k-p)+e(k) s(k)=∑p=1Paps(k−p)+e(k) 其中, P 是滤波器的阶数, a p a_{p} ap 是滤波器的系数。LPC就是在已知 s ( k ) s(k) s(k) 的情况下获取 a p a_{p} ap . 求取 a p a_{p} ap 最常用的一个方法就是最小化真实信号与预测信号之间的均方误差(Mean Squared Error, MSE)。MSE函数可以表示为 J = E [ e 2 ( k ) ] = E [ ( s ( k ) − ∑ p = 1 P a p s ( k − p ) ) 2 ] J=E\left[e^{2}(k)\right]=E\left[\left(s(k)-\sum_{p=1}^{P}a_{p}s(k-p)\right)^{2}\right] J=E[e2(k)]=E⎣⎡(s(k)−p=1∑Paps(k−p))2⎦⎤ 然后,计算 J 关于每个滤波器系数的偏导,并令其值等于0,可得(3): ∂ J ∂ a p = 0 ( 3 ) \frac{\partial J}{\partial a_{p}}=0\quad\quad\quad(3) ∂ap∂J=0(3) 通过对(3)计算,可以得到(4): ∑ u = 1 P a u E [ s ( k − p ) s ( k − u ) ] = E [ s ( k ) s ( k − u ) ] , 1 ≤ u ≤ p ( 4 ) \sum_{u=1}^{P}a_{u}E\left[s(k-p)s(k-u)\right]=E\left[s(k)s(k-u)\right],~1\leq u\leq p\quad\quad\quad(4) u=1∑PauE[s(k−p)s(k−u)]=E[s(k)s(k−u)], 1≤u≤p(4) 其中, 1 ≤ p ≤ P 1\leq p \leq P 1≤p≤P 。用数值 1,2,…,P 分别替换(4)中的变量 p ,我们可以得到 P 个关于滤波器系数的线性方程组,求解该线性方程组,即可得到滤波器系数的解。求解该方程组最常用高效的方法是Levinson-Durbin算法。 Matlab参考: https://wenku.baidu.com/view/25a086fc19e8b8f67c1cb938.htmlhttps://blog.csdn.net/kaixinshier/article/details/72142889上述MSE期望也可以写作: e ( n ) = x ( n ) − x ~ ( n ) = x ( n ) − ∑ i = 1 p a i x ( n − i ) e(n)=x(n)-\widetilde{x}(n)=x(n)-\sum_{i=1}^pa_ix(n-i) e(n)=x(n)−x (n)=x(n)−∑i=1paix(n−i) 对 a i a_i ai求偏导可得: ∑ n x ( n ) x ( n − j ) = ∑ i = 1 p a i ∑ n x ( n − i ) x ( n − j ) \sum_nx(n)x(n-j)=\sum_{i=1}^pa_i\sum_nx(n-i)x(n-j) n∑x(n)x(n−j)=i=1∑pain∑x(n−i)x(n−j) E = ∑ n [ x ( n ) ] 2 − ∑ i = 1 p a i ∑ n x ( n ) x ( n − i ) E=\sum_n[x(n)]^2-\sum_{i=1}^pa_i\sum_nx(n)x(n-i) E=n∑[x(n)]2−i=1∑pain∑x(n)x(n−i) 写成自相关形式(Yule-Walker方程): R ( j ) = − ∑ i = 1 p a i R ( j − i ) 1 ≤ j ≤ p R(j)=-\sum_{i=1}^pa_iR(j-i)\quad\quad\quad1≤j≤p R(j)=−i=1∑paiR(j−i)1≤j≤p 拆写加权式子,即为Toeplize矩阵: Matlab中自带lpc函数,数学推导过程看《语音信号数字处理(L.R.Rabiner)》。 Matlab程序: [x,fs] = audioread('1.wav'); %这里读取的双声道信号 x数据,fs采样率 sound(x,fs); %播放音频 x1 = x(:,1); % figure % plot(t,x1) n = 200; % n is the length of a frame. % n行 p0 = 50; % p0 is the overlap length. % 在前面填充p0个0。自相关法 两端都需要加P个零取样值,会造成谱估计失真 xx = buffer(x1, n, p0); % 列:L/(n-p0),列理解为帧数 m = 8; % (m)th frame of data. y = xx((m-1)*n+1:m*n); % select a frame of data. p = 12; % p is the order of the AR model. 阶数 ar = lpc(y,p); % calculate the coefficients of AR model.就是前面的滤波器系数a_i est_x = filter([0 -ar(2:end )],1,y); % calculate the predicted signal. 建立语音帧的正则方程 err = y - est_x; % calculate the residual signal. figure plot(x1) title('原始信号'); figure subplot(2,2,1); plot(y,'r'); title('原始一帧'); subplot(2,2,2); plot(est_x); title('lpc预测的一帧'); subplot(2,2,3); plot(err,'r'); title('残余信号');效果图: 参考《语音信号处理》实验3-LPC特征提取: I = audioread('1.wav'); %读入原始语音 I = I(:,1); plot(I); title('原始语音波形');%对指定帧位置进行加窗处理 Q = I'; N = 256; %窗长 Hamm = hamming(N); %加窗 frame = 60;%需要处理的帧位置 M = Q(((frame - 1) * (N / 2) + 1):((frame - 1) * (N / 2) + N)); Frame = M.*Hamm'; %加窗后的语音帧 [B,F,T] = specgram(I,N,N/2,N); [m,n] = size(B); for i = 1:m FTframe1(i) = B(i,frame); end % P = input('请输入预测器阶数?=?'); P = 5; % 预测器阶数 改变不同阶数 观察变化 ai = lpc(Frame,P); %计算lpc系数 LP = filter( [0 - ai(2:end)],1,Frame); %建立语音帧的正则方程 FFTlp = fft(LP); E = Frame - LP; % 预测误差 figure subplot(2,1,1),plot(1:N,Frame,1:N,LP,'-r');grid; title('原始语音和预测语音波形 '); subplot(2,1,2) plot(E); grid; title('预测误差'); % pause fLength(1:2*N) = [M,zeros(1,N)]; Xm = fft(fLength, 2 * N); X = Xm .* conj(Xm); Y = fft(X , 2* N); Rk = Y(1 : N); PART = sum(ai(2:P+1) .* Rk(1:P)); G = sqrt(sum(Frame.^2) - PART); A = (FTframe1 - FFTlp(1:length(F')))./FTframe1; figure subplot(2,1,1),plot(F',20*log(abs(FTframe1)), F',(20*log(abs(1 ./A))),'-r'); grid; xlabel('频率/dB');ylabel('幅度'); title('短时谱'); subplot(2,1,2),plot(F',(20*log(abs(G./A))));grid; xlabel('频率/dB');ylabel('幅度'); title('LPC谱'); % pause %求出预测误差的倒谱 pitch = fftshift(rceps(E)); M_pitch = fftshift(rceps(Frame)); figure subplot(2,1,1),plot(M_pitch);grid; xlabel('语音帧');ylabel('/dB'); title('原始语音帧倒谱'); subplot(2,1,2),plot(pitch);grid; xlabel('语音帧');ylabel('/dB'); title('预测误差倒谱'); % pause %画出语谱图 ai1 = lpc(I,P); %计算原始语音lpc系数 LP1 = filter([0 - ai(2:end)], 1 ,I); % 建立原始语音的正则方程 figure subplot(2,1,1); specgram(I,N,N/2,N); title('原始语音语谱图'); subplot(2,1,2); specgram(LP1,N,N/2,N); title('预测语音语谱图')效果图: |
 语音信号的激励部分:声门激励
语音信号的激励部分:声门激励 H
(
z
)
=
X
(
z
)
E
(
z
)
=
1
1
−
∑
k
=
1
p
a
k
z
−
k
=
1
A
(
z
)
H(z)=\frac{X(z)}{E(z)}=\frac{1}{1-\sum_{k=1}^pa_kz^{-k}}=\frac{1}{A(z)}
H(z)=E(z)X(z)=1−∑k=1pakz−k1=A(z)1
H
(
z
)
=
X
(
z
)
E
(
z
)
=
1
1
−
∑
k
=
1
p
a
k
z
−
k
=
1
A
(
z
)
H(z)=\frac{X(z)}{E(z)}=\frac{1}{1-\sum_{k=1}^pa_kz^{-k}}=\frac{1}{A(z)}
H(z)=E(z)X(z)=1−∑k=1pakz−k1=A(z)1
 使用Durbin算法来求解Toeplize矩阵,即可计算出滤波器系数
a
i
a_i
ai。
使用Durbin算法来求解Toeplize矩阵,即可计算出滤波器系数
a
i
a_i
ai。




【本文地址】