万象解读|如何挖掘诈骗团伙、识别反欺诈,实现“征信修复”团伙一窝端 |
您所在的位置:网站首页 › 菲律宾诈骗团伙落网案例分析 › 万象解读|如何挖掘诈骗团伙、识别反欺诈,实现“征信修复”团伙一窝端 |
万象解读|如何挖掘诈骗团伙、识别反欺诈,实现“征信修复”团伙一窝端
|
关系网络提供了全新的反欺诈分析角度 基于上述金融欺诈发生的两个特点,采用关系网络进行反欺诈检测变得越来越重要。关系网据指的是一种基于图的数据结构,由节点和边组成,如下图1所示。每个节点代表一个个体,每条边为个体与个体之间的关系。关系网络把不同的个体按照其关系连接在一起,从而提供了从“关系”的角度分析问题的能力。这更有利于从正常行为中识别出到异常的团伙欺诈行为。
图1 关系网络的结构取决于如何定义个体与个体之间的关系。如果人与人存在“关系”指的是彼此认识,那么最终的网络结构将是一个无标度网络,其典型特征是在网络中的大部分节点只和很少节点连接,而有极少的节点与非常多的节点连接。如果将“关系”定义为亲属关系,则最终的网络结构将是一个个非连通的子图,每个子图代表一个家族。 在解决实际问题的时候,关系的定义需要依据业务需求并且常常极为复杂。例如,某市公安局为了摸清犯罪嫌疑人的团伙,定义了24种人与人之间的关系。在反欺诈领域,如何定义“关系”更是需要保密,这是为了避免欺诈团伙采取针对性地防范策略,本文对这部分内容就不做过多的说明了。 图2展示了由从某一线城市抽样的20,000余条贷款申请数据所构成的关系网络。因为所定义的“关系”均为强关系,所以图的结构不是一个连通的无标度网络,而是由一个个孤立的“团”组成的网络。其中,大部分的“团”由两个个体组成,他们之间通过某种关系相连。个别的“团”是由几十甚至上百个体组成的具有复杂结构的网络。
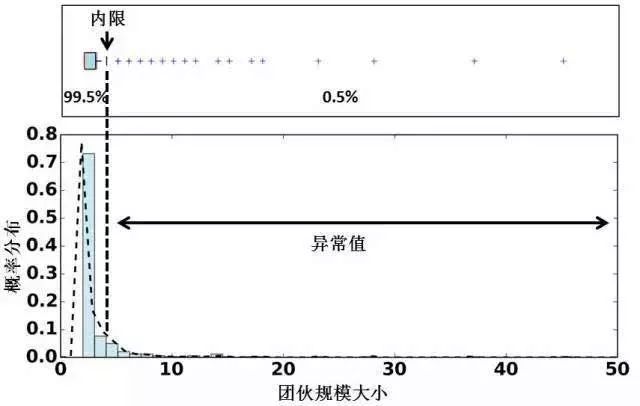
图2 网络分析在反欺诈中的独道运用 接下来,我们来讨论关系网络在反欺诈中的应用场景,主要分为监督模型和无监督模型两种情况。所谓的监督模型,指的是在已知“好”和“坏”标签的前提下,尝试从历史数据中,挖掘出欺诈团伙的典型特征和行为模式,从而能够有效的识别出金融欺诈团伙。监督模型虽然在预测准确性上有不错的表现,但是,实际情况中,“好”和“坏”的标签往往很难得到。因此,在没有标签信息时,无监督模型分析也变得尤为重要。当然,本文提到的分析方法只是关系网络在反欺诈场景中的冰山一角,更多的算法模型需要结合实际业务需求进行设计和开发。 典型运用一:异常检测 异常检测是在无监督模型学习中比较有代表性的方法,即在数据中找出具有异常性质的点或团体。在检测欺诈团体的情况下,异常检测被认为是比较有效果的。以贷款申请为例,许多团伙会选择共享一些申请信息,如提供同一个皮包公司的地址作为公司信息,或者联系人电话重合程度高。因此,在关系网络中,大多数的正常的个体应该是独立的节点,或者与另一个节点组成规模为二的团体(在这种情况下,多数可能为家人或亲友关系)。若出现三个点以上甚至十几个点关系密切时,则这些团体可被归为异常。上文中的20,000笔贷款申请组成的关系网络中含有300多个团体,团体规模分布由下图所示,其中大部分团体的规模较小,当团体规模超过某一阈值时,其可被认为异常。
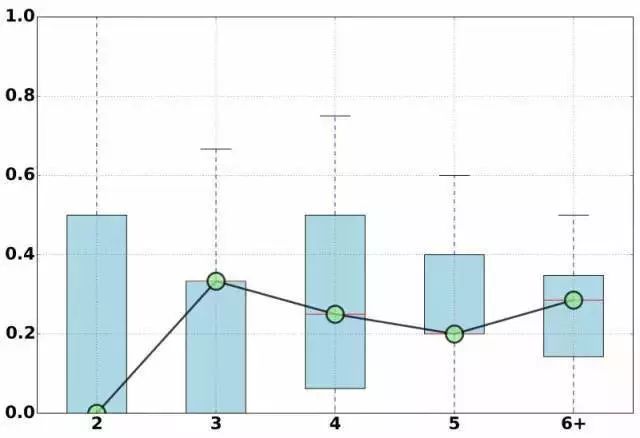
图3 我们对团体规模大小和欺诈度的相关性进行了分析。其中,欺诈度的定义为:欺诈度=团体中欺诈申请者的数目/团体中申请者总数。我们通过行业内的网贷黑名单数据来判定某一个体是否为欺诈申请者。相关性结果如下图所示,其中,横坐标表示团体规模大小,纵坐标表示欺诈度。可以看出,当团伙只有两个人时,欺诈度的中位数是0,而当规模变大时,欺诈度陡然增加。当团体规模大小为三人时,欺诈度最高,达到30%,其次为规模超过六人的团体。
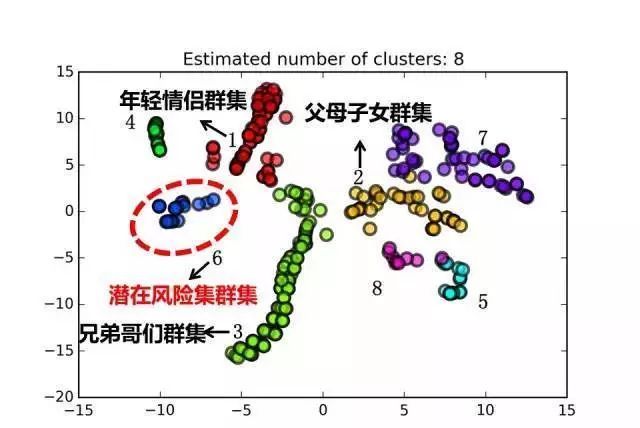
图4 异常检测并不能够明确的给出一个团体是否欺诈,但是可以通过这种方法排查出可疑的团伙,从而进行调查。该算法并不是基于历史数据挖掘隐藏的欺诈模式,因而常常能够有效地识别出新出现的未曾记录的欺诈行为。 典型运用二:团体分群 分群是一种常常被用于客户精准营销的无监督聚类算法,根据客户各个维度的信息,将其归并于某一特定群组,并对不同群组的客户采取差异化的营销策略。除了用于精准营销,分群算法还可以用于离群行为的检测,即,检测哪些客户的行为与同一群体的其他客户不同。这些离群行为或是预示着这些客户处于某些特殊事件情境中,或是预示着欺诈行为。这一部分主要和前文提到的异常检测相关,这里不再赘述。 与客户分群不同,团体分群不仅依赖于团体中每个个体的特征,还依赖于整个团体作为一个整体的特征。这一方面使得团体分群拥有足够丰富的数据维度,另一方面也增加了问题的复杂性。一般来说,团体的特征可以分为 (1)和网络结构相关的团伙拓扑特征以及(2)和个体信息相关的团伙实体特征这两个大的维度。其中,团体的拓扑特征包括团的节点的数量、平均自由度、团体中节点间最长的最短路径等;团的实体特征包括团中男女比例、最大年龄差,平均年龄、团体总资产、团体总负债等。 团体分群即是对给定网络中的团体依据以上特征进行区分,从而挖掘有潜在欺诈风险的团体的方法。举一个简单的例子,以团体中的男性占比和年龄差者两个特征来对网络中的团体进行分群。作为以家人关系而形成的团体,一般由三人形成,多为两男一女或两女一男,男性占比33%或67%,并且年龄差一般为20-30岁。具有这种性质的团体一般为家庭团体,因而风险性较小。但对于人数较多,男性占比高,而且年龄差较小的团体,则有可能是欺诈团伙,需要进一步调查。 实际问题中,描述一个团伙的数据维度非常丰富,有时可多达数十个,这就对分群造成了困难(在高维空间中,寻找点的集群并不是一件容易的事,俗称“维度灾难”)。一个常用的解决方法是先对高维数据进行降维,然后再在低维空间中进行聚类。图5是对一组数据中由贷款申请构成的300多个团体进行分群的结果。在这个分析中,我们用男女比例、最大年龄差、有车个体占比、有房个体占比、有贷款个体占比和买理财产品个体占比这六个维度对团伙进行描述。我们采用t-SNE(t-Distributed Stochastic Neighbor Embedding)算法对高维数据进行降维和DBSCAN聚类算法对低维数据进行分群。由图5可见,在低维空间中,确实存在明显分隔的集群,这说明团体分群在实际操作中的可行性。
图5 (每一个点代表一个团体,上述数据可以分为八个集群) 我们对图5中每一个集群进行分析。集群1中的团体男女比例1:1,年龄相差0-5岁,集群中无人有贷款或买理财产品。这个集群很可能描述了由年轻情侣构成的团体。对于集群2中的团伙,男女比例2:1,年龄相差15-30岁,每个团伙中平均有一人有车和房,并且背有贷款,这个集群很可能描述了由父母子女构成的“团伙”。 按照同样的方法可以对图5每一个集群进行分析,这里不一一赘述。尽管我们没有“好”、“坏”标签,无法得知哪个集群含有大量欺诈团伙,但是我们可以依据经验和专家知识筛选出可疑的集群,为进一步调查做好准备。例如集群6中全部由男性“团伙”构成,年龄相差0-10岁,团伙中大量个体都背有贷款。这个集群的欺诈嫌疑就比其他集群要高一些,下一步就可以继续对其进行进一步的调查。返回搜狐,查看更多 |


【本文地址】
今日新闻 |
推荐新闻 |