python 数据分析 |
您所在的位置:网站首页 › 苹果id换了之前的id还同步内容吗 › python 数据分析 |
python 数据分析
|
说明:
数据可视化中的数据集下载地址:(数据来源:从零开始学python数据分析和挖掘)
链接:https://pan.baidu.com/s/1zrNpzSNVHd8v1rGFRzKipQ 提取码:mx9d
数据可视化是数据分析中的一部分,可用于数据的探索和查找缺失值等,也是展现数据的重要手段。matplotlib是一个强大的工具箱,其完整的图表样式函数和个性化的自定义设置,可以满足几乎所有的2D和一些3D绘图的需求。 1. 条形图条形图主要用来表示分组(或离散)变量的可视化,可以使用matplotlib完成条形图的绘制。 1.1 垂直条形图以垂直条形图为例,离散型变量在各水平上的差异就是比较柱形的高低,柱体越高,代表的数值越大。plt.bar()函数的参数列表: left:传递数值序列,指定条形图中x轴上的刻度值,现left需改为x。 height:传递数值序列,指定条形图y轴上的高度。 width:指定条形图的宽度,默认为0.8。 bottom:用于绘制堆叠条形图。 color:指定条形图的填充色。 edgecolor:指定条形图的边框色。 linewidth:指定条形图边框的宽度,如果指定为0,表示不绘制边框。 tick_label:指定条形图的刻度标签。 xerr:如果参数不为None,表示在条形图的基础上添加误差棒。yerr:参数含义同xerr。 label:指定条形图的标签,一般用以添加图例。 ecolor:指定条形图误差棒的颜色。 align:指定x轴刻度标签的对齐方式,默认为center,表示刻度标签居中对齐,如果设置为 edge,则表示在每个条形的左下角呈现刻度标签。 log:bool类型参数,是否对坐标轴进行log变换,默认为False。 **kwargs:关键字参数,用于对条形图进行其他设置,如透明度等。
水平条形图不再是bar函数,而是barh函数。对原始数据做升序排序,但是图形看上去是降序,是因为水平条形图的y轴刻度值是从下往上布置的,所以条形图从下往上是满足升序的。 # 条形图的绘制--水平条形图 # 导入第三方库和读入数据同上 # 添加条形图的标题 plt.title('2017年度6个省份GDP分布') # 添加x轴的标签 plt.xlabel('GDP(万亿)') # 对读入的数据作升序排序 GDP.sort_values(by = 'GDP', inplace = True) # 绘制条形图 plt.barh(y = range(GDP.shape[0]), # 指定条形图y轴的刻度值 width = GDP.GDP, # 指定条形图x轴的数值 tick_label = GDP.Province, # 指定条形图y轴的刻度标签 color = 'green', # 指定条形图的填充色 ) # 为每个条形图添加数值标签 for y,x in enumerate(GDP.GDP): plt.text(x+0.1,y,'%s' %round(x,1),va='center') #此处x在前,y在后,数值标签加在x上, 居中也是垂直方向居中 # 显示图形 plt.show()
不管是垂直条形图还是水平条形图,只是反映单个离散变量的统计图形,如果想通过条形图传递两个离散变量的信息该如何做到?这就需要使用堆叠条形图,该类型条形图的横坐标代表一个维度的离散变量,堆叠起来的“块”代表了另一个维度的离散变量。这样的条形图,最大的优点是可以方便比较累积和。
堆叠条形图可以包含两个离散变量的信息,而且可以比较各季度整体产值的高低水平,但是其缺点是不易区分“块”之间的差异,例如二、三季度的第三产业值差异就不是很明显,区分高低就相对困难。而交错条形图恰好就可以解决这个问题,该类型的条形图就是将堆叠的“块”水平排开。 # 条形图的绘制--水平交错条形图 # 导入第三方模块 import matplotlib.pyplot as plt import pandas as pd import numpy as np # 读取数据 Industry_GDP = pd.read_excel(r'E:\Data\4\Industry_GDP.xlsx') # 取出四个不同的季度标签,用作堆叠条形图x轴的刻度标签 Quarters = Industry_GDP.Quarter.unique() # 取出第一、二、三产业的四季度值 Industry1 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第一产业'] Industry1.index = range(len(Quarters))# 重新设置行索引 Industry2 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第二产业'] Industry2.index = range(len(Quarters)) Industry3 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第三产业'] # 绘制水平交错条形图 bar_width = 0.3 # 各季度下第一产业的条形图 plt.bar(x = np.arange(len(Quarters)), height=Industry1, color = 'yellow', label = '第一产业' , width = bar_width) # 各季度下第二产业的条形图 plt.bar(x = np.arange(len(Quarters))+ bar_width, height=Industry2, color = 'green', label = '第二产业', width = bar_width) # 各季度下第三产业的条形图 plt.bar(x = np.arange(len(Quarters))+ 2*bar_width, height=Industry3, color = 'indianred', label = '第三产业', width = bar_width) # 为每个条形图添加数值标签 for x,y in enumerate(Industry1): plt.text(x,y+0.1,'%s' %round(y,1),ha='center') # 为每个条形图添加数值标签 for x,y in enumerate(Industry2): plt.text(x+0.3,y+0.1,'%s' %round(y,1),ha='center') for x,y in enumerate(Industry3): plt.text(x+0.6,y+0.1,'%s' %round(y,1),ha='center') # 添加刻度标签 plt.xticks(np.arange(4)+0.3, Quarters) plt.ylabel('生成总值(亿)') plt.title('2017年各季度三产业总值') plt.legend(loc='upper left',bbox_to_anchor=(0,1.2),ncol=3, shadow=True) plt.show()
饼图属于最传统的统计图形之一,如果你选择matplotlib模块绘制饼图的话,首先需要导入该模块的子模块pyplot,然后调用模块中的pie函数。 x:指定绘图的数据。 explode:指定饼图某些部分的突出显示,即呈现爆炸式。 labels:为饼图添加标签说明,类似于图例说明。 colors:指定饼图的填充色。 autopct:自动添加百分比显示,可以采用格式化的方法显示。 pctdistance:设置百分比标签与圆心的距离。 shadow:是否添加饼图的阴影效果。 labeldistance:设置各扇形标签(图例)与圆心的距离。 startangle:设置饼图的初始摆放角度。 radius:设置饼图的半径大小。 counterclock:是否让饼图按逆时针顺序呈现。 wedgeprops:设置饼图内外边界的属性,如边界线的粗细、颜色等。 textprops:设置饼图中文本的属性,如字体大小、颜色等。 center:指定饼图的中心点位置,默认为原点。 frame:是否要显示饼图背后的图框,如果设置为True的话,需要同时控制图框x轴、y轴的范围和饼图的中心位置。 import matplotlib.pyplot as plt import pandas as pd import numpy as np # 读取数据 Industry_GDP = pd.read_excel(r'E:\Data\4\Industry_GDP.xlsx') # 取出四个不同的季度标签,用作堆叠条形图x轴的刻度标签 Quarters = Industry_GDP.Quarter.unique() # 取出第一、二、三产业的四季度值 Industry1 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第一产业'] Industry1.index = range(len(Quarters))# 重新设置行索引 Industry2 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第二产业'] Industry2.index = range(len(Quarters)) Industry3 = Industry_GDP.GPD[Industry_GDP.Industry_Type == '第三产业'] Industry3.index = range(len(Quarters)) DataQ1 = Industry1[0] + Industry2[0] + Industry3[0] DataQ2 = Industry1[1] + Industry2[1] + Industry3[1] DataQ3 = Industry1[2] + Industry2[2] + Industry3[2] DataQ4 = Industry1[3] + Industry2[3] + Industry3[3] DataToatal = DataQ1+DataQ2+DataQ3+DataQ4 # 构造数据 Industry = [DataQ1/DataToatal,DataQ2/DataToatal,DataQ3/DataToatal,DataQ4/DataToatal] labels = Quarters # 解决中文显示问题 plt.rcParams['font.sans-serif'] = ['KaiTi'] plt.rcParams['axes.unicode_minus'] = False explode = [0,0,0,0.1] # 绘制饼图 plt.pie(x = Industry, # 绘图数据 labels=labels, # 添加教育水平标签 autopct='%.1f%%', # 设置百分比的格式,这里保留一位小数 colors = np.array(['#332DF1','#2F8177','#A21B63','#22BB99']), radius= 1.2, # 圆的半径 shadow= True, # 圆的阴影 startangle = 0, # 设置饼图的初始角度 counterclock= False, # False 表示逆时针 wedgeprops = {'linewidth': 1.5, 'edgecolor':'green'}, # 设置饼图内外边界的属性值 textprops = {'fontsize':20, 'color':'black'}, # 设置文本标签的属性值 explode= explode, #第四季度突出显示 ) # 添加图标题 plt.title('各个季度工业GDP总值百分比情况') # 显示图形 plt.show()
直方图一般用来观察数据的分布形态,横坐标代表数值的均匀分段,纵坐标代表每个段内的观测数量(频数)。一般直方图都会与核密度图搭配使用,目的是更加清晰地掌握数据的分布特征。matplotlib模块中的hist函数就是用来绘制直方图的。关于该函数的语参数含义如下: x:指定要绘制直方图的数据。 bins:指定直方图条形的个数。 range:指定直方图数据的上下界,默认包含绘图数据的最大值和最小值。 normed:是否将直方图的频数转换成频率。 weights:该参数可为每一个数据点设置权重。 cumulative:是否需要计算累计频数或频率。 bottom:可以为直方图的每个条形添加基准线,默认为0。 histtype:指定直方图的类型,默认为bar,除此之外,还有barstacked、stepstepfilled。 align:设置条形边界值的对齐方式,默认为mid,另外还有left和right。 orientation:设置直方图的摆放方向,默认为垂直方向。 rwidth:设置直方图条形的宽度。 log:是否需要对绘图数据进行log变换。 color:设置直方图的填充色。 edgecolor:设置直方图边框色。 label:设置直方图的标签,可通过legend展示其图例。 stacked:当有多个数据时,是否需要将直方图呈堆叠摆放,默认水平摆放。 import matplotlib.pyplot as plt import pandas as pd Titanic = pd.read_csv(r"E:/Data/4/titanic_train.csv") if any(Titanic.Age.isnull()): Titanic.dropna(subset=['Age'], inplace=True) Titanic.head() PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked 0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S 1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C 2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S 3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S 4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S plt.hist(x = Titanic.Age, bins = 20, color= 'steelblue', edgecolor = 'black') plt.xlabel("年龄") plt.ylabel("人数") plt.title("泰坦尼克号乘客年龄分布")
如果原始数据集中存在缺失值,一定要对缺失观测进行删除或替换,否则无法绘制成功。如果在直方图的基础上再添加核密度图,通过matplotlib模块就比较吃力了,因为首先得计算出每一个年龄对应的核密度值。为了简单起见,下面利用pandas模块中的plot方法将直方图和核密度图绘制到一起。 # Pandas模块绘制直方图和核密度图 # 绘制直方图 Titanic.Age.plot(kind = 'hist', bins = 20, color = 'steelblue', edgecolor = 'black', normed = True, label = '直方图') # 绘制核密度图 Titanic.Age.plot(kind = 'kde', color = 'red', label = '核密度图') # 添加x轴和y轴标签 # 添加标题 plt.title('泰坦尼克号乘客年龄分布') plt.xlabel('年龄') plt.ylabel('核密度值') # 显示图例 plt.legend() # 显示图形 plt.show()
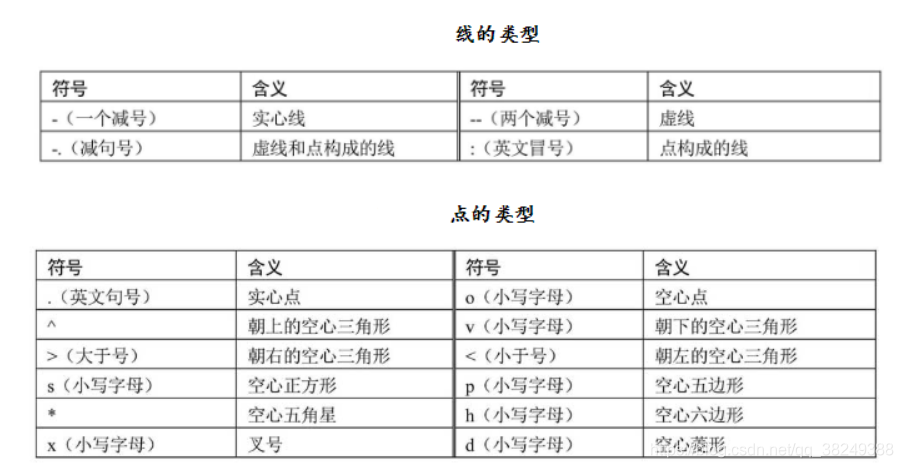
箱线图是另一种体现数据分布的图形,通过该图可以得知数据的下须值(Q1-1.5IQR)、下四分位数(Q1)、中位数(Q2)、均值、上四分位(Q3)数和上须值(Q3+1.5IQR),更重要的是,箱线图还可以发现数据中的异常点。matplotlib模块中绘制箱线图的boxplot函数的参数含义如下: x:指定要绘制箱线图的数据。 notch:是否以凹口的形式展现箱线图,默认非凹口。 sym:指定异常点的形状,默认为+号显示。 vert:是否需要将箱线图垂直摆放,默认垂直摆放。 whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差。 positions:指定箱线图的位置,默认为[0,1,2…]。 widths:指定箱线图的宽度,默认为0.5。 patch_artist:bool类型参数,是否填充箱体的颜色;默认为False。 meanline:bool类型参数,是否用线的形式表示均值,默认为False。 showmeans:bool类型参数,是否显示均值,默认为False。 showcaps:bool类型参数,是否显示箱线图顶端和末端的两条线(即上下须),默认为True。 showbox:bool类型参数,是否显示箱线图的箱体,默认为True。 showfliers:是否显示异常值,默认为True。 boxprops:设置箱体的属性,如边框色,填充色等。 labels:为箱线图添加标签,类似于图例的作用。 filerprops:设置异常值的属性,如异常点的形状、大小、填充色等。 medianprops:设置中位数的属性,如线的类型、粗细等。 meanprops:设置均值的属性,如点的大小、颜色等。 capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等。 whiskerprops:设置须的属性,如颜色、粗细、线的类型等。
对于时间序列数据而言,一般都会使用折线图反映数据背后的趋势。通常折线图的横坐标指代日期数据,纵坐标代表某个数值型变量,当然还可以使用第三个离散变量对折线图进行分组处理。折线图的绘制可以使用matplotlib模块中的plot函数实现。该函数参数含义如下: x:指定折线图的x轴数据。 y:指定折线图的y轴数据。 linestyle:指定折线的类型,可以是实线、虚线、点虚线、点点线等,默认为实线。 linewidth:指定折线的宽度。 marker:可以为折线图添加点,该参数是设置点的形状。 markersize:设置点的大小。 markeredgecolor:设置点的边框色。 markerfactcolor:设置点的填充色。 markeredgewidth:设置点的边框宽度。 label:为折线图添加标签,类似于图例的作用。 import random import matplotlib.pyplot as plt x = [1,2,2,4,4,6,7,8,9,9,11] y = [i**2 for i in x ] plt.plot(x, y , label='x**2') plt.xlabel('x label') plt.ylabel('y label') plt.title("Simple Plot") plt.legend() plt.show()
如果需要研究两个数值型变量之间是否存在某种关系,例如正向的线性关系,或者是趋势性的非线性关系,那么散点图将是最佳的选择。matplotlib模块中的scatter函数可以非常方便地绘制两个数值型变量的散点图。函数的参数含义写在下方: x:指定散点图的x轴数据。 y:指定散点图的y轴数据。 s:指定散点图点的大小,默认为20,通过传入其他数值型变量,可以实现气泡图的绘制。 c:指定散点图点的颜色,默认为蓝色,也可以传递其他数值型变量,通过cmap参数的色阶表示数值大小。 marker:指定散点图点的形状,默认为空心圆。 cmap:指定某个Colormap值,只有当c参数是一个浮点型数组时才有效。 norm:设置数据亮度,标准化到0~1,使用该参数仍需要参数c为浮点型的数组。 vmin、vmax:亮度设置,与norm类似,如果使用norm参数,则该参数无效。 alpha:设置散点的透明度。 linewidths:设置散点边界线的宽度。 edgecolors:设置散点边界线的颜色。 import matplotlib.pyplot as plt import pandas as pd # 读入数据 iris = pd.read_csv(r'E:\Data\4\iris.csv') iris.head() Sepal_Length Sepal_Width Petal_Length Petal_Width Species 0 5.1 3.5 1.4 0.2 setosa 1 4.9 3.0 1.4 0.2 setosa 2 4.7 3.2 1.3 0.2 setosa 3 4.6 3.1 1.5 0.2 setosa 4 5.0 3.6 1.4 0.2 setosa # 绘制散点图 plt.scatter(x = iris.Petal_Width, # 指定散点图的x轴数据 y = iris.Petal_Length, # 指定散点图的y轴数据 color = 'steelblue' # 指定散点图中点的颜色 ) # 添加x轴和y轴标签 plt.xlabel('花瓣宽度') plt.ylabel('花瓣长度') # 添加标题 plt.title('鸢尾花的花瓣宽度与长度关系') # 显示图形 plt.show()
气泡图的实质就是通过第三个数值型变量控制每个散点的大小,点越大,代表的第三维数值越高,反之亦然。matplotlib模块中的scatter函数绘制了散点图,绘制气泡图将继续使用该函数。关键的参数是s,即散点图中点的大小,如果将数值型变量传递给该参数,就可以轻松绘制气泡图了。 import matplotlib.pyplot as plt import pandas as pd # 读取数据 Prod_Category = pd.read_excel(r'E:\Data\4\SuperMarket.xlsx') Prod_Category.head() Category Sub_Category Profit Sales Profit_Ratio std_ratio 0 办公用品 信封 49241.5600 176861.52 0.278419 0.839328 1 办公用品 剪刀,尺子,锯 -7953.5700 80800.03 -0.098435 0.001000 2 办公用品 夹子及其配件 306455.2895 1026410.56 0.298570 0.884155 3 办公用品 家用电器 100258.3200 742663.39 0.134998 0.520283 4 办公用品 容器,箱子 10068.2100 1112252.53 0.009052 0.240110 # 将利润率标准化到[0,1]之间(因为利润率中有负数),然后加上微小的数值0.001 range_diff = Prod_Category.Profit_Ratio.max()-Prod_Category.Profit_Ratio.min() Prod_Category['std_ratio'] = (Prod_Category.Profit_Ratio-Prod_Category.Profit_Ratio.min())/range_diff + 0.001 # 绘制办公用品的气泡图 plt.scatter(x = Prod_Category.Sales[Prod_Category.Category == '办公用品'], y = Prod_Category.Profit[Prod_Category.Category == '办公用品'], s = Prod_Category.std_ratio[Prod_Category.Category == '办公用品']*1000, color = 'steelblue', label = '办公用品', alpha = 0.6 ) # 绘制技术产品的气泡图 plt.scatter(x = Prod_Category.Sales[Prod_Category.Category == '技术产品'], y = Prod_Category.Profit[Prod_Category.Category == '技术产品'], s = Prod_Category.std_ratio[Prod_Category.Category == '技术产品']*1000, color = 'indianred' , label = '技术产品', alpha = 0.6 ) # 绘制家具产品的气泡图 plt.scatter(x = Prod_Category.Sales[Prod_Category.Category == '家具产品'], y = Prod_Category.Profit[Prod_Category.Category == '家具产品'], s = Prod_Category.std_ratio[Prod_Category.Category == '家具产品']*1000, color = 'black' , label = '家具产品', alpha = 0.6 ) # 添加x轴和y轴标签 plt.xlabel('销售额') plt.ylabel('利润') # 添加标题 plt.title('销售额、利润及利润率的气泡图') # 添加图例 plt.legend() # 显示图形 plt.show()
如图上所示,应用scatter函数绘制了分组气泡图,从图中可知,办公用品和家具产品的利润率波动比较大(因为这两类圆点大小不均)。从代码角度来看,绘图的核心部分是使用三次scatter函数,而且代码结构完全一样,如果读者对for循环掌握得比较好,完全可以使用循环的方式替换三次scatter函数的重复应用。需要说明的是,如果s参数对应的变量值小于等于0,则对应的气泡点是无法绘制出来的。这里提供一个解决思路,就是先将该变量标准化为[0,1],再加上一个非常小的值,如0.001。如上代码所示,最后对s参数扩大1000倍的目的就是凸显气泡的大小。 当然,作为强大的绘图库,Matplotlib的功能远远不止上面这一点,未涉及到的,以后需要用的时候,在进一步学习吧,坚持,坚持,坚持,每天进步一点点,不积跬步,无以至千里;不积小流,无以成江河。 |
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4Ol3ti7S-1586005368658)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200404211434669.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1xA15xB-1586005368660)(output_8_0.png)]](https://img-blog.csdnimg.cn/20200404211517213.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CsAf7AEs-1586005368660)(output_11_0.png)]](https://img-blog.csdnimg.cn/20200404211533467.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yMtNH6UQ-1586005368661)(attachment:image.png)]](https://img-blog.csdnimg.cn/20200404211551524.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KpLfL5d4-1586005368661)(output_15_0.png)]](https://img-blog.csdnimg.cn/20200404211753962.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WSpB64fc-1586005368662)(output_18_0.png)]](https://img-blog.csdnimg.cn/20200404211812910.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tHzSSByE-1586005368663)(output_21_0.png)]](https://img-blog.csdnimg.cn/20200404211850238.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VomyCGgg-1586005368664)(output_25_1.png)]](https://img-blog.csdnimg.cn/20200404211942673.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TWg7ki3D-1586005368664)(output_27_0.png)]](https://img-blog.csdnimg.cn/20200404212025511.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AjclVEpF-1586005368667)(output_33_0.png)]](https://img-blog.csdnimg.cn/20200404212146399.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LHcVrpo9-1586005368669)(output_34_0.png)]](https://img-blog.csdnimg.cn/20200404212206598.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-R1fCRRAW-1586005368669)(output_37_0.png)]](https://img-blog.csdnimg.cn/20200404212240267.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dGqzr52c-1586005368670)(output_41_0.png)]](https://img-blog.csdnimg.cn/20200404212304879.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GjTT2KbZ-1586005368671)(output_45_0.png)]](https://img-blog.csdnimg.cn/20200404212337355.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM4MjQ5Mzg4,size_16,color_FFFFFF,t_70)
【本文地址】
今日新闻 |
推荐新闻 |