自学 Python 到什么程度能找到工作,1300+ 条招聘信息告诉你答案 |
您所在的位置:网站首页 › 自学摄影能找到工作吗 › 自学 Python 到什么程度能找到工作,1300+ 条招聘信息告诉你答案 |
自学 Python 到什么程度能找到工作,1300+ 条招聘信息告诉你答案
|
随着移动互联网的发展以及机器学习等热门领域带给人们的冲击,让越来越多的人知道并开始学习 Python。无论你是是科班出身还是非科班转行,Python 无疑都是非常适合你入门计算机世界的第一语言,其语法非常简洁,写出的程序易懂,这也是 Python 一贯的哲学「简单优雅」,在保证代码可读的基础上,用尽可能少的代码完成你的想法。 那么,我们学习 Python 到什么程度,就可以开始找工作了呢,大家都知道,实践是检验这里的唯一标准,那么学到什么程度可以找工作,当然得看市场的需求,毕竟企业招你来是工作的,而不是让你来带薪学习的。 所以,今天我们就试着爬取下拉钩上关于 Python 的招聘信息,来看看市场到底需要什么样的人才。 网页结构分析打开拉钩网首页,输入关键字「Python」,接着按 F12 打开网页调试面板,切换到「Network」选项卡下,过滤条件选上「XHR」,一切准备就绪之后点击搜索,仔细观察网页的网络请求数据。 从这些请求中我们可以大致猜测到数据好像是从 jobs/positionAjax.json 这个接口获取的。
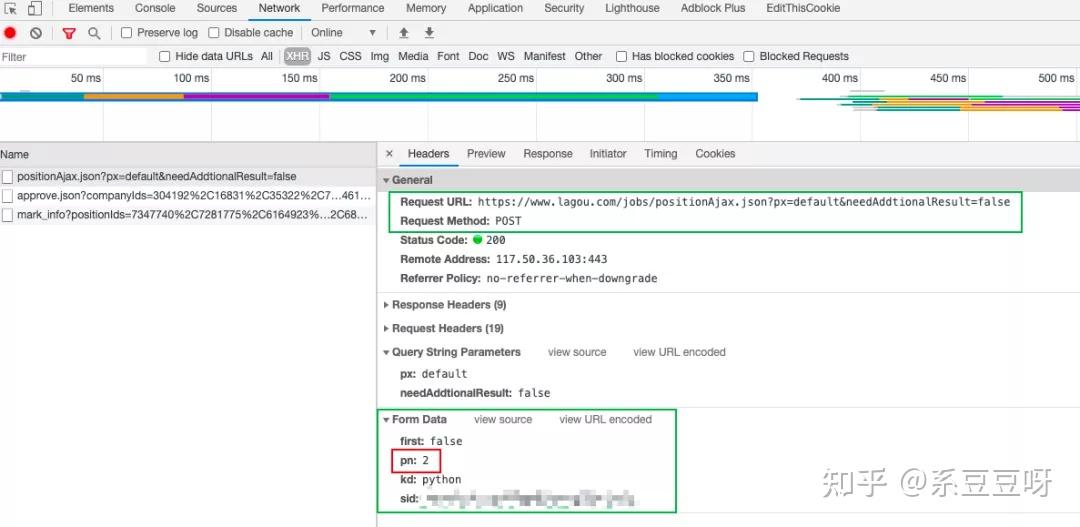
别急,我们来验证下,清空网络请求记录,翻页试试。当点击第二页的时候,请求记录如下。
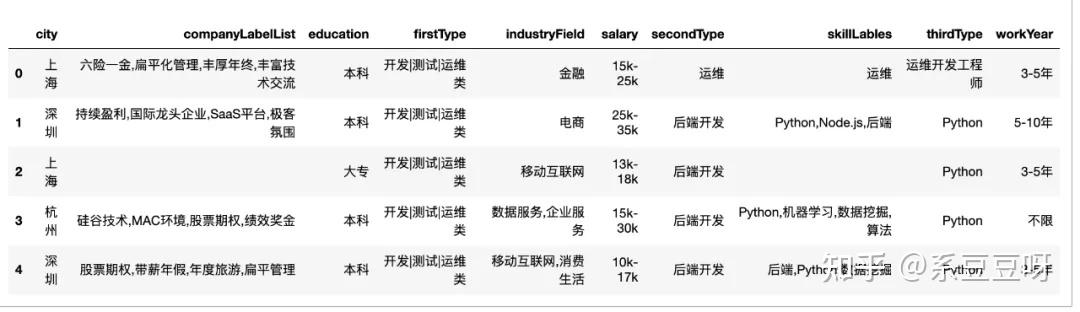
可以看出,这些数据是通过 POST 请求获取的,Form Data 中的 pn 就是当前页码了。好了,网页分析好了,接下来就可以写爬虫拉取数据了。你的爬虫代码看起来可能会是这样的。 url = 'https://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false' headers = """ accept: application/json, text/javascript, */*; q=0.01 origin: https://www.lagou.com referer: https://www.lagou.com/jobs/list_python?px=new&city=%E5%85%A8%E5%9B%BD user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 """ headers_dict = headers_to_dict(headers) def get_data_from_cloud(page): params = { 'first': 'false', 'pn': page, 'kd': 'python' } response = requests.post(url, data=params, headers=headers_dict, timeout=3) result = response.text write_file(result) for i in range(76): get_data_from_cloud(i + 1)程序写好之后,激动的心,颤抖的手,满怀期待的你按下了 run 按钮。美滋滋的等着接收数据呢,然而你得到的结果数据很大可能是这样的。 {"success":true,"msg":null,"code":0,"content":{"showId":"8302f64","hrInfoMap":{"6851017":{"userId":621208... {"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"xxx.yyy.zzz.aaa","state":2402} ...不要怀疑,我得到的结果就是这样的。这是因为拉勾网做了反爬虫机制,对应的解决方案就是不要频繁的爬,每次获取到数据之后适当停顿下,比如每两个请求之间休眠 3 秒,然后请求数据时再加上 cookie 信息。完善之后的爬虫程序如下: home_url = 'https://www.lagou.com/jobs/list_python?px=new&city=%E5%85%A8%E5%9B%BD' url = 'https://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false' headers = """ accept: application/json, text/javascript, */*; q=0.01 origin: https://www.lagou.com referer: https://www.lagou.com/jobs/list_python?px=new&city=%E5%85%A8%E5%9B%BD user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 """ headers_dict = string_util.headers_to_dict(headers) def get_data_from_cloud(page): params = { 'first': 'false', 'pn': page, 'kd': 'python' } s = requests.Session() # 创建一个session对象 s.get(home_url, headers=headers_dict, timeout=3) # 用 session 对象发出 get 请求,获取 cookie cookie = s.cookies response = requests.post(url, data=params, headers=headers_dict, cookies=cookie, timeout=3) result = response.text write_file(result) def get_data(): for i in range(76): page = i + 1 get_data_from_cloud(page) time.sleep(5)不出意外,这下可以就可以获得全部数据了,总共 1131 条。 数据清洗上文我们将获取到的 json 数据存储到了 data.txt 文件中,这不方便我们后续的数据分析操作。我们准备用 pandas 对数据做分析,所以需要做一下数据格式化。 处理过程不难,只是有点繁琐。具体过程如下: def get_data_from_file(): with open('data.txt') as f: data = [] for line in f.readlines(): result = json.loads(line) result_list = result['content']['positionResult']['result'] for item in result_list: dict = { 'city': item['city'], 'industryField': item['industryField'], 'education': item['education'], 'workYear': item['workYear'], 'salary': item['salary'], 'firstType': item['firstType'], 'secondType': item['secondType'], 'thirdType': item['thirdType'], # list 'skillLables': ','.join(item['skillLables']), 'companyLabelList': ','.join(item['companyLabelList']) } data.append(dict) return data data = get_data_from_file() data = pd.DataFrame(data) data.head(15)
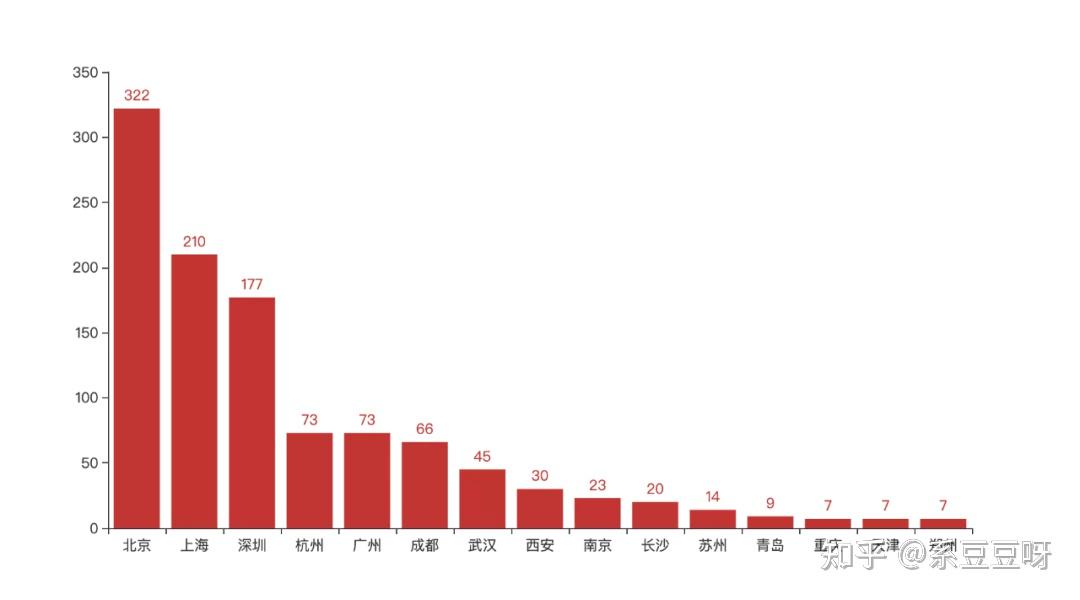
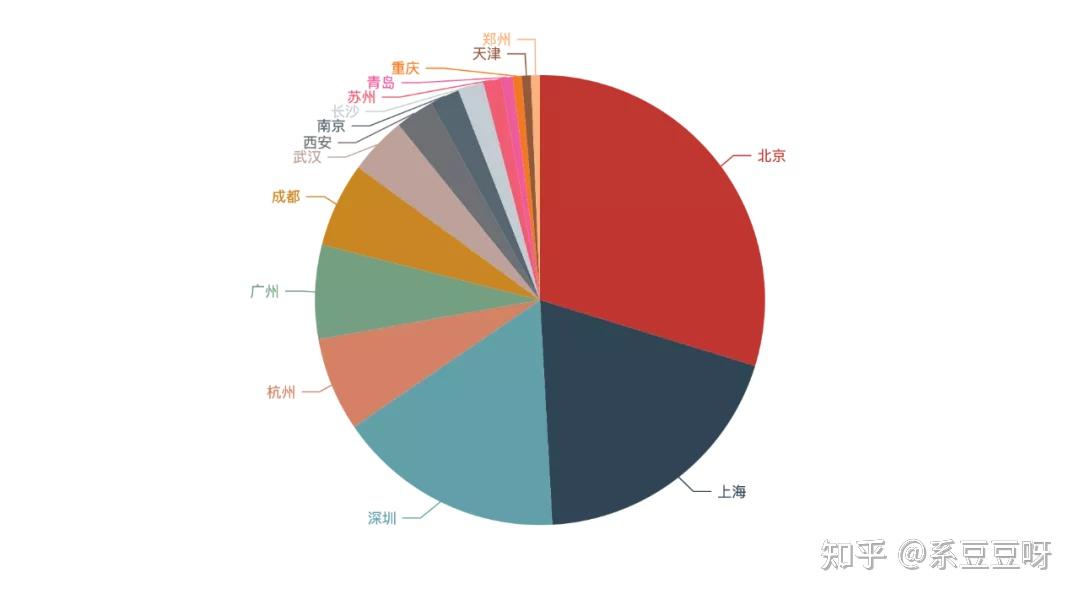
获取数据和清洗数据只是我们的手段,而不是目的,我们最终的目的是要通过获取到的招聘数据挖掘出招聘方的需求,以此为目标来不断完善自己的技能图谱。 城市先来看看哪些城市的招聘需求最大。这里我们只取 Top15 的城市数据。 top = 15 citys_value_counts = data['city'].value_counts() citys = list(citys_value_counts.head(top).index) city_counts = list(citys_value_counts.head(top)) bar = ( Bar() .add_xaxis(citys) .add_yaxis("", city_counts) ) bar.render_notebook()
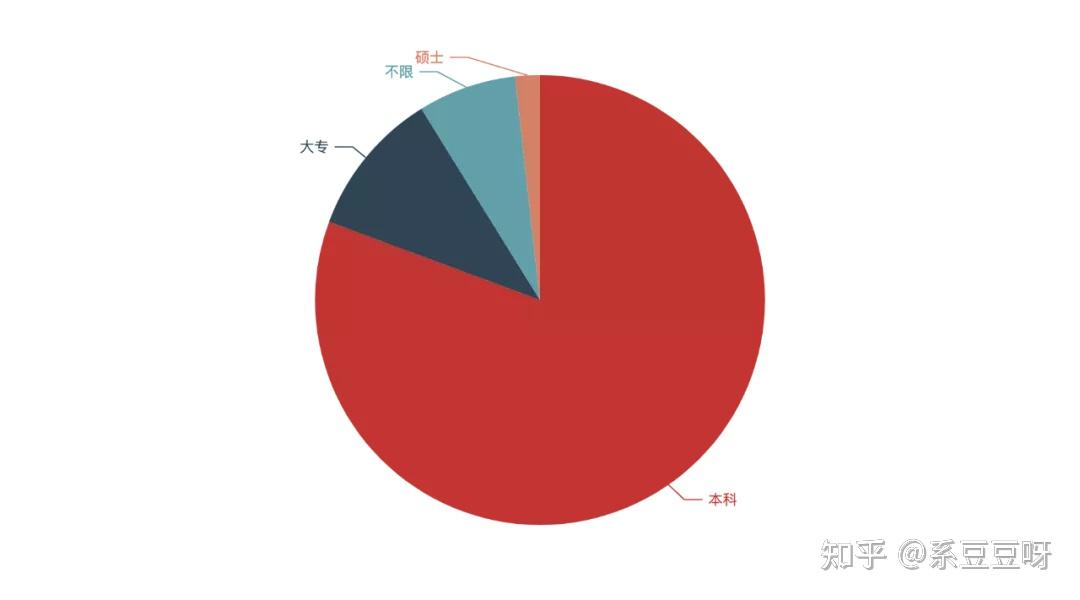
由上图可以看出,北京基本占据了四分之一还多的招聘量,其次是上海,深圳,杭州,单单从需求量来说,四个一线城市中广州被杭州所代替。 这也就从侧面说明了我们为啥要去一线城市发展了。 学历 eduction_value_counts = data['education'].value_counts() eduction = list(eduction_value_counts.index) eduction_counts = list(eduction_value_counts) pie = ( Pie() .add("", [list(z) for z in zip(eduction, eduction_counts)]) .set_global_opts(title_opts=opts.TitleOpts(title="")) .set_global_opts(legend_opts=opts.LegendOpts(is_show=False)) ) pie.render_notebook()
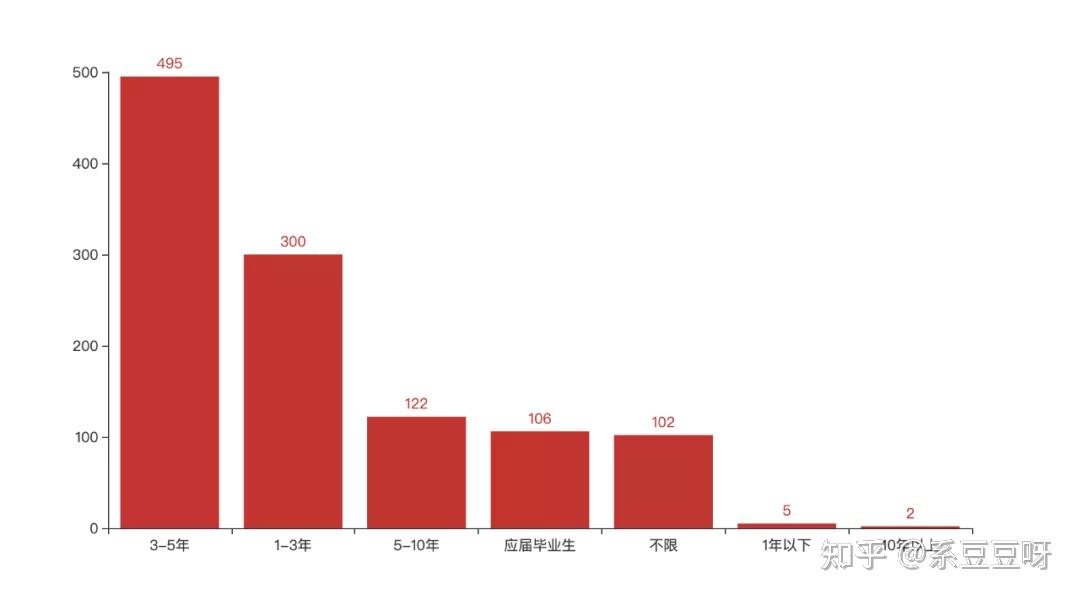
看来大多公司的要求都是至少要本科毕业的,不得不说,当今社会本科基本上已经成为找工作的最低要求了(能力特别强的除外)。 工作年限 work_year_value_counts = data['workYear'].value_counts() work_year = list(work_year_value_counts.index) work_year_counts = list(work_year_value_counts) bar = ( Bar() .add_xaxis(work_year) .add_yaxis("", work_year_counts) ) bar.render_notebook()
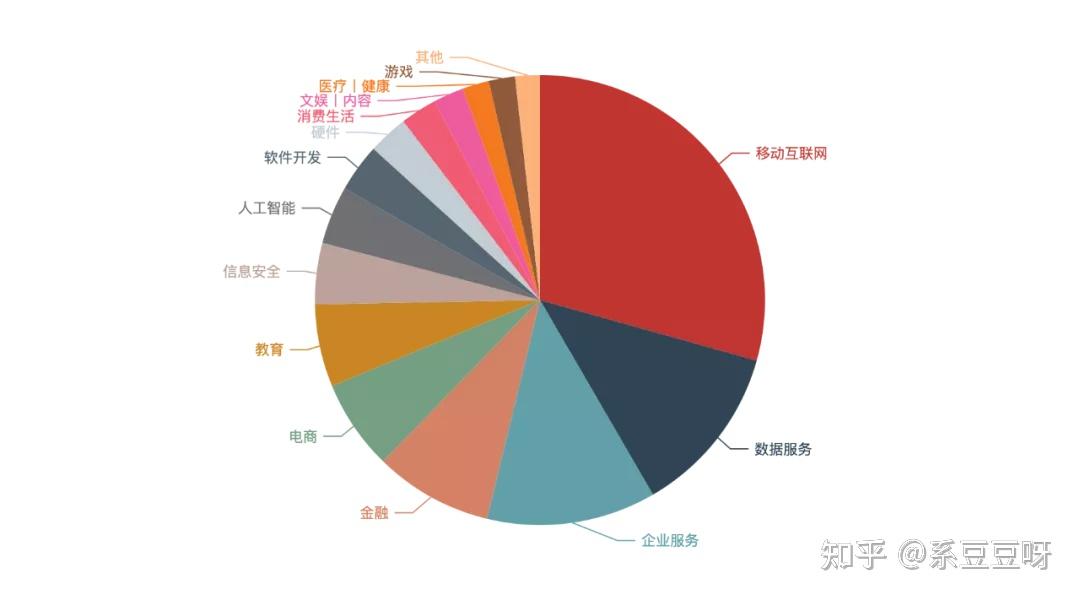
3-5年的中级工程师需求最多,其次是 1-3 年的初级工程师。其实这也是符合市场规律的,这是因为高级工程师换工作频率远远低于初中级,且一个公司对高级工程师的需求量是远远低于初中级工程师的。 行业我们再来看看这些招聘方都属于哪些行业。因为行业数据不是非常规整,所以需要单独对每一条记录按照 , 作下切割。 industrys = list(data['industryField']) industry_list = [i for item in industrys for i in item.split(',') ] industry_series = pd.Series(data=industry_list) industry_value_counts = industry_series.value_counts() industrys = list(industry_value_counts.head(top).index) industry_counts = list(industry_value_counts.head(top)) pie = ( Pie() .add("", [list(z) for z in zip(industrys, industry_counts)]) .set_global_opts(title_opts=opts.TitleOpts(title="")) .set_global_opts(legend_opts=opts.LegendOpts(is_show=False)) ) pie.render_notebook()
移动互联网行业占据了四分之一还多的需求量,这跟我们的认识的大环境是相符合的。 技能要求来看看招聘方所需的技能要求词云。 word_data = data['skillLables'].str.split(',').apply(pd.Series) word_data = word_data.replace(np.nan, '') text = word_data.to_string(header=False, index=False) wc = WordCloud(font_path='/System/Library/Fonts/PingFang.ttc', background_color="white", scale=2.5, contour_color="lightblue", ).generate(text) wordcloud = WordCloud(background_color='white', scale=1.5).generate(text) plt.figure(figsize=(16, 9)) plt.imshow(wc) plt.axis('off') plt.show()
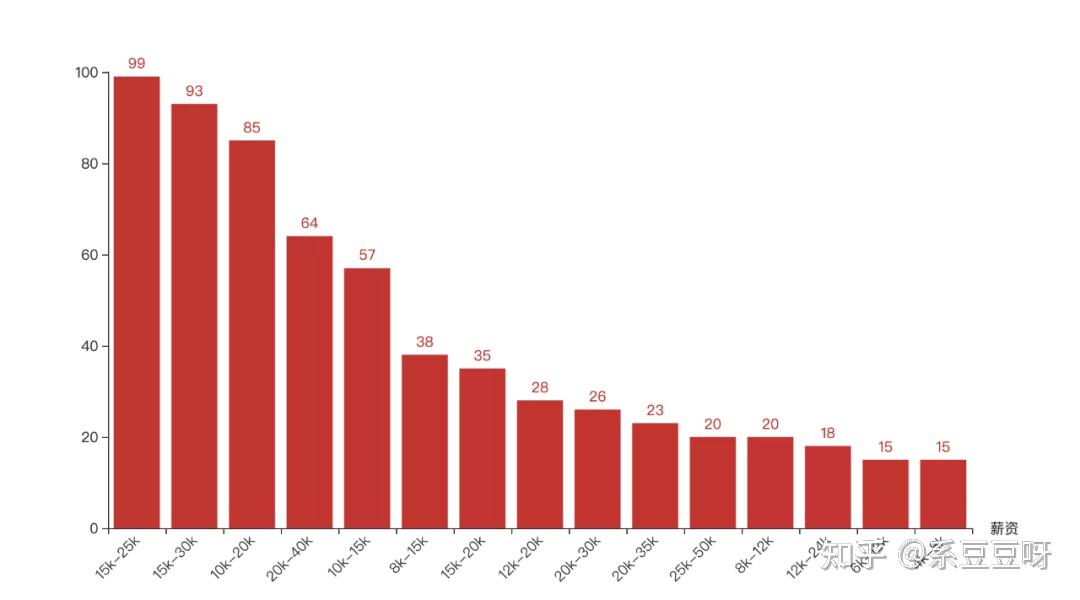
除去 Python,出现最多的是后端、MySQL、爬虫、全栈、算法等。 薪资接下来我们看看各大公司给出的薪资条件。 salary_value_counts = data['salary'].value_counts() top = 15 salary = list(salary_value_counts.head(top).index) salary_counts = list(salary_value_counts.head(top)) bar = ( Bar() .add_xaxis(salary) .add_yaxis("", salary_counts) .set_global_opts(xaxis_opts=opts.AxisOpts(name_rotate=0,name="薪资",axislabel_opts={"rotate":45})) ) bar.render_notebook()
大部分公司给出的薪资还是很可观的,基本都在 20K-35K 之间,只要你技术过关,很难找不到满意薪酬的工作。 福利最后咱来看看公司给出的额外福利都有哪些。 word_data = data['companyLabelList'].str.split(',').apply(pd.Series) word_data = word_data.replace(np.nan, '') text = word_data.to_string(header=False, index=False) wc = WordCloud(font_path='/System/Library/Fonts/PingFang.ttc', background_color="white", scale=2.5, contour_color="lightblue", ).generate(text) plt.figure(figsize=(16, 9)) plt.imshow(wc) plt.axis('off') plt.show()
年底双薪、绩效奖金、扁平化管理。都是大家所熟知的福利,其中扁平化管理是互联网公司的特色。不像国企或者其他实体企业,上下级观念比较重。 以上就是“自学 Python 到什么程度能找到工作,1300+ 条招聘信息告诉你答案”的全部内容,希望对你有所帮助。 关于Python技术储备 学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助! 一、Python所有方向的学习路线 Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
三、Python视频合集 观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例 光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题 检查学习结果。
六、面试资料 我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
最后祝大家天天进步!! 上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。 |









【本文地址】
今日新闻 |
推荐新闻 |