【python】文本处理 |
您所在的位置:网站首页 › 网页提取文字怎么弄 › 【python】文本处理 |
【python】文本处理
|
1.简单爬取网页
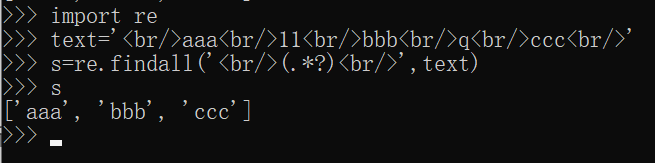
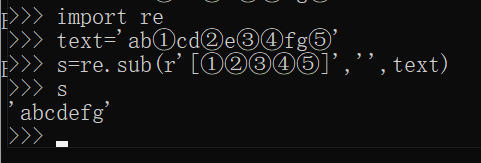
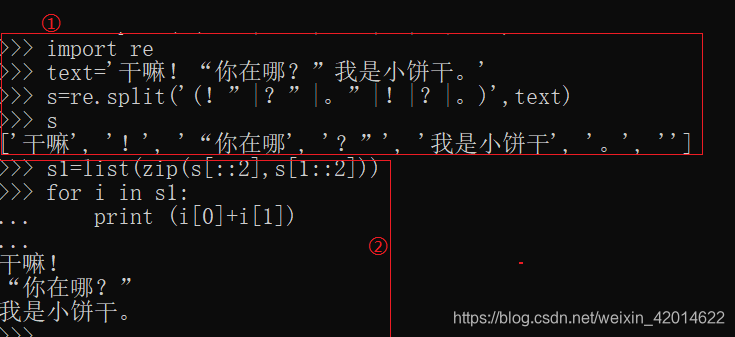
这里以爬取易文言的《二十五史》为例,共有176篇。http://ewenyan.com/contents/more/esws.html 注: 若爬取时出现编码错误,可以先查看网页的编码方式(鼠标右键–查看源文件),如下图所示。 这里的编码方式是gb2312,代码中对应改为了GBK。 由于1中的结果包含了所有的网页信息,而我需要的只是其中的文字部分,所以需要把代码部分以及多余的信息删除。 这里用到了replace()、findall()、sub()函数 (1)findall()函数findall()函数可以用正则表达式去找到你需要的文本信息,直接提取出来。如图所示。 replace()函数可以同时替换不同的字符。如图所示,把空格替换为无,“!”替换为“?”,把“111”替换为“0”。 若我们想把很多个不同的字符替换为同一个字符,那我们就可以使用sub()函数。 例如,在文本中可能会出现很多带标号①②③…的注释,我们需要把它们删除,那我就把这些注释标号都替换为空,如下图所示。 在2中删除完多余的信息后,需要对文本分句。这里以(!”|?”|。”|。|?|!)进行分句。如下图所示。 框①中对文本句子进行切分,框②对切分的内容组合(句子+标点) |
 代码如下:
代码如下: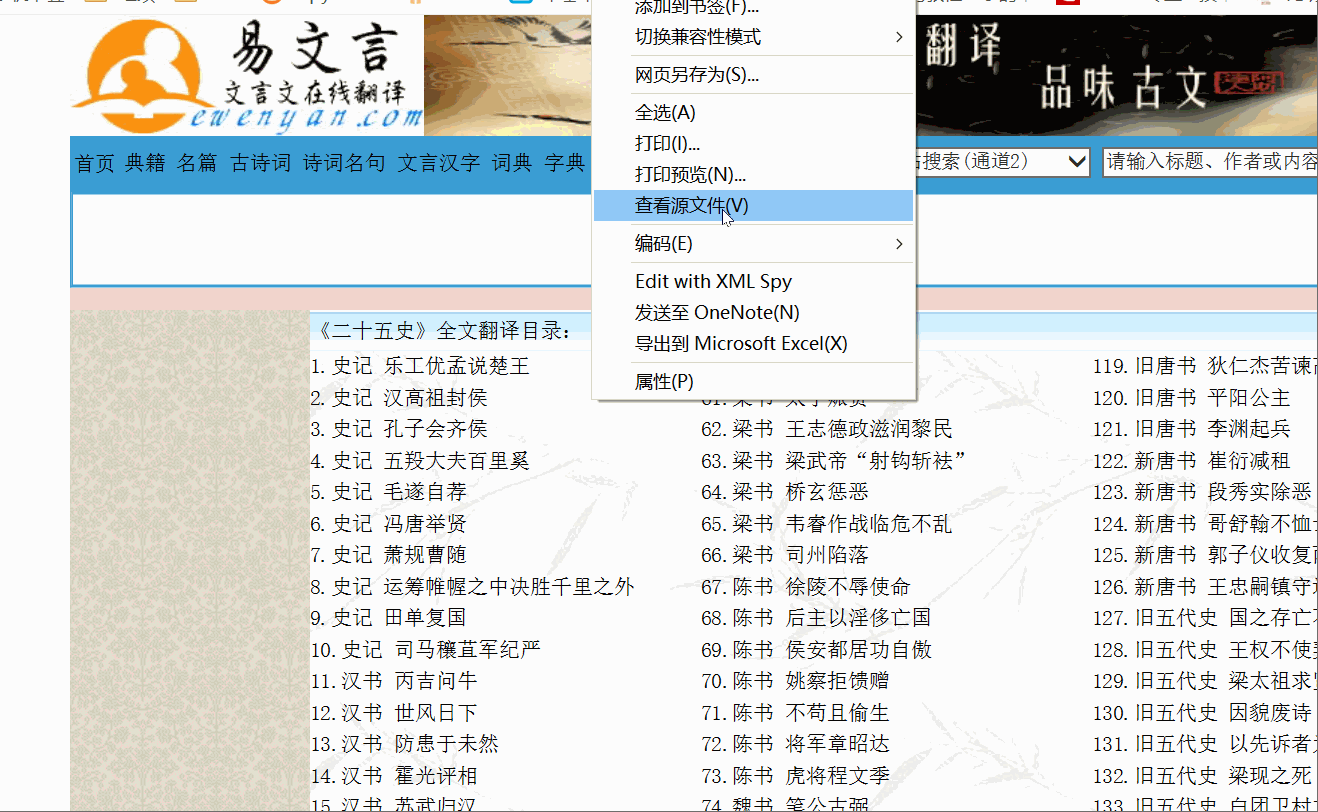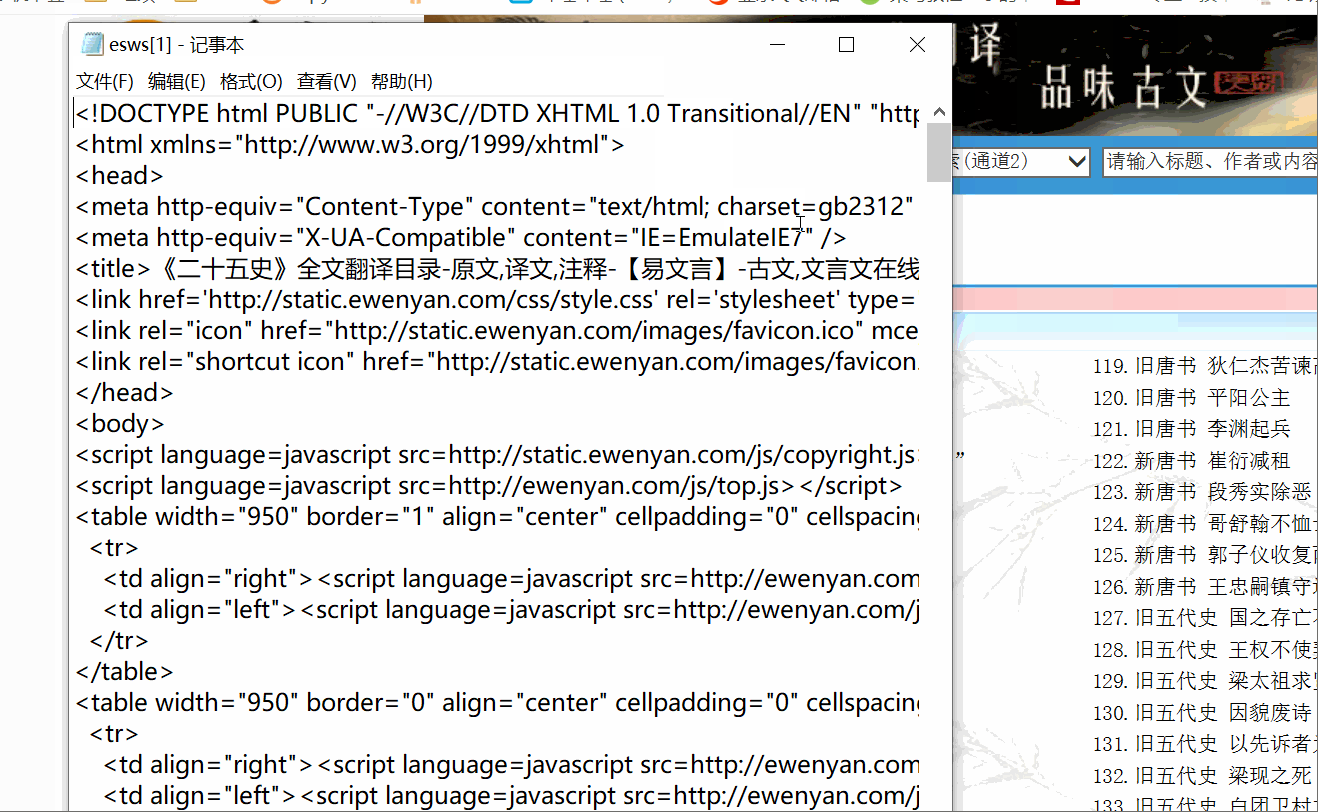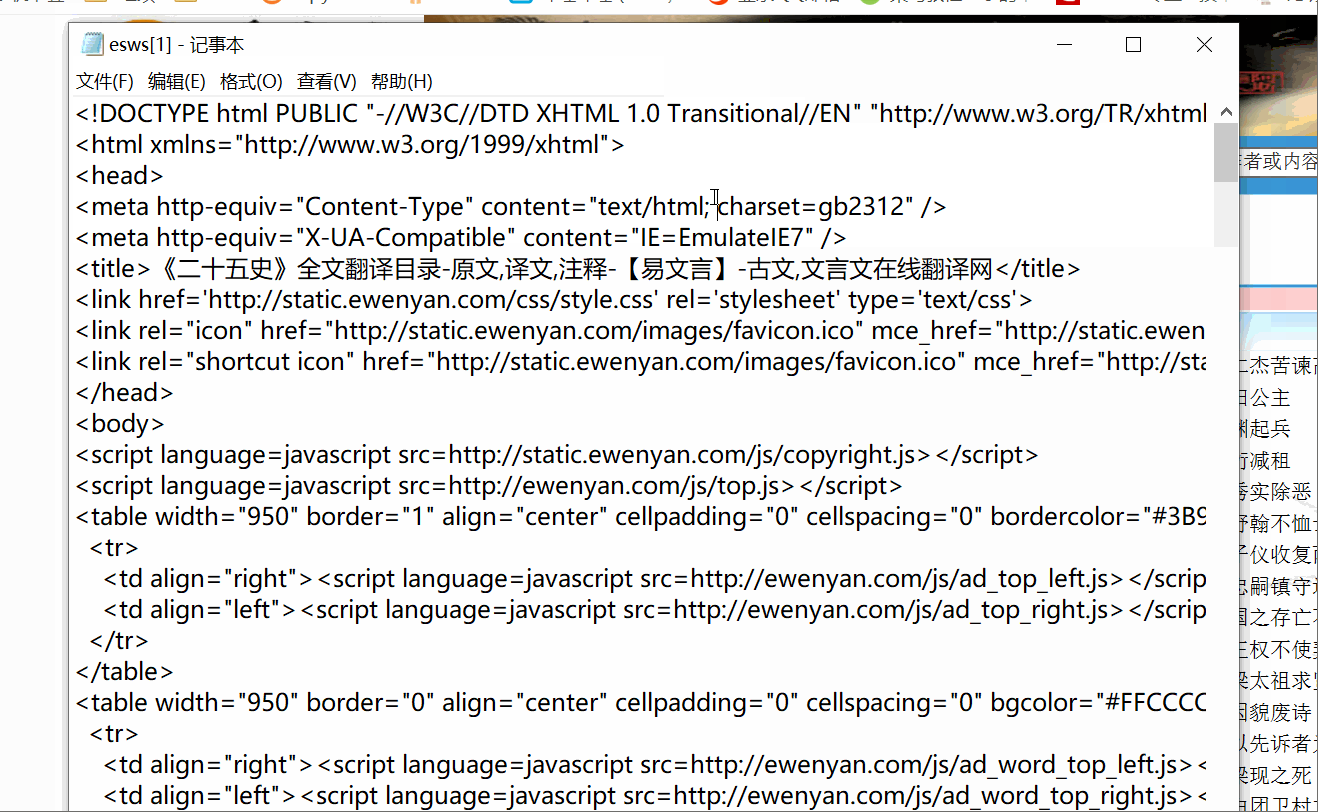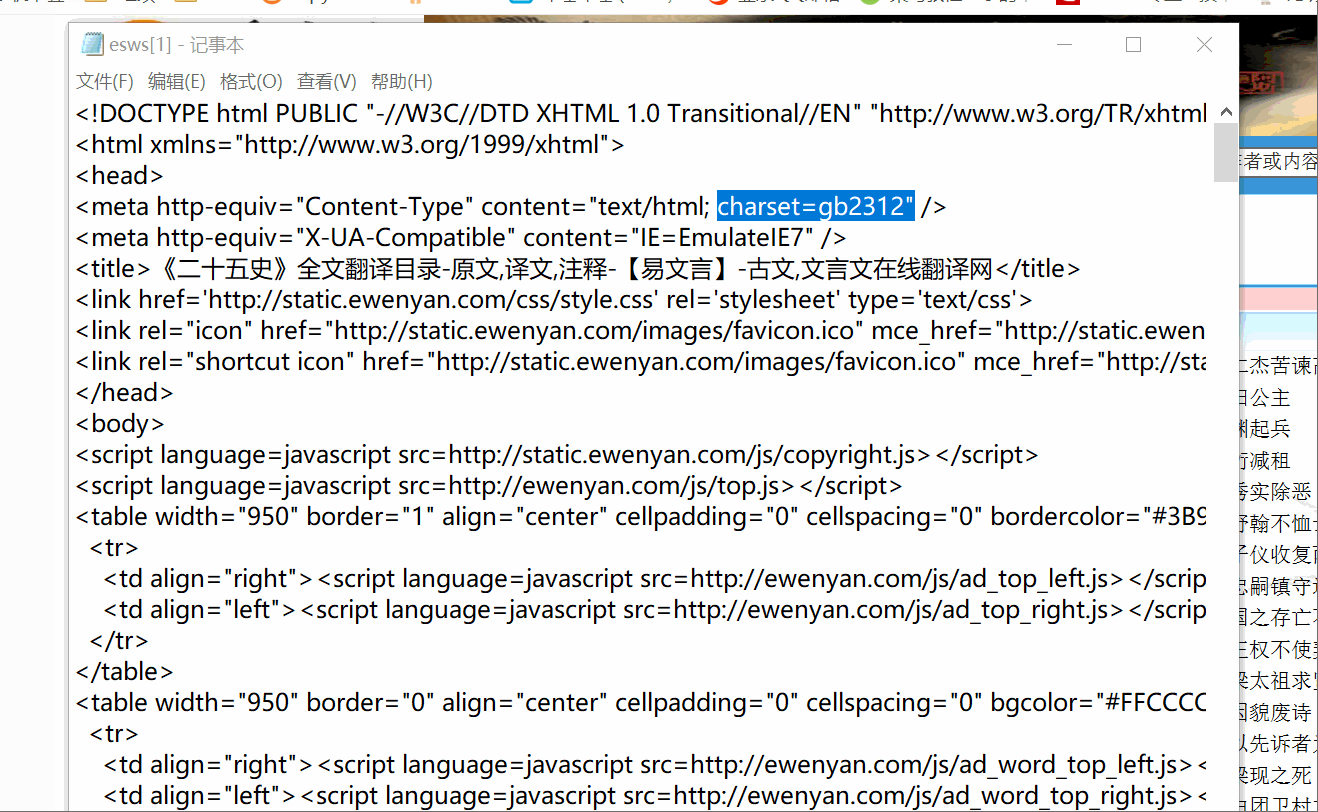 结果如下:
结果如下: 

 最终的文本如下所示。
最终的文本如下所示。 
【本文地址】
今日新闻 |
推荐新闻 |